-
-
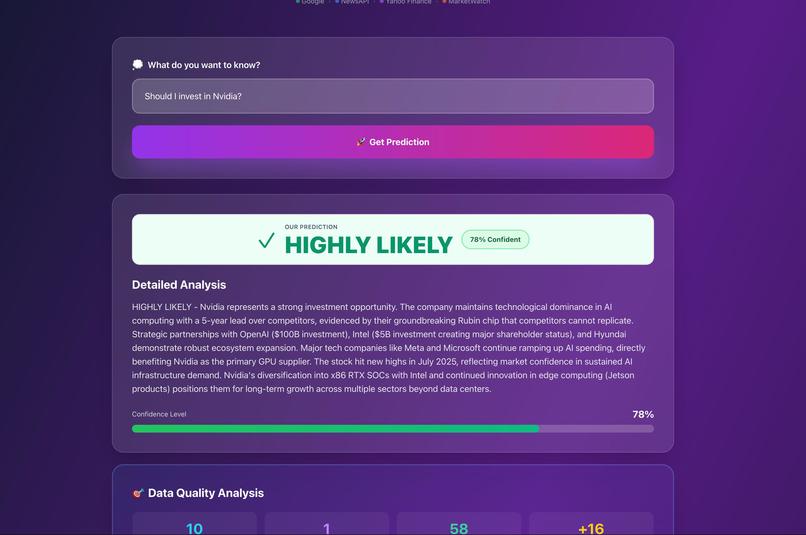
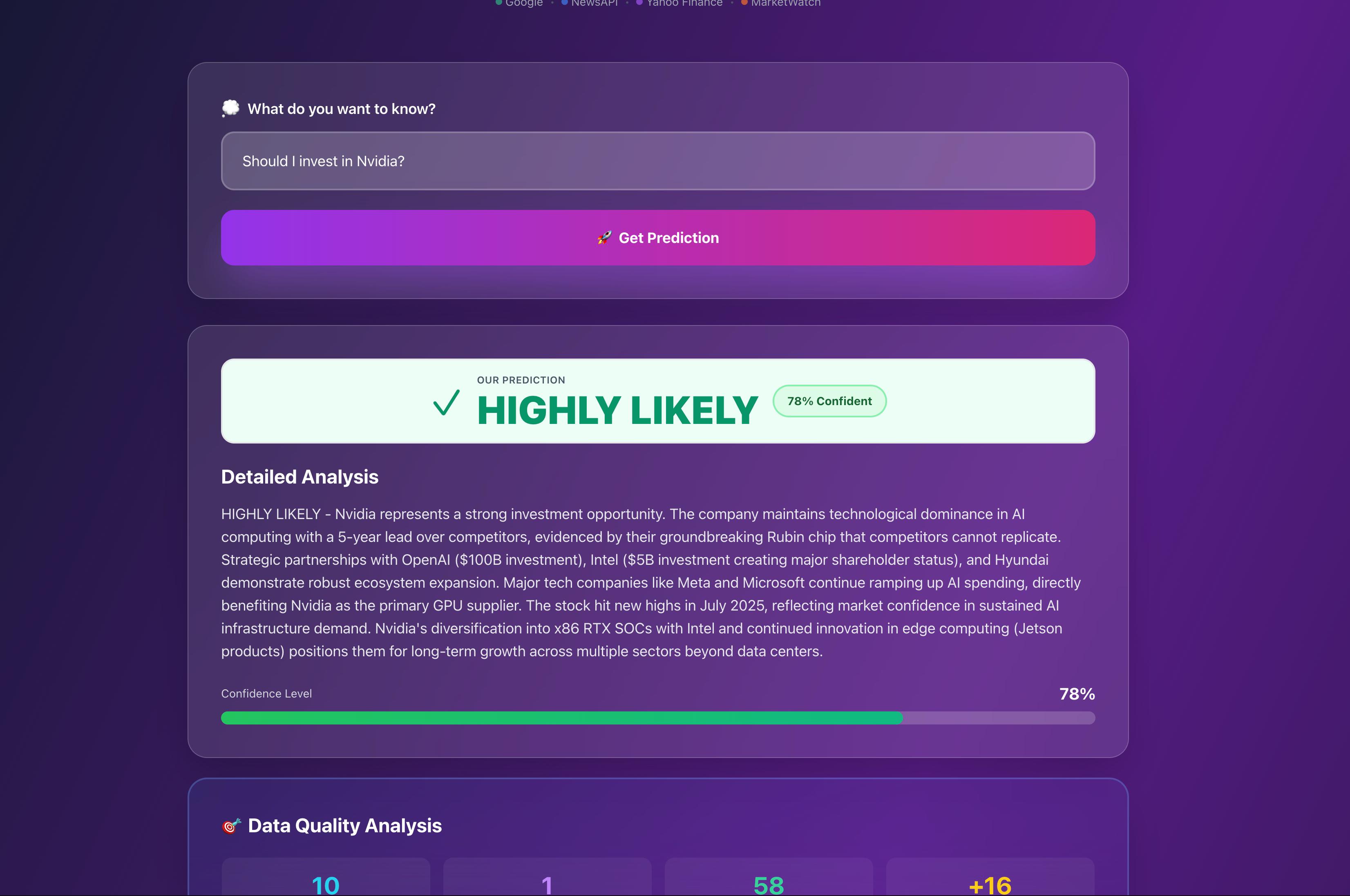
The user prompts the Claude AI powered Chatbot and outputs a prediction score
-

The prediction score is calculated from evidences derived from google and news API, market watch, yahoo finance, and NewsAPI
-
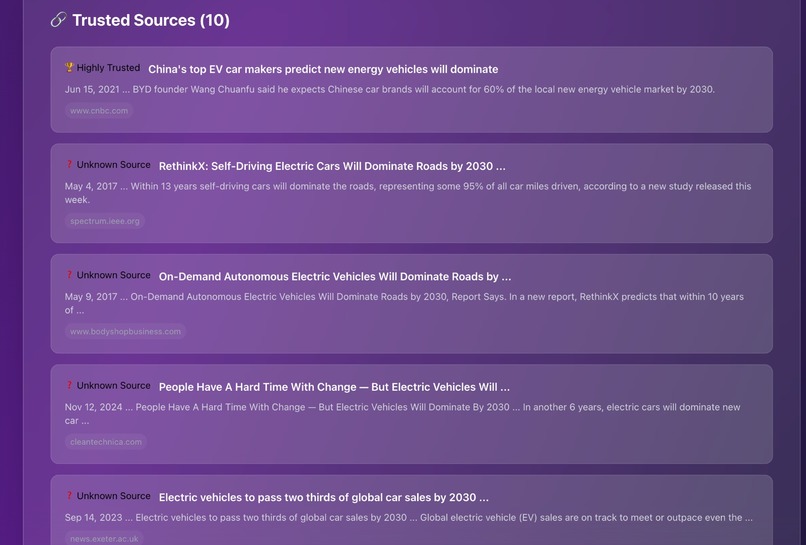
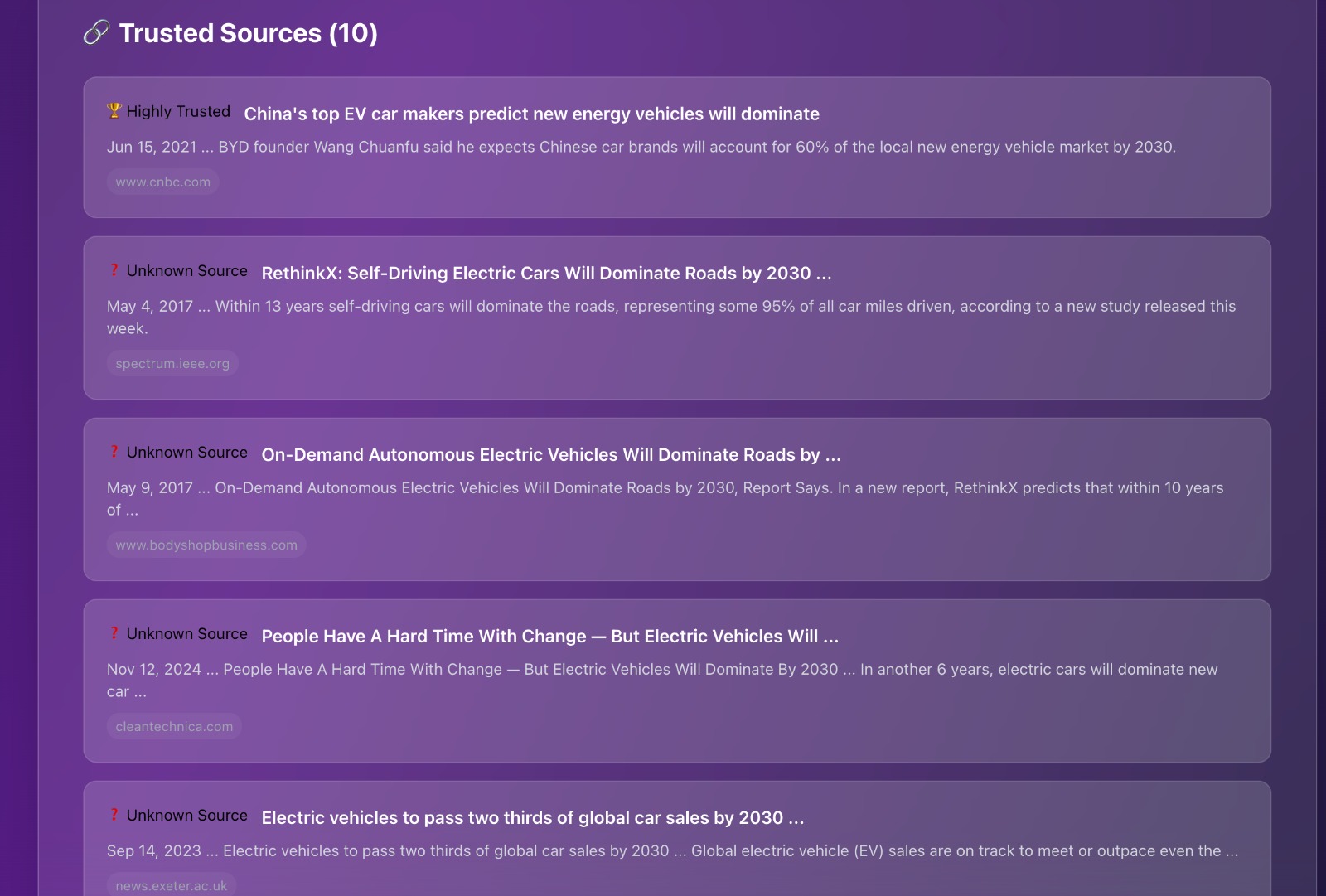
The retrieved data from the sources are ranked based on reputability and are displayed

Poly Market Predictor - Project Story
Inspiration
We were inspired by the challenge of making informed predictions in an increasingly complex world. With information scattered across countless sources—from financial news to social media discussions—we wanted to create a tool that could aggregate, analyze, and synthesize data to provide reliable predictions with transparent confidence scores. The Polymarket track presented the perfect opportunity to build something that could help users make better-informed decisions by leveraging AI to process multiple data sources simultaneously.
What it does
Poly Market Predictor is an AI-powered prediction tool that aggregates data from multiple premium sources to generate informed predictions with confidence scores. Here's how it works:
