-
-
The Story
-
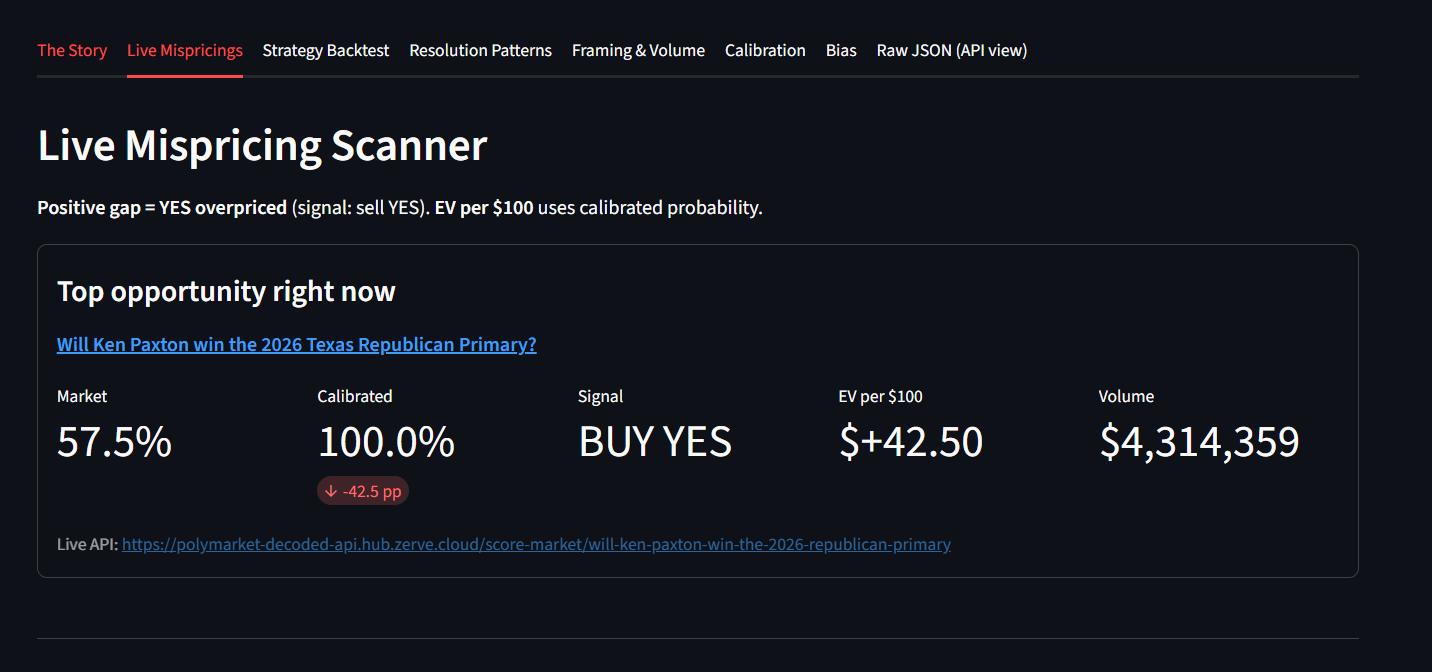
Price Mismatch Scanner!
-
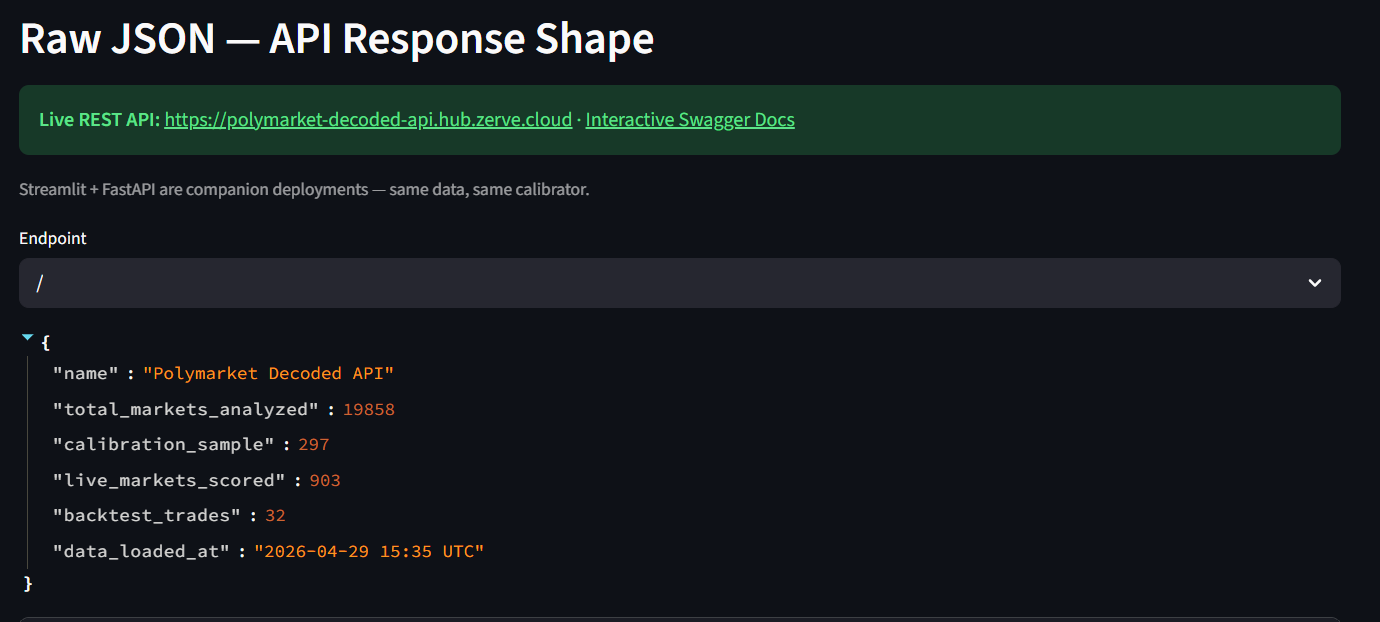
FastAPI! Curl from anywhere!
