-
-
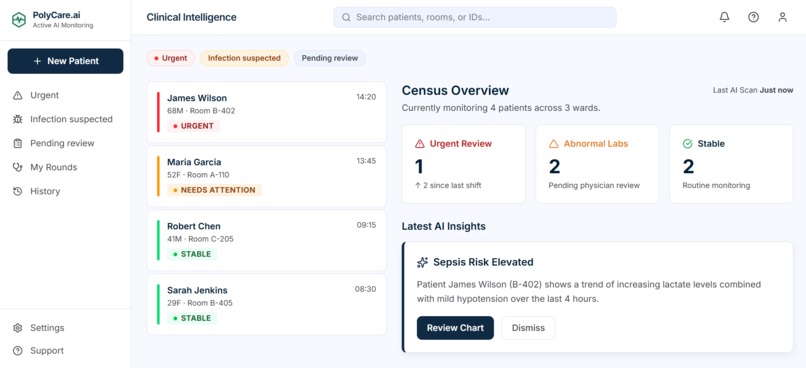
Dashboard
-
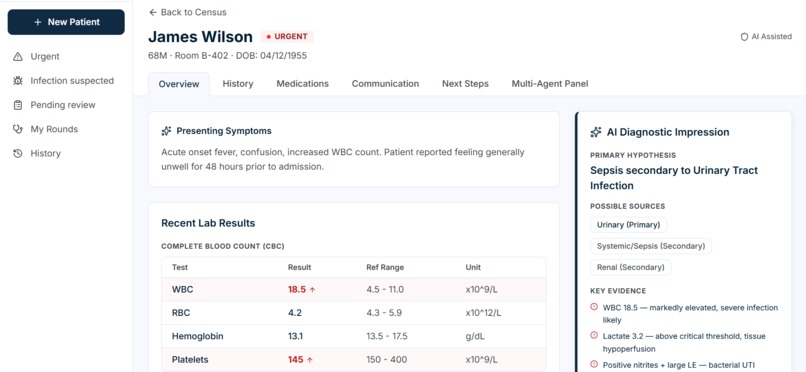
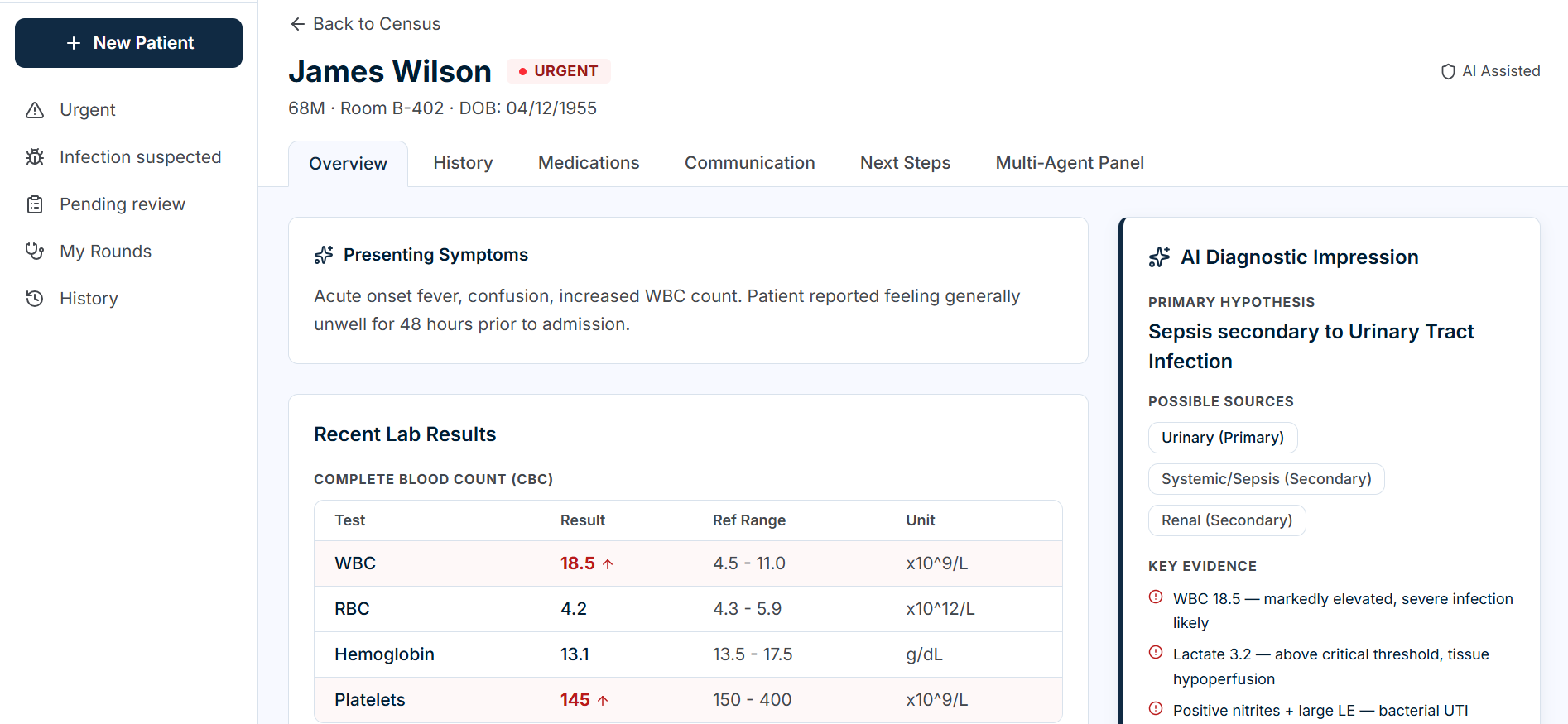
Patient Overview
-
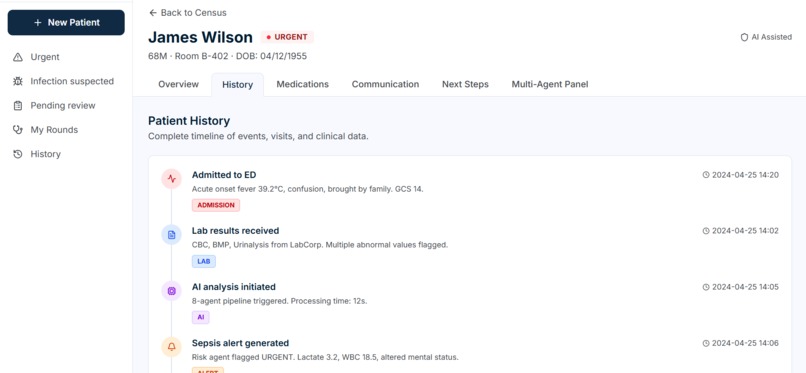
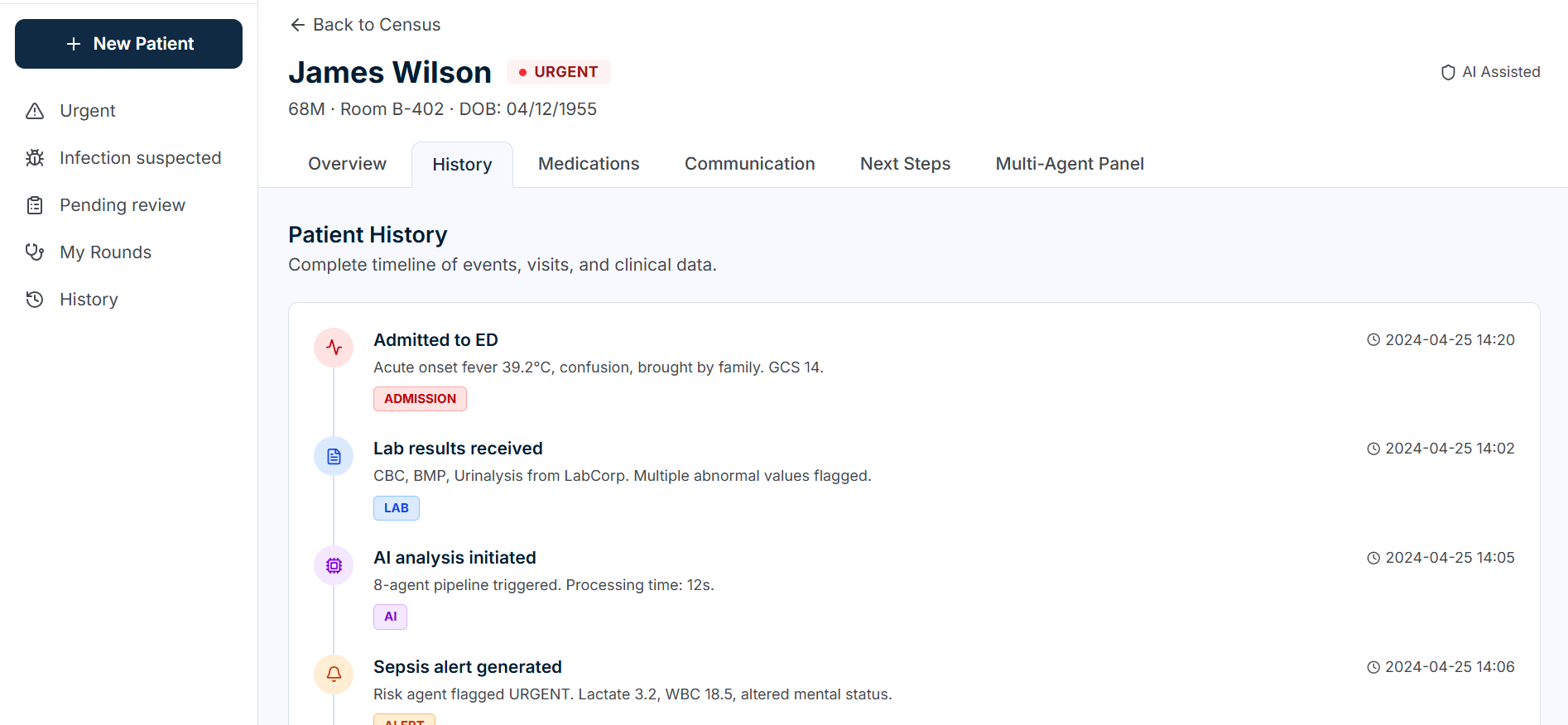
Patient History
-
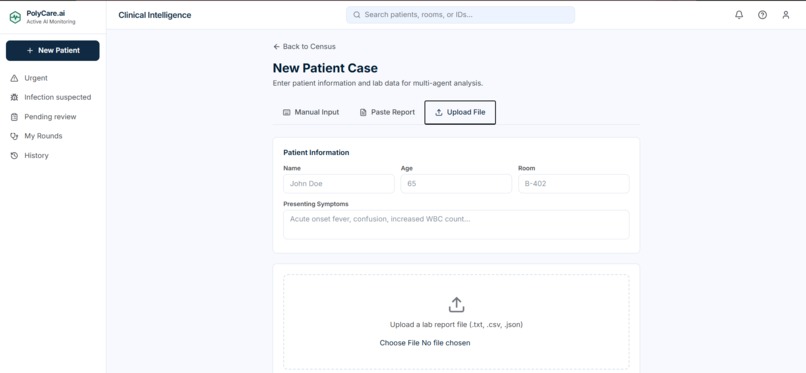
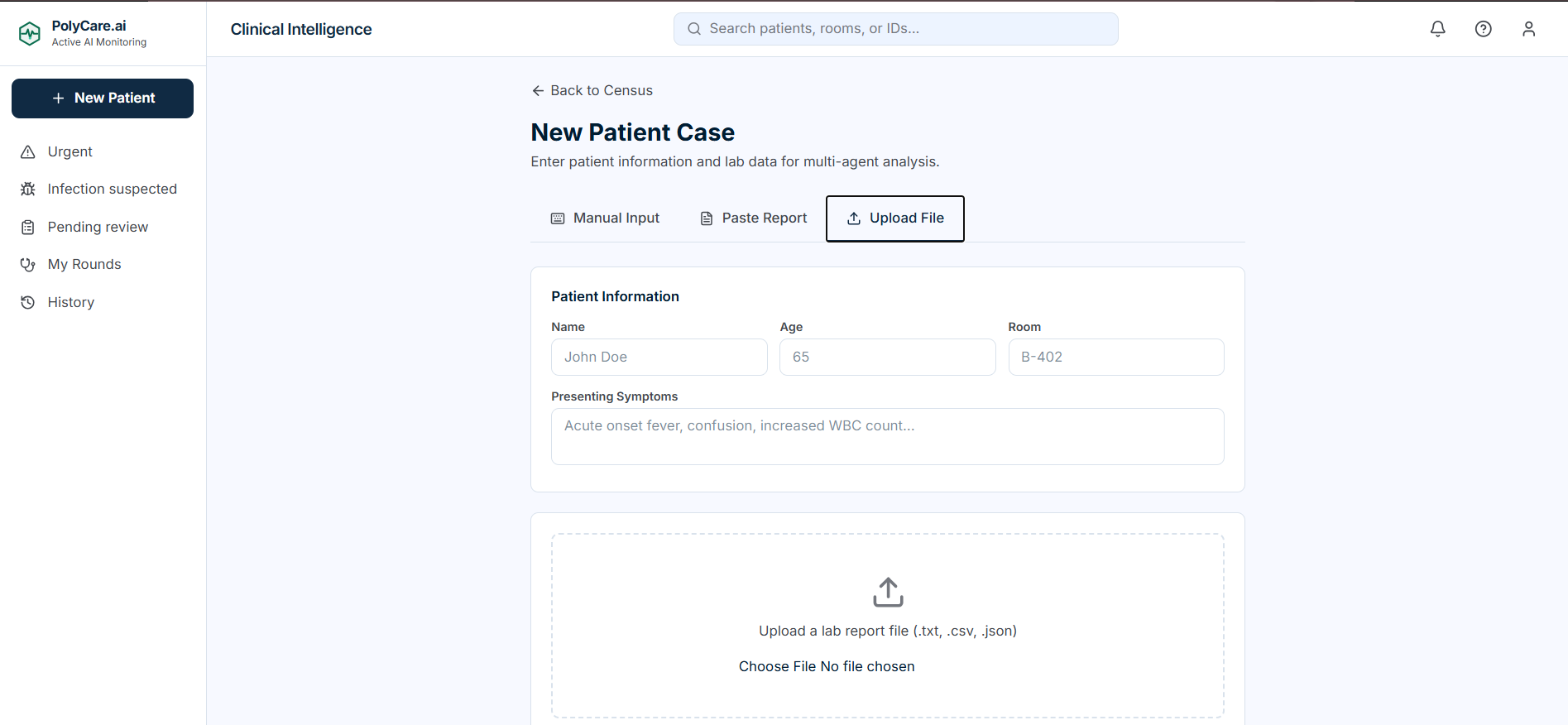
New Patient Case
-
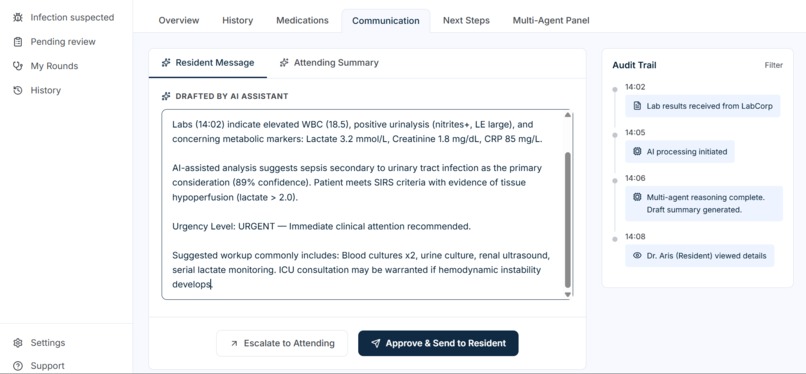
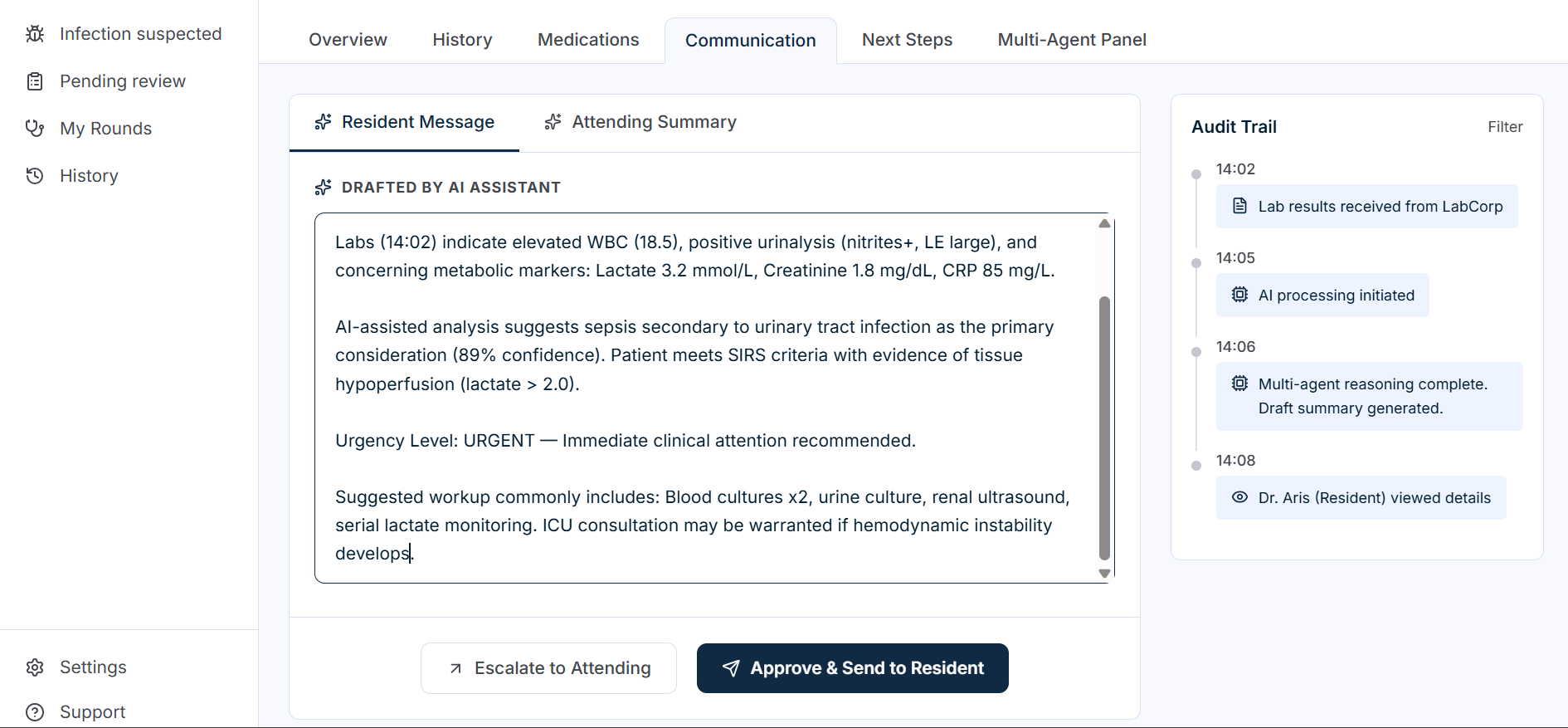
Resident Communication
-
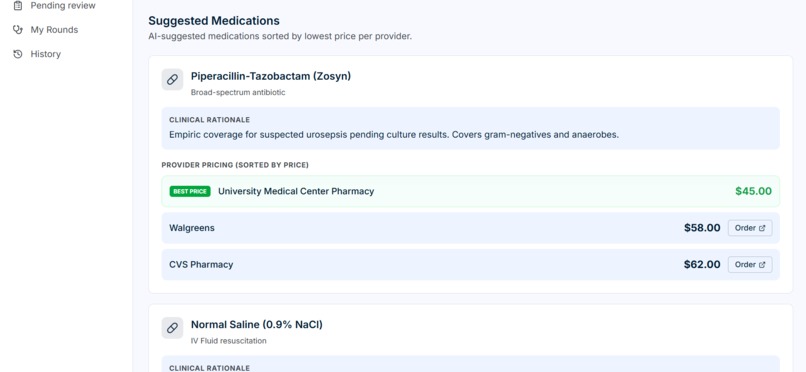
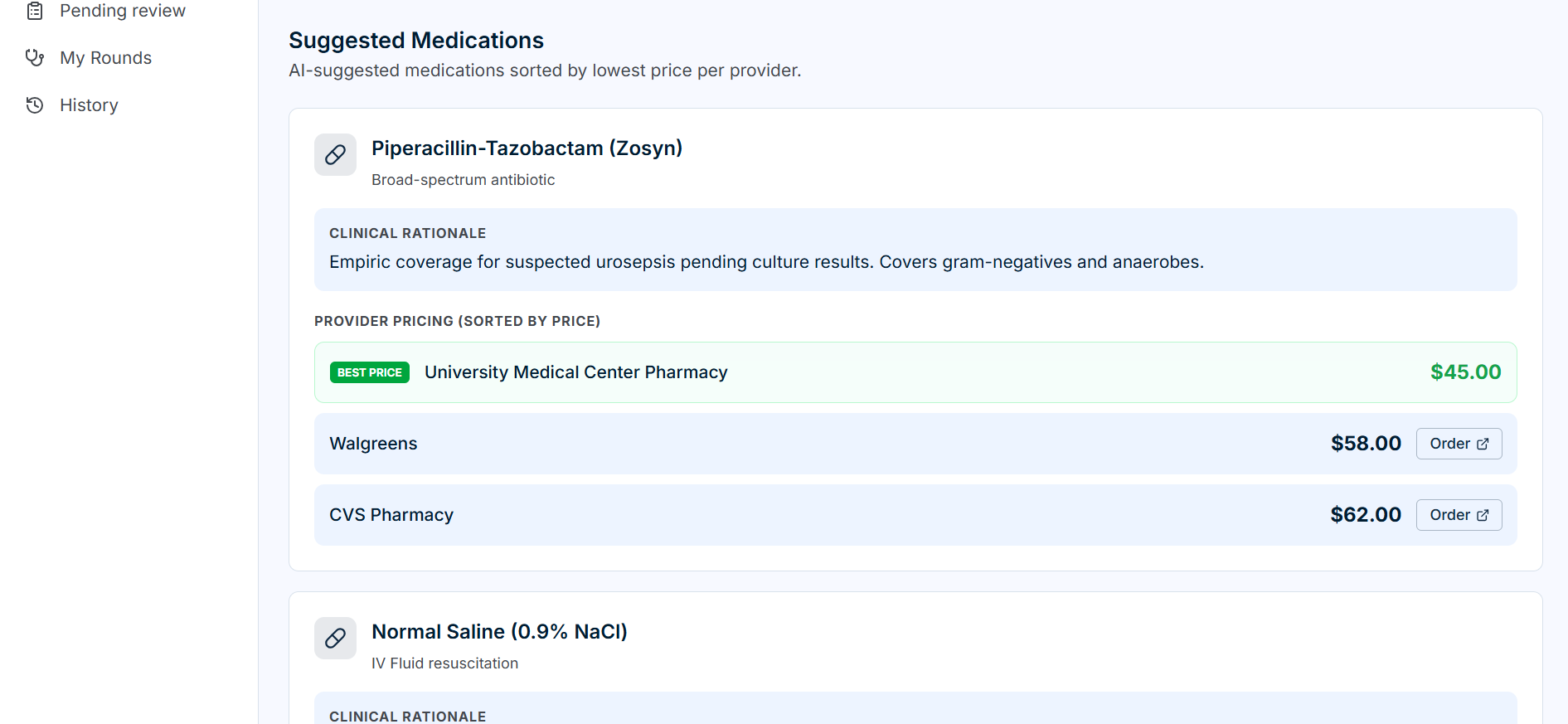
Medications suggestions
-
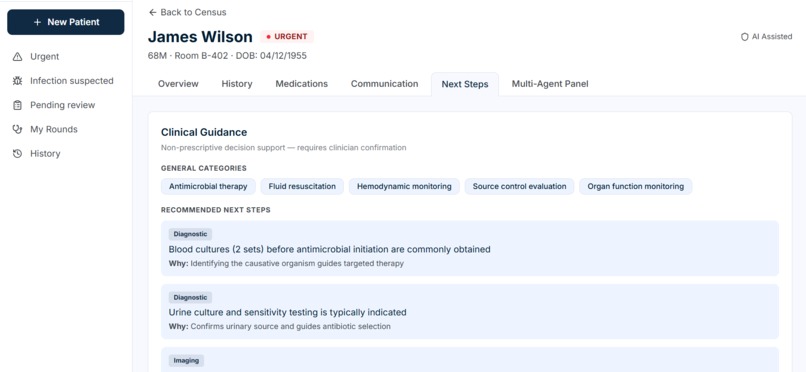
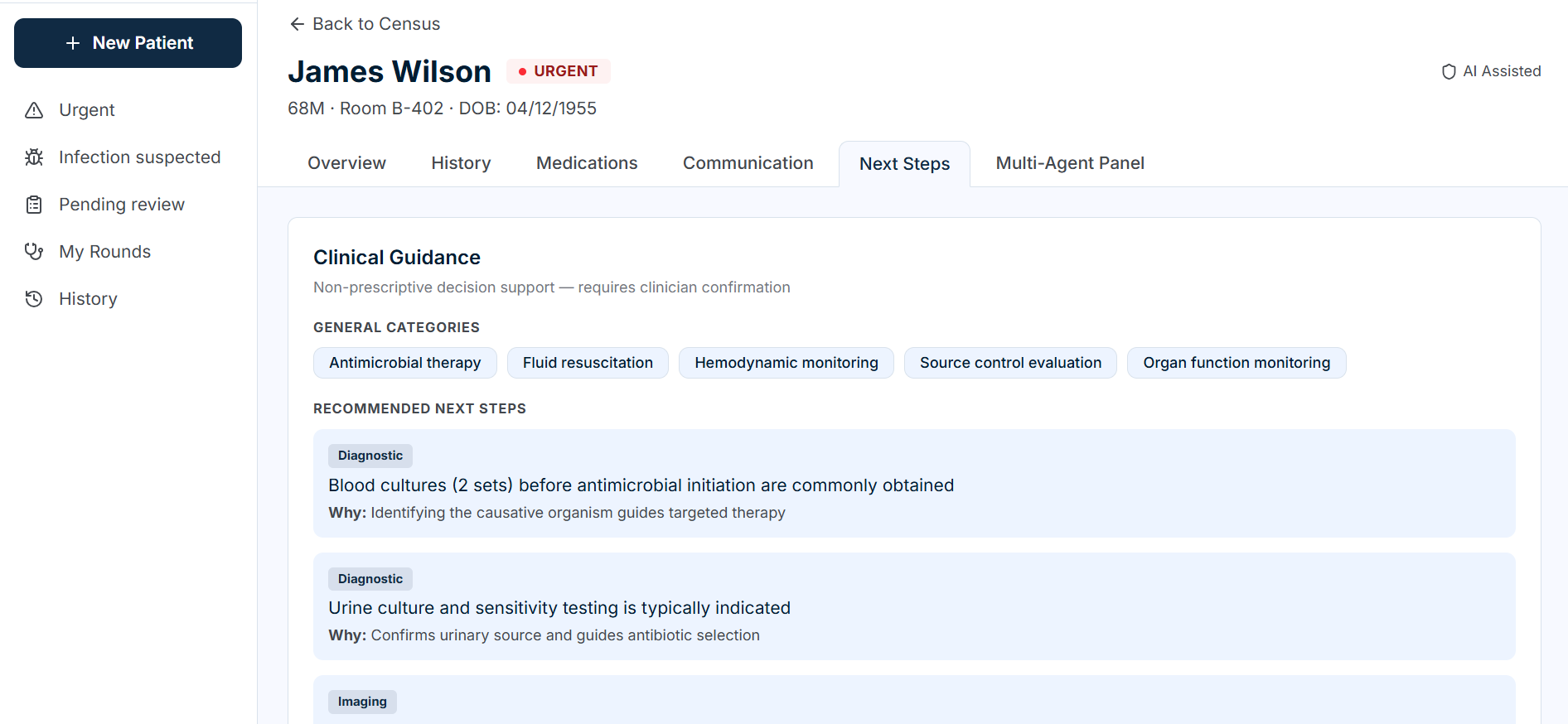
Next steps
-
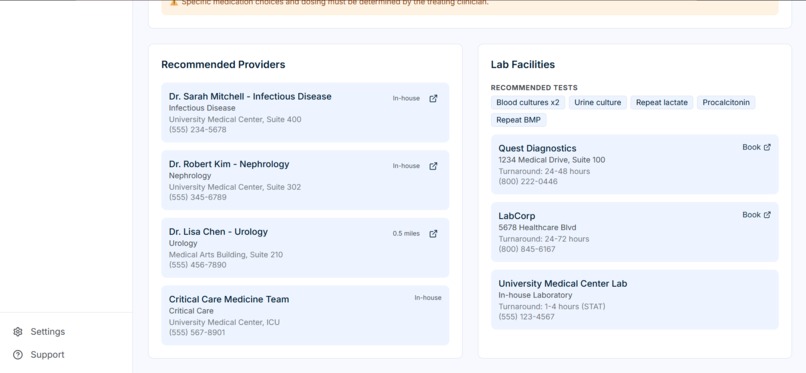
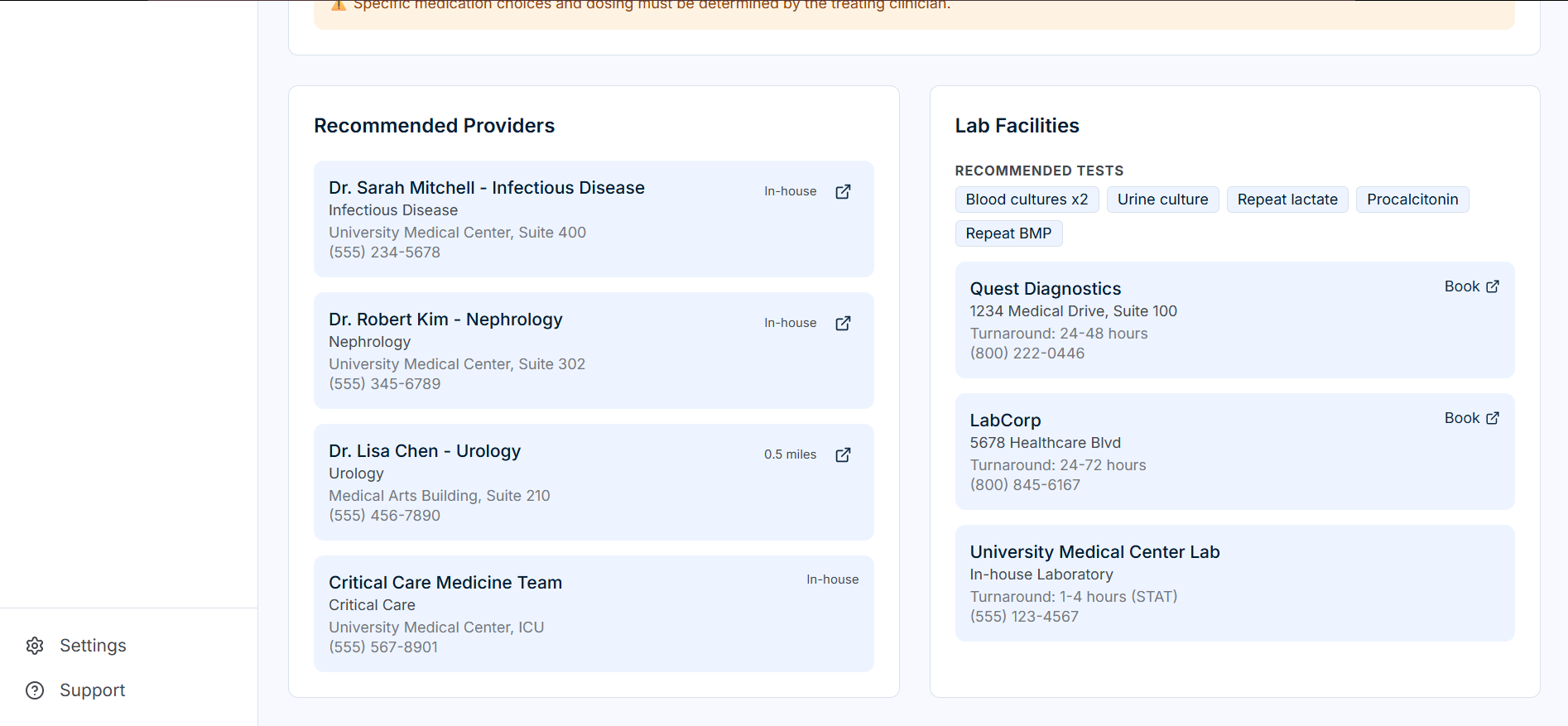
Recommended Providers
-
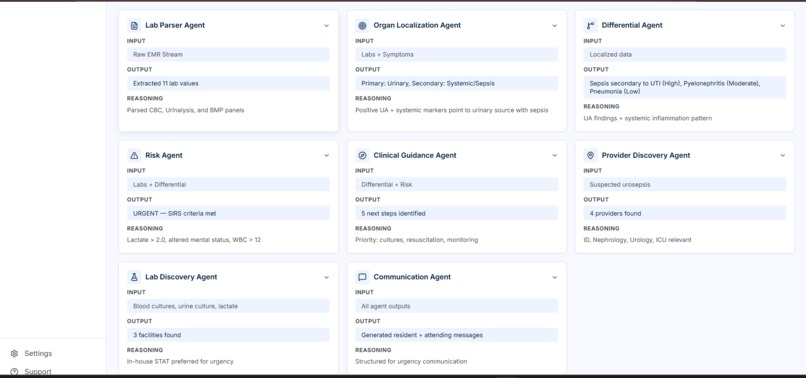