Multi-Source Data Aggregation: The system simultaneously queries 5+ premium data sources:
- Google Custom Search API (high-quality web results)
- NewsAPI (trusted news articles)
- Yahoo Finance (financial data and market news)
- MarketWatch RSS (financial market insights)
- Reddit API (community sentiment and discussions)
AI-Powered Analysis: Claude AI (Anthropic) analyzes all aggregated data to generate:
- A definitive prediction (YES/NO/LIKELY/UNLIKELY)
- Confidence score (0-100%) based on data quality and quantity
- Key factors influencing the prediction
- Important caveats and considerations
- Source attribution for transparency
Data Quality Scoring: Each source is evaluated for:
- Reputation and reliability (Tier 1-3 classification)
- Relevance to the query
- Recency of information
- Sentiment analysis
Beautiful User Interface: A modern, responsive React frontend with:
- Gradient animations and glassmorphism design
- Real-time confidence visualization
- Detailed breakdown of data sources
- Key evidence and caveats display
How we built it
Frontend (React + Tailwind CSS)
- Framework: React with Create React App
- Styling: Tailwind CSS with custom animations
- API Integration: Axios for backend communication
- Deployment: Vercel with environment variable configuration
Backend (Flask + Python)
- Framework: Flask with CORS enabled for cross-origin requests
- AI Integration: Anthropic Claude API (Claude Sonnet 4.5)
- Data Sources: Custom modules for each API:
data_sources.py: Google Search, Yahoo Finance, NewsAPI, Redditsource_quality.py: Quality scoring and source tier classificationprediction_score.py: Confidence calculation algorithms
- Database: SQLite with SQLAlchemy ORM for prediction history
- Deployment: Render with Gunicorn WSGI server
Key Technical Features
- Multi-threaded data fetching: Parallel API calls for faster response times
- Smart query enhancement: Automatic query optimization for better search results
- Sentiment analysis: TextBlob integration for source sentiment scoring
- Error handling: Comprehensive fallbacks and graceful degradation
- Data quality metrics: Confidence boost calculation based on source quality
Challenges we ran into
API Integration Complexity: Integrating 5+ different APIs with varying authentication methods, rate limits, and response formats required careful error handling and fallback strategies.
