
PolyDub: Building Real-Time Multilingual Dubbing for Human Conversation
Vision
PolyDub started from a simple observation: communication tools are instant, but understanding is still delayed by language. Captions and transcripts help, but they do not feel like natural conversation.
The goal was to make multilingual communication feel immediate and human: one person speaks in their native language, and others hear them in theirs with minimal delay, directly in the browser.
What PolyDub Does
PolyDub is a multilingual communication platform with three experiences:
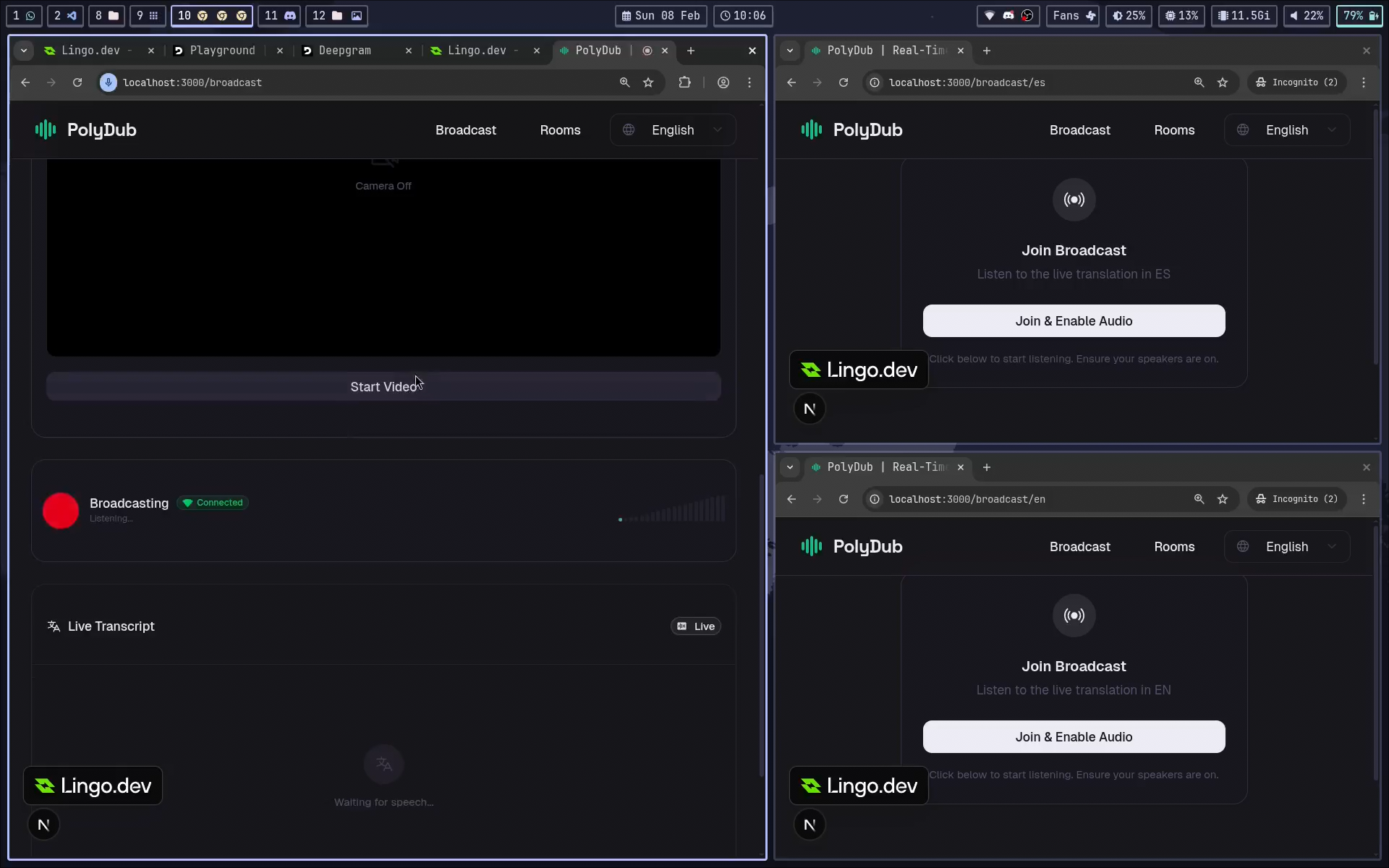
Live Broadcast
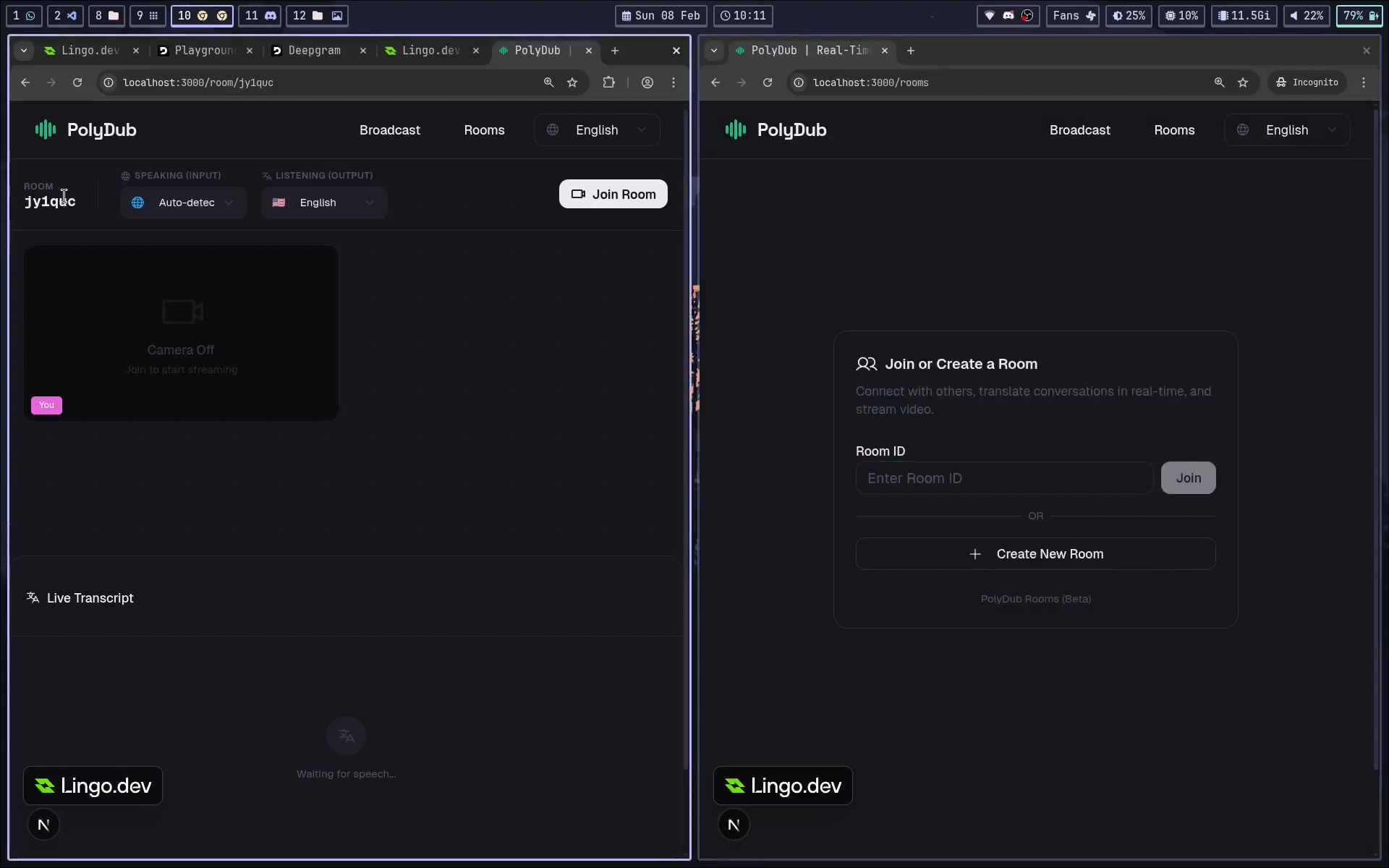
