-
Landing page, a simple search page for the users to input the word they wish to find current twitter sentiment of.
-
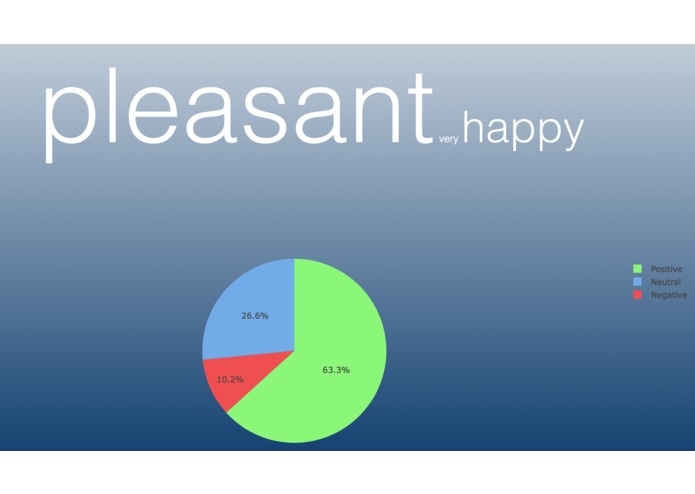
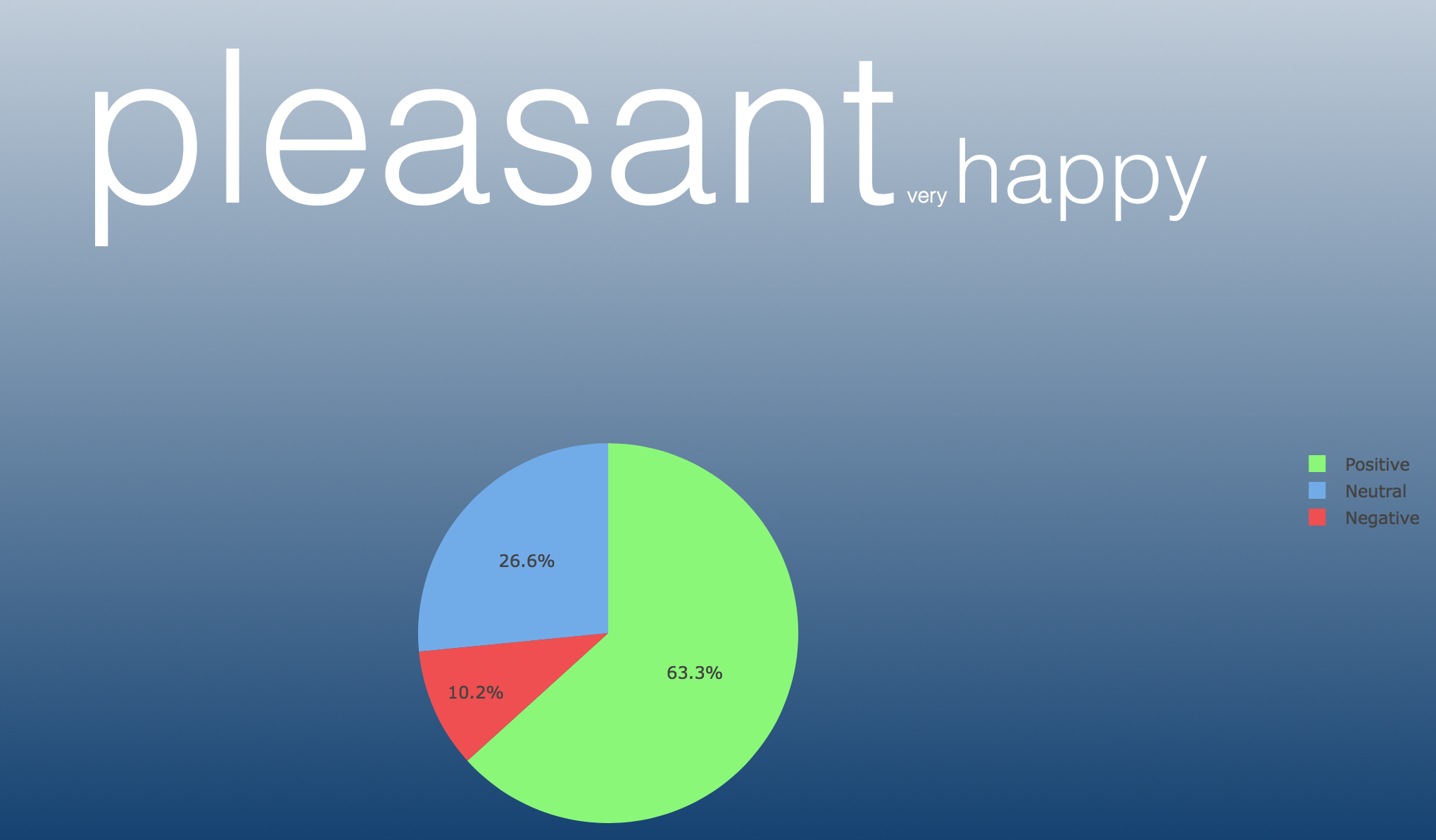
Example of search the word 'pleasant' with Poll Request
-

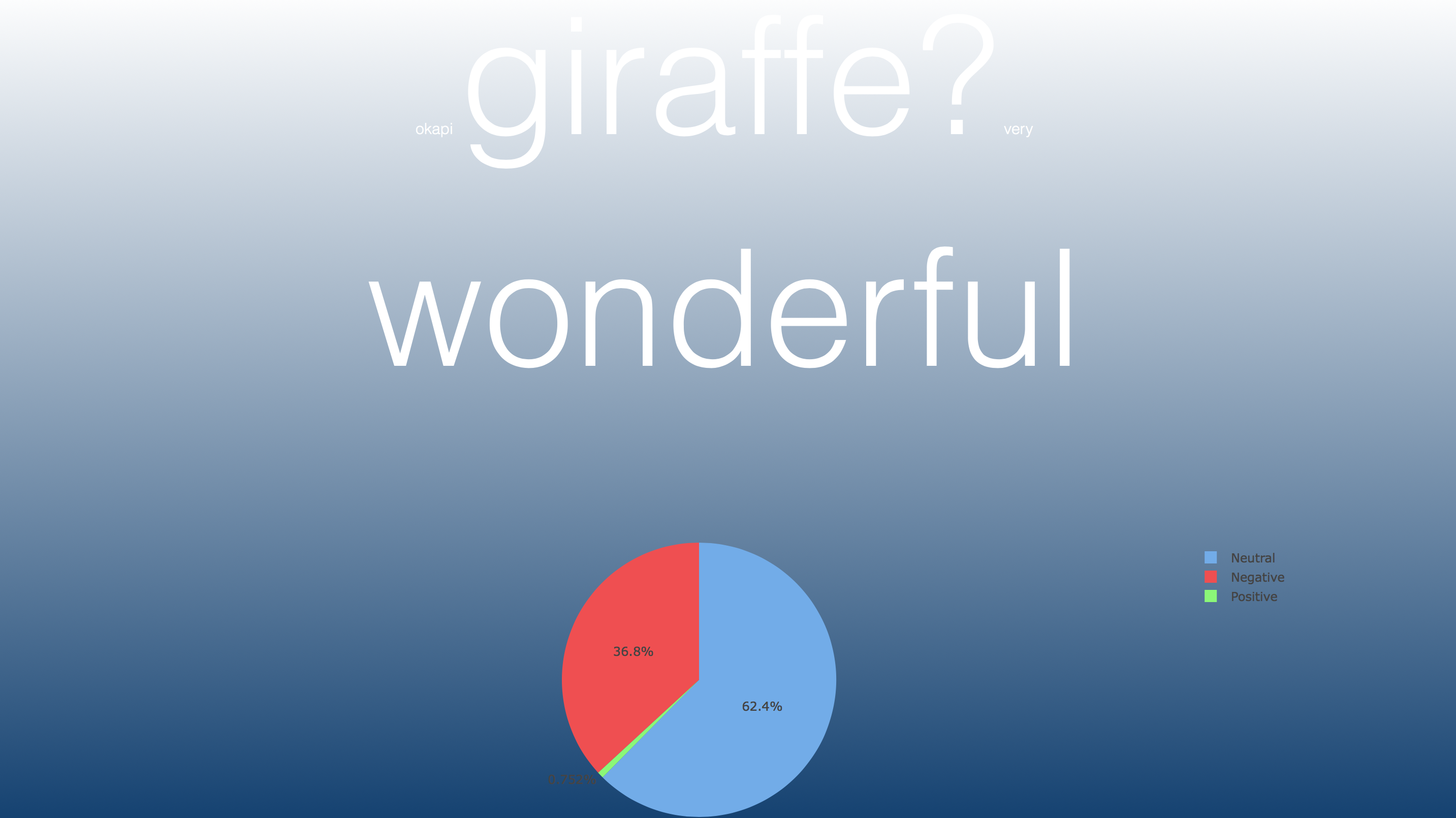
Example of searching the word 'okapi' with Poll Request.
Inspiration
We wanted to make a cool application using Google Cloud Platform(GCP), Natural Language Processing, and big data. We realized that Twitter is a great resource for a large amount of data and decided to create a sentiment analysis search engine. We also wanted to create a pleasant data visualization of the data that we collect for the users.
What it does
The web application has a search engine landing page that will allow the user to enter a word and they will be given a pie chart and a word cloud. The pie chart will consist of a percentage of positive tweets, negative tweets, and neutral/mixed tweets broken down into three colors. Green being positive, red being negative, and blue being neutral/mixed. We will also create our own sentence using the frequency of the words that have been used to describe the tweets to form a sentence that may reflect the opinions of Tweets based on the frequency of the words used. The sizing of the words in the formed sentence is dependent on the frequency of the words as well. We utilized NLTK to figure out each part of speech a word is to create the "well formed" sentence. The purpose of the application is to find the sentiment of recent tweets regarding the word, we also wanted a fun way to visualize the data with the well formed sentence.
How we built it
Python, GCP, NLP, Tweepy, HTML, CSS, Boostrap, Flask, Jinja, NLTK
Challenges we ran into
Finding a good amount of data to use from the Tweepy since we do not have an unlimited amount of tweets we are allowed to collect. We are only able to collect 1,500 tweets at a time so we could not make use of our application on as large of a scale as we wanted.
Accomplishments that we're proud of
It was our first time using a lot of these technologies. We have not used GCP, natural language processing, or data visualization tools before. It was also one of our members first hackathons. We implemented natural language tool kit as well to create our own way of visualizing the data through a complete sentence that we form based on the tweets and the frequency of the words in the tweets.
What we learned
We learned a lot regarding working with large amounts of data, cleaning data, natural language processing, google cloud platform and web development.
What's next for Poll Request
We will try to create better data visualizations and maybe improve the accuracy of the sentiment analysis.

Log in or sign up for Devpost to join the conversation.