Data Quality Assessment: Creating a reliable system to score and rank data sources by quality, relevance, and recency was challenging. We developed a tier-based classification system (Tier 1-3) with reputation badges.
Confidence Score Calculation: Determining how to translate data quality and quantity into a meaningful confidence score required multiple iterations. We eventually implemented a hybrid approach combining source quality, data quantity, and Claude's own assessment.
CORS and Deployment Issues: Configuring CORS for production deployment while maintaining security required careful configuration. We also faced challenges with environment variables in both Vercel and Render.
Real-time Data Aggregation: Fetching data from multiple sources simultaneously while maintaining performance and handling timeouts required implementing parallel processing and smart timeout handling.
Source Attribution: Ensuring transparency by properly attributing sources while maintaining a clean user experience required careful UI/UX design.
Accomplishments that we're proud of
Multi-Source Integration: Successfully integrated 5+ premium data sources with intelligent fallbacks and error handling.
Confidence Scoring System: Developed a sophisticated confidence scoring algorithm that considers data quality, quantity, source reputation, and AI analysis.
Data Quality Framework: Created a comprehensive source quality assessment system with tier classification, reputation badges, and quality scores.
Beautiful UI/UX: Designed and implemented a modern, responsive interface with smooth animations, gradient effects, and intuitive information hierarchy.
Full-Stack Deployment: Successfully deployed both frontend (Vercel) and backend (Render) with proper environment variable configuration and CORS setup.
Database Integration: Implemented SQLite database with SQLAlchemy to store prediction history, queries, and results for future analysis.
Error Resilience: Built a robust system that gracefully handles API failures, network issues, and missing data without breaking the user experience.
Transparency: Implemented comprehensive source attribution so users can see exactly where predictions come from.
What we learned
API Integration Best Practices: Learned how to handle multiple APIs with different authentication methods, rate limits, and response formats. Discovered the importance of implementing fallbacks and timeout handling.
Data Quality Assessment: Developed understanding of how to evaluate and rank information sources based on reputation, relevance, and recency.
AI Prompt Engineering: Gained experience in crafting effective prompts for Claude API to get structured, reliable predictions with confidence scores.
Full-Stack Deployment: Learned the intricacies of deploying React frontend and Flask backend separately, configuring CORS, and managing environment variables across platforms.
Database Design: Gained experience with SQLAlchemy ORM and designing database schemas for storing complex prediction data.
Performance Optimization: Learned to implement parallel API calls and optimize response times while maintaining reliability.
Error Handling: Developed skills in comprehensive error handling and graceful degradation when external services fail.
UI/UX Design: Improved understanding of modern web design principles, including glassmorphism, gradient animations, and responsive design.
What's next for Poly Market Predictor
Enhanced Data Sources:
- Add Twitter/X API for real-time social sentiment
- Integrate more financial data sources (Bloomberg, Reuters)
- Add academic paper search (Google Scholar, arXiv)
User Features:
- User authentication and accounts
- Prediction history and favorites
- Custom source selection
- Export predictions to PDF/CSV
Advanced Analytics:
- Prediction accuracy tracking over time
- Trend analysis and pattern recognition
- Comparative predictions across similar queries
- Historical performance metrics
Real-Time Updates:
- WebSocket integration for live prediction updates
- Push notifications for significant confidence changes
- Live data source monitoring
Machine Learning Enhancements:
- Train models on historical prediction accuracy
- Improve confidence score calibration
- Source reliability learning from user feedback
Polymarket Integration:
- Direct integration with Polymarket API
- Compare our predictions with market odds
- Track prediction accuracy vs. market performance
Mobile App:
- Native iOS and Android apps
- Push notifications for predictions
- Offline mode with cached predictions
Collaboration Features:
- Share predictions with teams
- Collaborative prediction refinement
- Discussion threads on predictions
Team Members:
- Daksh Prajapati
- Vijeth Chichili
- Nikhil Balabhadra
- Teresa Nguyen
- Shashota Saha
Built for: HackASU_ANTHROPIC @ ASU - Polymarket Track

Log in or sign up for Devpost to join the conversation.