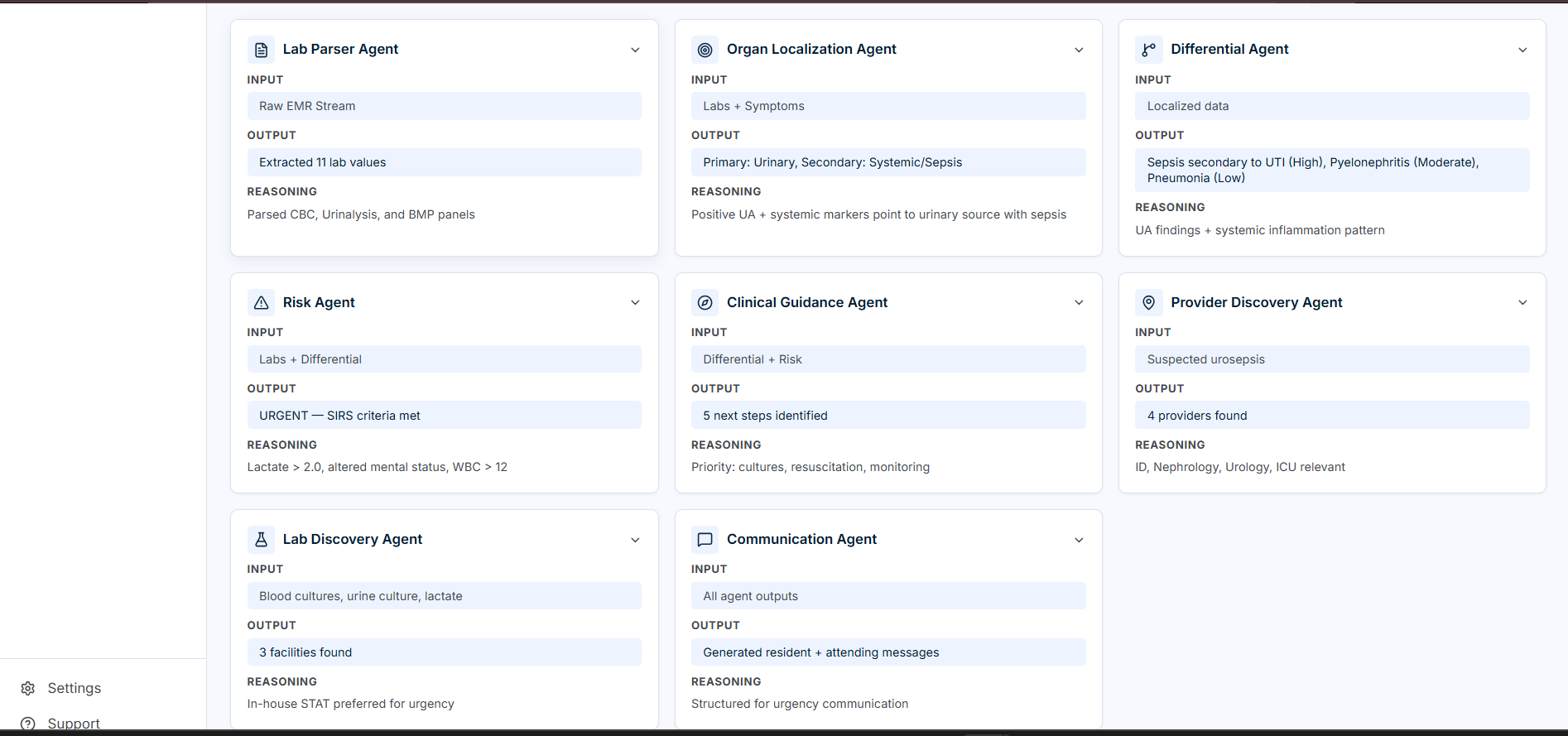
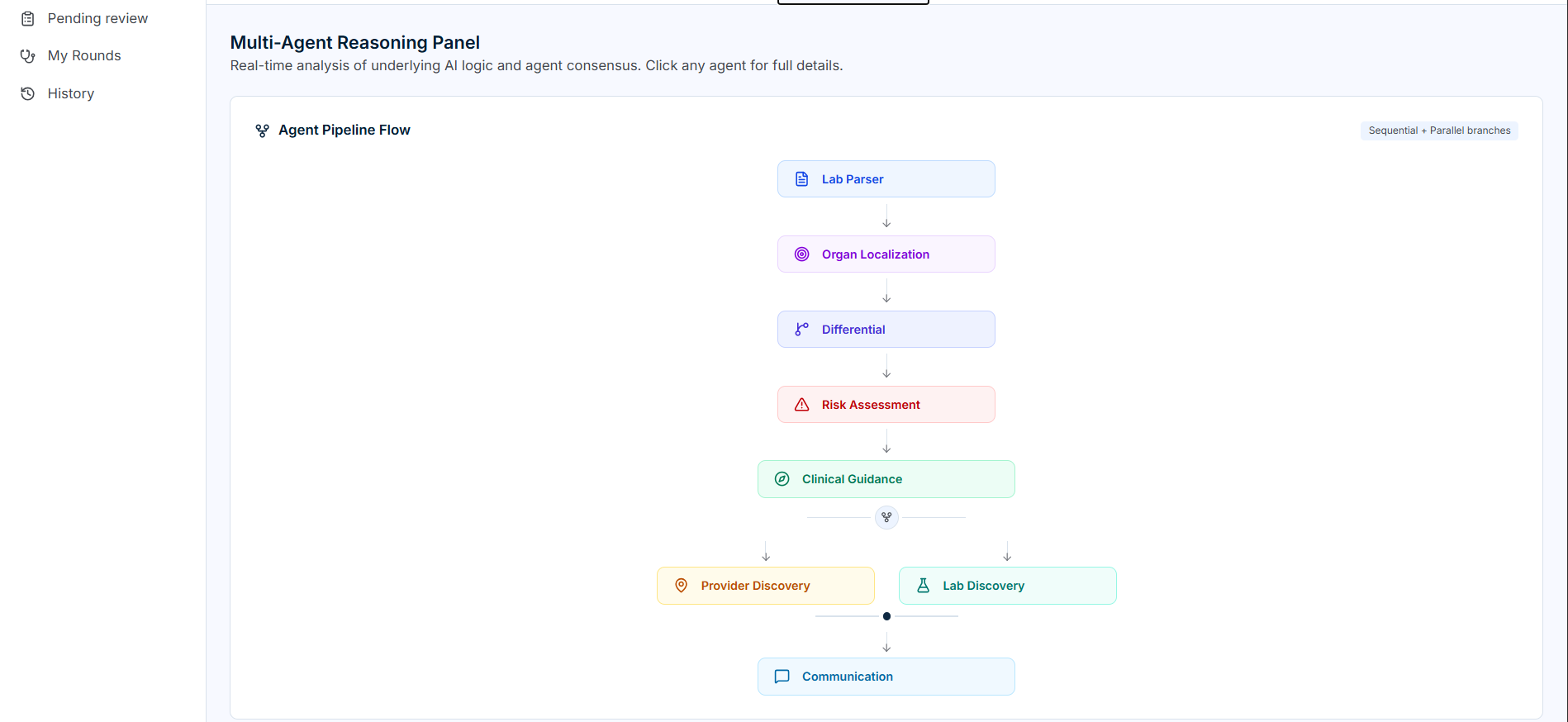
MultiAgent Panel
-
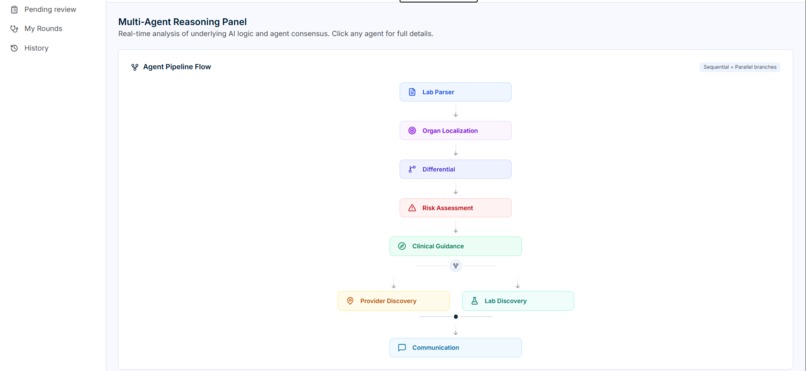
MultiAgent output
-
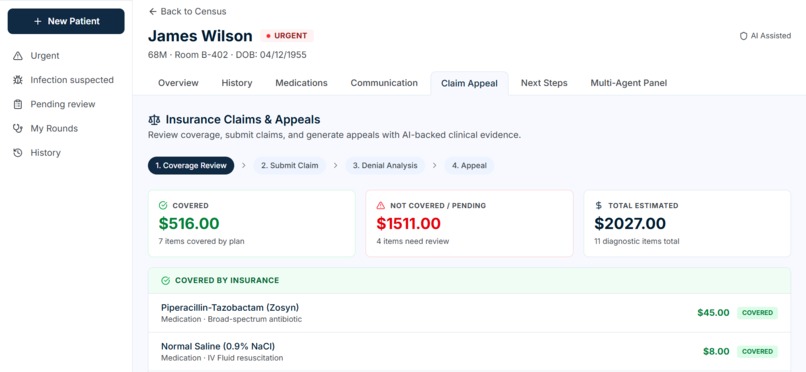
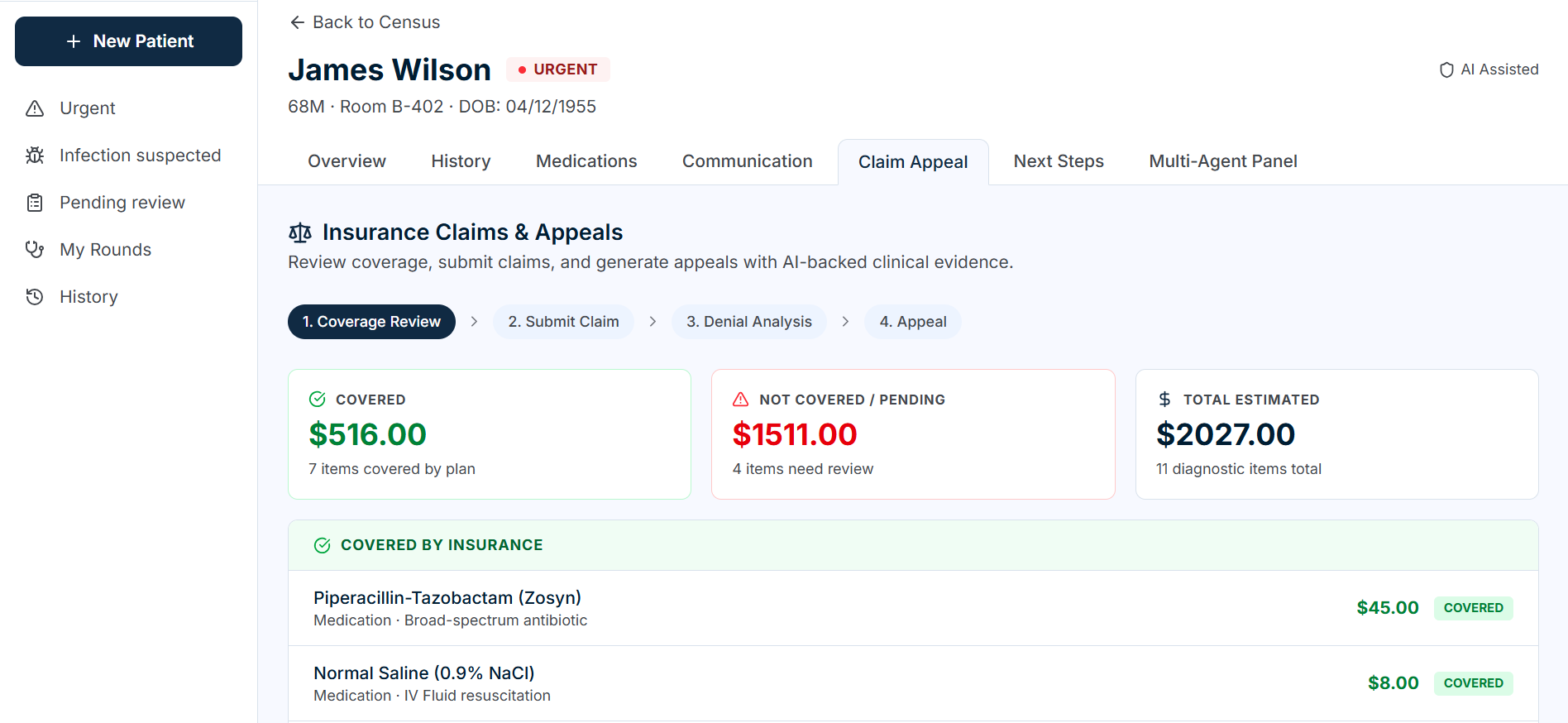
Insurance claim
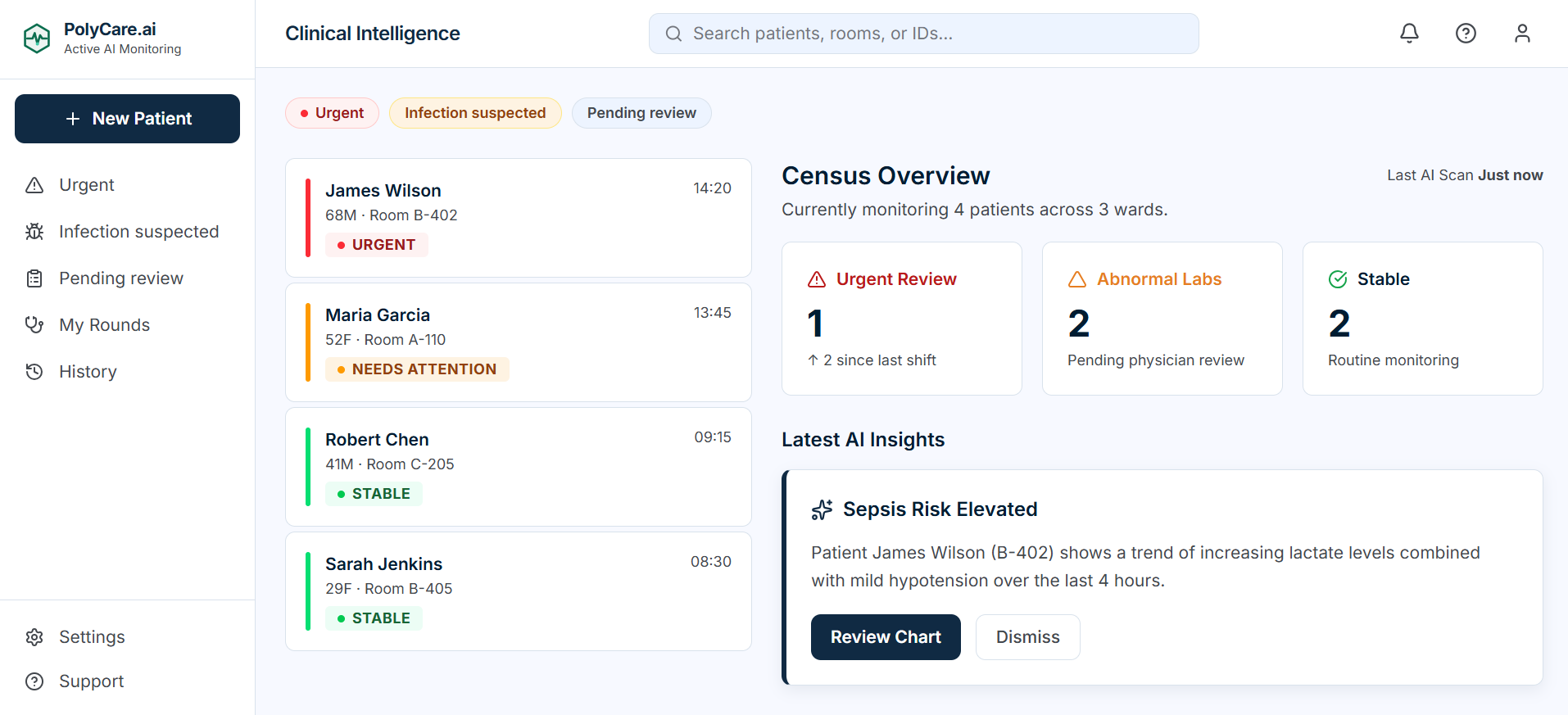
PolyCare.ai — Multi-Agent Clinical Decision Support
automates the clinical busywork that buries residents: parsing labs, building differentials, drafting handoff notes, and fighting denied insurance claims — all from a single patient intake. It's the decision-support copilot that gives clinicians back 30 minutes per admission.
Built at LA Hacks 2026 · Tracks: Catalyst for Care · Agentverse – Search & Discovery of Agents · Augment the Agent · Figma Make Challenge
Inspiration