One speaker streams to many listeners, each receiving dubbed audio in their preferred language.Multilingual Rooms
Multiple participants speak different languages in one shared room and hear translated speech targeted to their own settings.VOD (Video on Demand) Dubbing
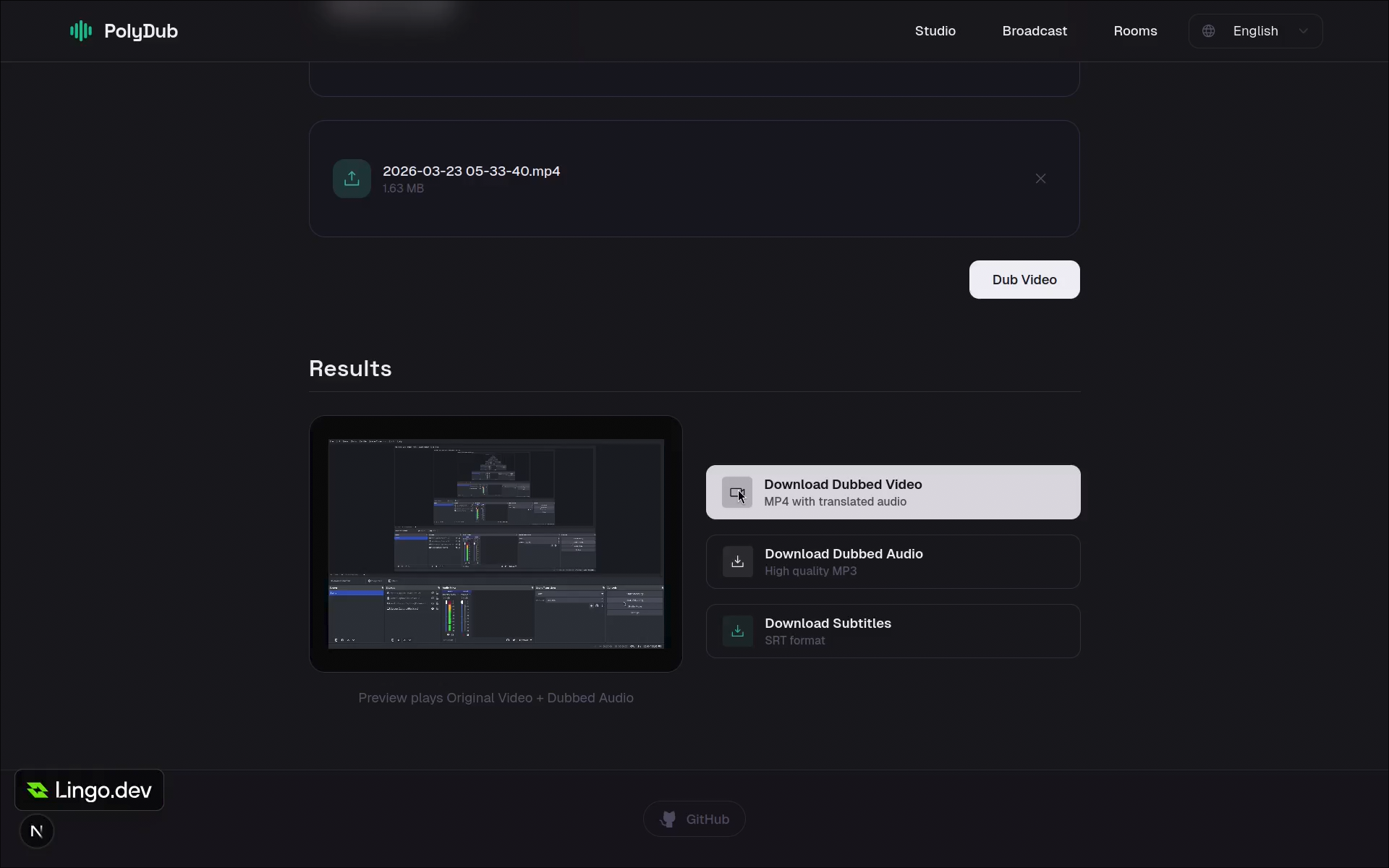
Users upload recorded video and receive dubbed output with subtitles for asynchronous distribution.