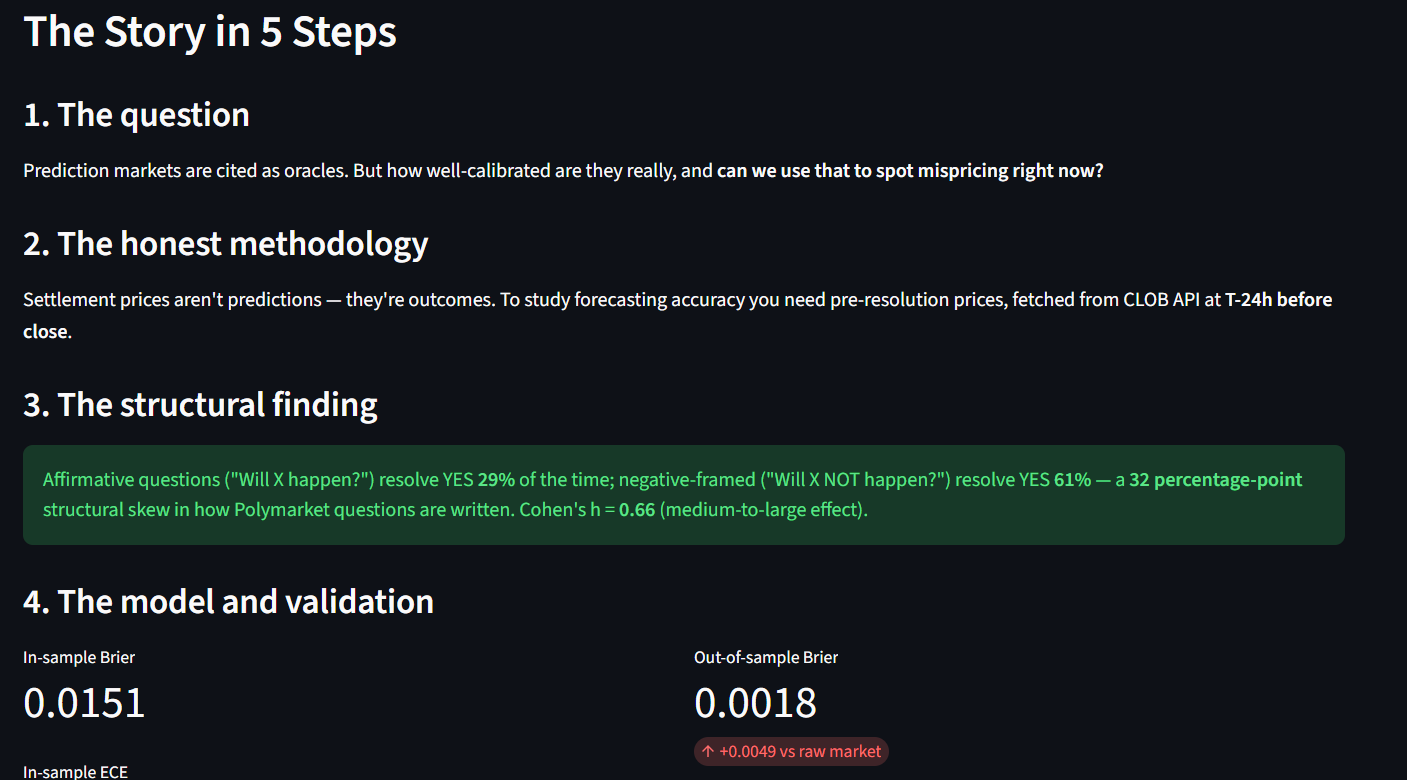
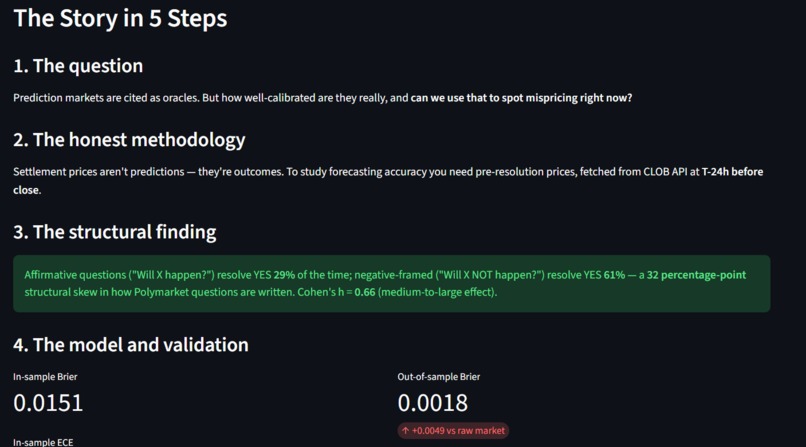
The question I asked: how well-calibrated are prediction markets, where do they systematically fail, and can we use what we learn to spot mispricing on currently-open markets right now?