The idea for PolyCare.ai came from watching residents, attending nurses/interns, and hospital admins drown in repetitive clinical busywork. A single patient admission can mean manually parsing a CBC, BMP, and CRP reports, cross-referencing abnormals, building a mental differential, calculating risk, writing a handoff note, and figuring out which specialist to call — all before the next admit rolls in.
We kept asking: why does every step of this pipeline live in a clinician's head instead of in software?
Medical AI today is mostly single-prompt chatbots. You paste labs into GPT, get a wall of text, and still have to structure it yourself. There's no decomposition, no transparency into which reasoning step went wrong, and no way to inspect or override individual pieces. We wanted something fundamentally different, a system where each clinical reasoning step is an independent, auditable agent with medical grounding.
The Catalyst for Care track at LA Hacks crystallized this: develop solutions that revolutionize the patient-provider and hospital management experience. That's exactly the gap, but a decomposed clinical reasoning pipeline that a resident can actually trust and inspect and modify.
The $$n = 8$$ agent architecture wasn't arbitrary. It mirrors how an experienced attending actually thinks:
$$\text{Raw Labs} \xrightarrow{\text{parse}} \text{Structured Values} \xrightarrow{\text{localize}} \text{Organ Systems} \xrightarrow{\text{differentiate}} \text{Hypotheses} \xrightarrow{\text{assess}} \text{Risk}$$
Each arrow is a different cognitive task. We made each one a separate AI agent.
What It Does
PolyCare.ai is a multi-agent AI copilot for clinical lab interpretation and decision support. Upload a lab report (or paste raw text), and eight specialized agents run in a coordinated pipeline:
| Agent | Role |
|---|---|
| Lab Parser | Extracts test names, values, units, reference ranges; flags abnormalities |
| Organ Localization | Maps abnormals to primary and secondary organ systems |
| Differential | Generates ranked conditions with supporting evidence and citations |
| Risk | Scores clinical urgency using labs, vitals, and differential findings |
| Clinical Guidance | Non-prescriptive next steps, monitoring plans, treatment categories |
| Provider Discovery | Identifies relevant specialists based on suspected condition |
| Lab Discovery | Recommends follow-up tests with facility options and pricing |
| Communication | Drafts role-appropriate messages for residents and attendings |
The pipeline produces structured, inspectable JSON at every stage — not freeform text you have to re-interpret.
How We Built It
Architecture
Lab Report Input
│
▼
┌─────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ Lab Parser │──▶│ Organ Localization│──▶│ Differential │
│ Agent │ │ Agent │ │ Agent │
└─────────────┘ └──────────────────┘ └─────────────────┘
│
▼
┌─────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ Communication│◀──│ Clinical Guidance │◀──│ Risk │
│ Agent │ │ Agent │ │ Agent │
└─────────────┘ └──────────────────┘ └─────────────────┘
│
┌──────────┼──────────┐
▼ ▼
┌──────────────┐ ┌──────────────┐
│ Provider │ │ Lab Discovery│
│ Discovery │ │ Agent │
└──────────────┘ └──────────────┘
Tech Stack
- Frontend: React 19 + Vite + Tailwind CSS 4 + React Router + Lucide Icons
- Backend: Python FastAPI + Uvicorn
- Medical AI: Fetch.ai Agentverse MedGemma (primary) + Google Gemma 4 (fallback)
- Design: Figma Make for rapid prototyping and iteration
- Grounding: Cognition-inspired RAG pipeline for clinical evidence retrieval
- Each agent = separate module, separate medically-tuned prompt, separate API call with structured JSON output
Fetch.ai Agentverse — MedGemma Integration
Our medical agents are powered by MedGemma-4b-it, a medically fine-tuned LLM hosted as an agent on the ASI Agentverse platform. We registered our multi-agent orchestration with Agentverse and implemented the Chat Protocol to enable direct ASI:One interactions. The agent address (agent1qwgxfxnk5v2l8a92fygjwjxg7uu32hec6d0cggjjs4gkwr9p5a4v76alve6) is discoverable on the Agentverse network, turning user intent ("analyze this lab report") into real, executable clinical reasoning.