Product Principles
- Conversation first: translation should support dialogue, not interrupt it.
- Low friction: no plugins or complex setup.
- Reliability under real usage: reconnects, errors, and noisy conditions are first-class concerns.
- End-to-end consistency: capture, STT, translation, TTS, transport, and playback must work as one system.
Architecture
PolyDub runs as two coordinated services:
- Web app layer for UI and API workflows.
- Persistent real-time layer (WebSocket server) for long-lived audio sessions, room state, and stream routing.
This split is important because real-time multilingual audio is stateful and continuous, while page rendering and REST APIs are request-based.
Real-Time Pipeline
- Browser microphone capture
- Audio chunk transport over WebSocket
- Streaming speech-to-text
- Translation to target language(s)
- Text-to-speech synthesis
- Streamed playback on listener side
A simple latency budget model:
$$ L_{total}=L_{capture}+L_{transport}+L_{stt}+L_{translate}+L_{tts}+L_{playback} $$
The practical goal is reducing variance, not just average latency. Users feel unstable timing more than small constant delay.
Concurrency and Queue Stability
In multilingual rooms, simultaneous speakers create synthesis contention.
A simplified queue model is:
$$ Q_{t+1}=\max(0,\;Q_t+\lambda_t-\mu_t) $$
Where:
- λₜ = incoming synthesis demand
- μₜ = processing + playback capacity
Keeping Qₜ bounded is key to avoiding overlapping playback and preserving intelligibility.
Build Journey
Baseline speech loop
Validated single-language capture, transport, and playback behavior.Translation in the loop
Added language routing and listener-specific output.Multi-user room behavior
Added room state, participant routing, and stream isolation.VOD pipeline
Added asynchronous segment dubbing plus subtitle generation.Hardening and testing
Improved edge-case handling, API consistency, and regressions across live + async flows.
Challenges Faced
Latency vs quality trade-offs
Better model quality can increase delay; tuning for conversational feel was critical.Multi-speaker contention
Concurrent speakers can create chaotic output without careful scheduling.Dependency failure handling
STT, translation, and TTS each have independent failure modes and needed robust fallbacks.Browser audio constraints
Autoplay and device-specific behavior impacted playback reliability.Real-time state correctness
Join/leave, reconnect, and socket synchronization had to remain accurate under churn.
What I Learned
- Reliability beats novelty in real-time communication.
- System performance is end-to-end, not a single-model metric.
- UX quality depends on infrastructure quality.
- Realistic E2E testing is essential for streaming products.
Use Cases
- Global live events and communities
- Multilingual team collaboration
- International education sessions
- Creator localization workflows
- Cross-border demos and support calls
What’s Next
- Speaker-aware voice continuity across long sessions
- Adaptive buffering and dynamic latency control
- Stronger quality metrics beyond raw latency
- Better subtitle and accessibility workflows
- Deeper observability across pipeline stages
Closing
PolyDub became more than a translation feature; it became a real-time communication systems project.
The biggest takeaway: multilingual communication is not only a language problem, it is also an experience design, distributed systems, and trust problem.
Built With
- deepgram-sdk-(stt-+-aura-tts)
- ffmpeg
- fluent-ffmpeg
- lingo-compiler
- lingo.dev-sdk
- next.js-16-(app-router)
- node.js
- pnpm
- radix-ui
- react-19
- react-hook-form
- tailwind-css-4
- typescript
- vercel-analytics
- websockets-(ws)
- zod

Log in or sign up for Devpost to join the conversation.