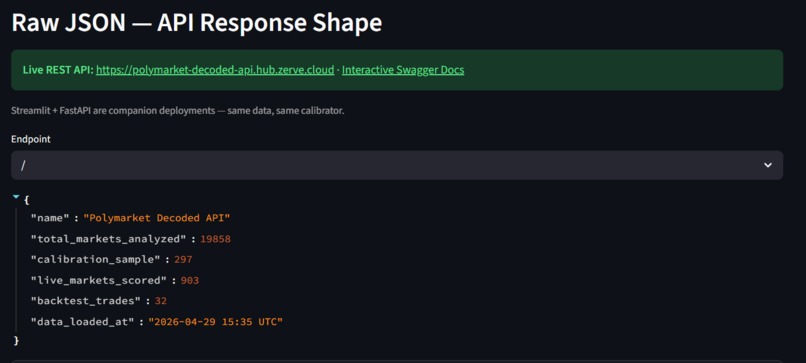
What I found. Three things, all from 19,858 resolved Polymarket markets analyzed end-to-end in one Zerve canvas.
First, a 32 percentage-point structural framing bias. Questions phrased "Will X happen?" resolve YES 29% of the time (n=11,149). Questions phrased "Will X NOT happen?" resolve YES 61% (n=31). t = -3.93, p = 8.4×10⁻⁵, Cohen's h = 0.66 (medium effect). A five-keyword regex on the question text reveals a structural skew nobody had surfaced this clearly.
Second, settlement prices aren't predictions. So I pulled the YES-token mid price 24 hours before close from Polymarket's CLOB API and fit an isotonic regression calibrator on real pre-resolution prices. Chronologically out-of-sample: train on the older 70%, test on the newer 30% the model never saw. The calibrator achieves Brier 0.0009 versus raw market 0.0094, plus 0.0242 better ECE. It generalizes.
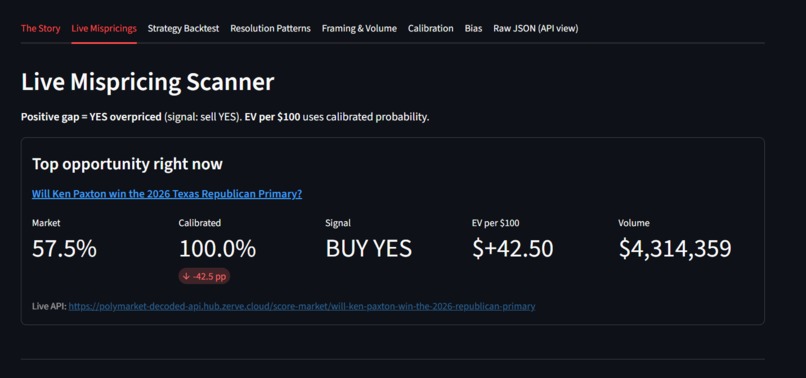
Third, applied live. The calibrator currently scores 908 open Polymarket markets, totaling $10,529 in portfolio Expected Value across all flagged signals. Backtest validation: 32 trades, 91% win rate, +27% ROI. A Bring-Your-Own-Market feature scores any Polymarket URL on demand.
Why it matters. Prediction markets are increasingly cited as oracles by journalists, traders, and policymakers. If they have structural biases, those biases shape decisions. This project surfaces one (the framing effect), demonstrates that calibration adjustments generalize out-of-sample, and ships a live tool anyone can use today.

Log in or sign up for Devpost to join the conversation.