When MedGemma is available, it serves as the primary LLM for the Differential, Risk, and Clinical Guidance agents — the three agents where medical domain knowledge matters most. If the Agentverse endpoint is unreachable, the system automatically falls back to Gemma 4 with medically-tuned system prompts, so the pipeline never breaks.
Cognition Grounding with RAG
Inspired by the Cognition "Augment the Agent" challenge, we built grounding mechanisms to make our AI agents measurably more capable and reduce hallucination:
- Citation-enforced prompts: Every agent's system prompt mandates inline citations from published medical literature (e.g.,
[Source: Surviving Sepsis Campaign Guidelines, 2021]). The agent cannot make a clinical claim without grounding it in a named source. - Structured evidence retrieval: Upstream agents feed structured context (parsed labs, organ localization, differential hypotheses) into downstream agents as retrieval-augmented input — each agent reasons over retrieved evidence from prior agents, not raw unstructured text.
- Output verification: Every agent returns schema-validated JSON. The pipeline rejects malformed outputs and surfaces exactly which reasoning step failed, enabling human-in-the-loop correction.
This RAG-style architecture means no agent operates in a vacuum. The Clinical Guidance Agent, for example, receives the full chain of evidence:
$$\text{Guidance}(x) = f\big(\text{labs}(x),\; \text{organs}(x),\; \text{differential}(x),\; \text{risk}(x)\big)$$
Figma Make — Design Workflow
We used Figma Make early in the hackathon to rapidly prototype the clinical dashboard before writing any frontend code. Make let us:
- Explore layout options for the 8-agent pipeline visualization — we tested vertical flow, grid, and branching layouts in minutes
- Iterate on the patient detail view — the Overview → History → Medications → Communication tab structure came directly from a Make prototype we built at 1 AM
- Pitch the concept to our team — instead of describing what the agent pipeline would look like, we showed a clickable Make prototype that communicated the vision instantly
- Kill bad ideas fast — we originally had a separate page per agent; Make helped us realize a single expandable card layout was far more intuitive, saving hours of frontend rework
Figma Make wasn't our final product — it was our thinking tool. The final React UI was built from scratch, but every major layout decision was validated in Make first.
Key Design Decisions
- MedGemma-first, Gemini fallback: We use a medically fine-tuned model when available, with automatic fallback to Gemini for reliability. The user never sees a failure — the pipeline always completes.
- Structured JSON output: Every agent returns typed, schema-validated JSON. No parsing ambiguity, no hallucinated formatting.
- Citation requirements: Every clinical claim must include an inline citation. This is enforced in every agent's system prompt.
- Non-prescriptive language: The system deliberately avoids definitive recommendations. Uncertainty language and clinician-confirmation disclaimers are baked into every output.
Challenges We Faced
1. Agentverse MedGemma integration. The Fetch.ai Agentverse API uses a message-passing protocol with Chat Protocol requirements — not a standard chat completions endpoint. We hit 404s, 401s, and 422s across multiple endpoint variations (/v1beta1/engine/chat/completions, /v1/submit, /v1beta1/engine/chat/sessions) before understanding the agent addressing and authentication model. We built a robust fallback system that degrades gracefully to Gemini when the Agentverse network is unavailable.
2. Rate limits with 8 agents. Each pipeline run fires 8 LLM calls. On the Gemini free tier ($n = 20$ requests/day for 2.5 Flash), we could only run the full pipeline twice before hitting quota. We added retry-with-backoff logic and model fallback chains to handle this:
$$\text{MedGemma} \xrightarrow{\text{fail}} \text{Gemma 4} \xrightarrow{\text{rate-limited}} \text{retry with } 2^k \text{ backoff}$$
3. JSON parsing from thinking models. Gemma 4 is a "thinking" model that sometimes wraps JSON in markdown fences or emits reasoning tokens before the actual output. We built a multi-layer parser that strips fences, handles double-encoded JSON strings, and extracts JSON objects from surrounding text.
4. RAG pipeline data flow. Each agent depends on upstream agents' output as the retrieved context. The Differential Agent needs parsed labs and organ localization. Risk needs the differential. Getting the data handoff right — without creating a monolithic prompt — required careful schema design at every boundary. This was the core Cognition-style challenge: making each agent measurably more capable by giving it structured, grounded context from prior reasoning steps.
5. Bridging design and implementation. Figma Make got us to a shared vision in the first hour, but translating a Make prototype into a production React UI with 8 dynamic agent cards, real-time pipeline traces, and editable communication drafts required significant iteration. The gap between "looks right in Make" and "works right in code" was where most of our frontend hours went.
What We Learned
- Decomposition > monolithic prompts. Splitting clinical reasoning into 8 agents made each one dramatically more reliable than a single mega-prompt. When something goes wrong, you can see exactly which agent failed and why.
- Medical AI needs guardrails, not just accuracy. Citations, uncertainty language, and non-prescriptive framing aren't nice-to-haves — they're the difference between a useful tool and a dangerous one.
- Fallback chains are essential for production AI. No single model endpoint is reliable enough for a real-time clinical tool. The MedGemma → Gemini → retry chain was the most important reliability decision we made.
- Structured output changes everything. Forcing JSON output (via system prompts and
response_mime_type) eliminated the entire class of "the LLM said something useful but I can't parse it" bugs. - Agentverse is powerful but early. Registering agents on Fetch.ai's Agentverse and implementing the Chat Protocol gave us discoverability via ASI:One, but the API surface is still evolving. Building resilient fallback logic around it was essential.
- RAG isn't just for documents. Our Cognition-inspired grounding approach treats prior agent outputs as retrieved context for downstream agents. This agent-to-agent RAG pattern was more effective than feeding every agent the same raw input.
- Prototype before you code. Figma Make saved us hours of frontend rework. Every layout decision we validated in Make first shipped faster and with fewer revisions than the ones we jumped straight into code for.
Quick Start
1. Set your API keys
# backend/.env
GEMINI_API_KEY=your-gemini-api-key
AGENTVERSE_API_TOKEN=your-agentverse-token # for MedGemma
2. Install & run backend
cd backend
pip install -r requirements.txt
cd ..
python -m uvicorn backend.main:app --reload --port 8000
3. Install & run frontend
cd frontend
npm install
npm run dev
Demo
The app ships with 4 pre-loaded patient cases (mock data with pre-computed agent outputs) so you can explore the full UI immediately without an API key:
- James Wilson (68M) — Urgent: Suspected urosepsis
- Maria Garcia (52F) — Needs Attention: Acute appendicitis
- Robert Chen (41M) — Stable: Dyslipidemia follow-up
- Sarah Jenkins (29F) — Stable: Viral pharyngitis
Features
- True multi-agent system: 8 independent LLM calls, each with its own medically-tuned prompt and JSON schema
- Full pipeline trace: Every agent's input, output, and reasoning is inspectable
- Clinical workflow: Labs → Interpretation → Risk → Communication → Next Steps
- Non-prescriptive guidance: Uses uncertainty language and disclaimers throughout
- Three input modes: Manual entry, paste raw text, file upload
- Role-based communication: Editable resident message and attending summary
- Research citations: Every clinical claim backed by inline source references
- Provider & Lab discovery: Clickable links to specialists and lab facilities
Built With
- fastapi
- fetch.ai
- react
- tailwind
- vite

Log in or sign up for Devpost to join the conversation.