Outline
Title: Style Transfer Who: Pooja Barai (pbarai), Emily Nomura (enomura), Megan Sindhi (msindhi)
Introduction
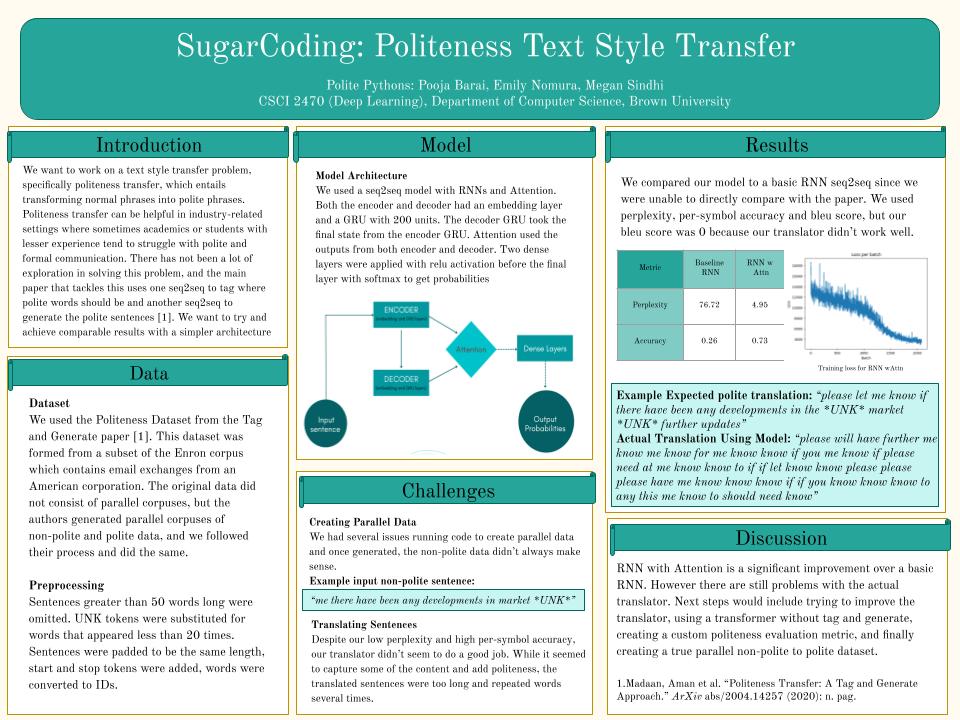
We want to work on a machine translation problem, specifically politeness transfer, which entails transforming normal phrases into polite phrases. Politeness transfer can be helpful in industry-related or generally formal settings where sometimes academics or students with lesser experience tend to struggle with polite and formal communication.
Related Work
- Please read and briefly summarize (no more than one paragraph) at least one paper/article/blog relevant to your topic beyond the paper you are re-implementing/novel idea you are researching.
- A Review of Text Style Transfer using Deep Learning by Toshevska and Gievska performs a review of various text-style transfer techniques and recent research on this to underscore the trends, commonalities and differences across these methodologies using deep learning. The paper focuses on the stages of the process: representation learning of style and content of a given sentence, and generation of the sentence in a new style. Although it talks about many text styles including personal style, formality, and offensiveness, we are primarily interested in politeness.
- In this section, also include URLs to any public implementations you find of the paper you’re trying to implement. Please keep this as a “living list”--if you stumble across a new implementation later down the line, add it to this list.
- https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9551764&casa_token=HHUnuHmpLksAAAAA:r7K0rDYGlAdTNaXXIzECNtGvBWOV_hbqOKzSH4Sr85mtiErmGyIVVja9IsgPb5yb-mdBK62Pjw We used some of their architecture:
- https://direct.mit.edu/coli/article/48/1/155/108845/Deep-Learning-for-Text-Style-Transfer-A-Survey
Data
- Using politeness transfer dataset
- The original paper for this dataset preprocesses the data and gets it ready for a seq2seq model, so we will likely use their preprocessing methods
- https://github.com/tag-and-generate/tagger-generator
- https://drive.google.com/file/d/1URNq8vGbhDNBhu_UfD9HrEK8bkgWcqpM/view
Methodology
- What is the architecture of your model?
- How are you training the model? We are going to use a seq2seq model with parallel corpuses, similar to the politeness transfer paper we are getting our data from.
- If you are doing something new, justify your design. Also note some backup ideas you may have to experiment with if you run into issues. We will try changing the existing transformer structure, since that seems to be an effective method for style transfer. Since there are so many ways to change the architecture of the transformers, we will experiment and see if changing something like the number of attention heads or layers can improve performance. We will also try using CNNs, since they are also better with key extracting the key parts of the sentence, similar to transformers.
Metrics
The evaluation metrics we will compute are perplexity, content preservation metrics, and transfer accuracy. “The metric of transfer accuracy (Acc) is defined as the percentage of generated sentences classified to be in the target domain by the classifier. The standard metric for measuring content preservation is BLEU-self (BL-s) which is computed with respect to the original sentences” (Madaan et al.) In the case of politeness transfer, content preservation is important because although we are changing the style of the sentences, we want the inherent meaning to be the same. We will compare these evaluation metrics across the different models tested (CNN and transformer) along with different hyperparameter specifications (embedding size, learning rate, etc.).
The base goal is to get a functioning seq-2-seq model. The target goal is to get a functioning model with comparable evaluation metrics to the Madaan et al. model. The stretch goal is to get a functioning model with better evaluation metrics than the Madaan et al. model.
Ethics
- What broader societal issues are relevant to your chosen problem space? Politeness has a lot of different meanings across different cultures. Politeness in one culture may not be the same in another. A politeness transfer trained on US English sentences may not do a good job of making sentences polite in other cultures and languages. This is an important consideration to make if this kind of model was going to be deployed
- Why is Deep Learning a good approach to this problem? Because politeness is a more complex and subjective attribute, it would be difficult to use more straightforward machine learning methods
Division of Labor
- Preprocessing: Pooja, Emily, Megan
- RNN with Attention: Pooja, Emily, Megan
- Write-up: Pooja, Emily, Megan
Built With
- python
- tensorflow





Log in or sign up for Devpost to join the conversation.