-
-
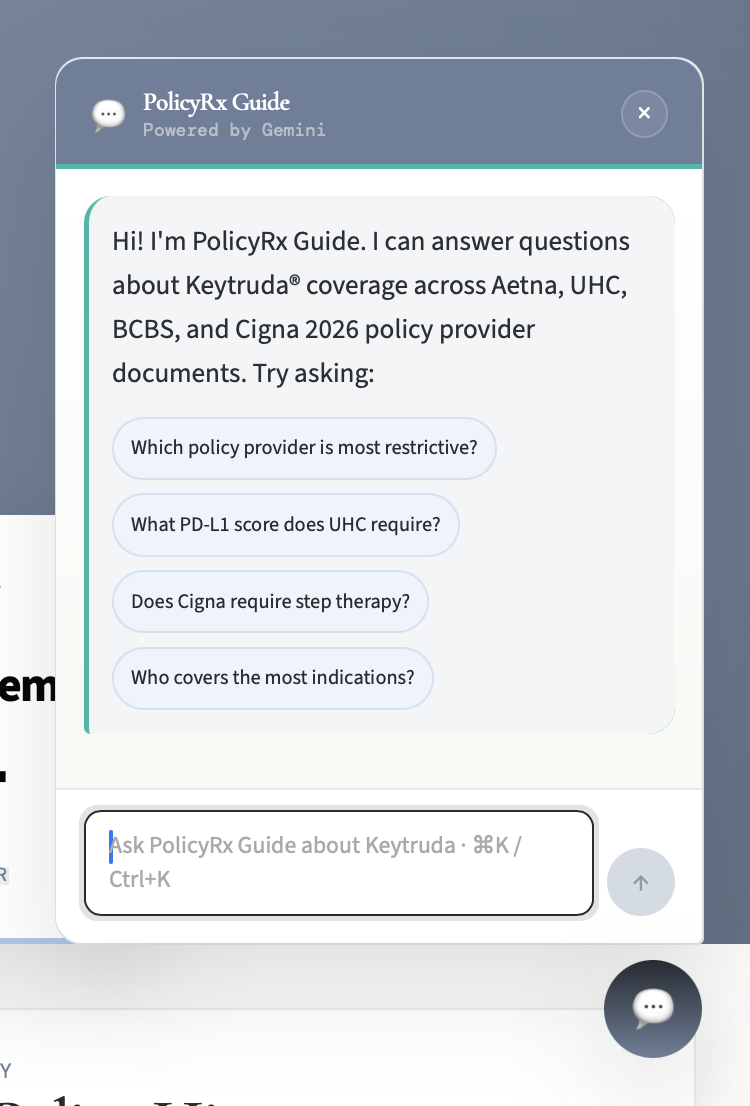
Chat Assistant
-
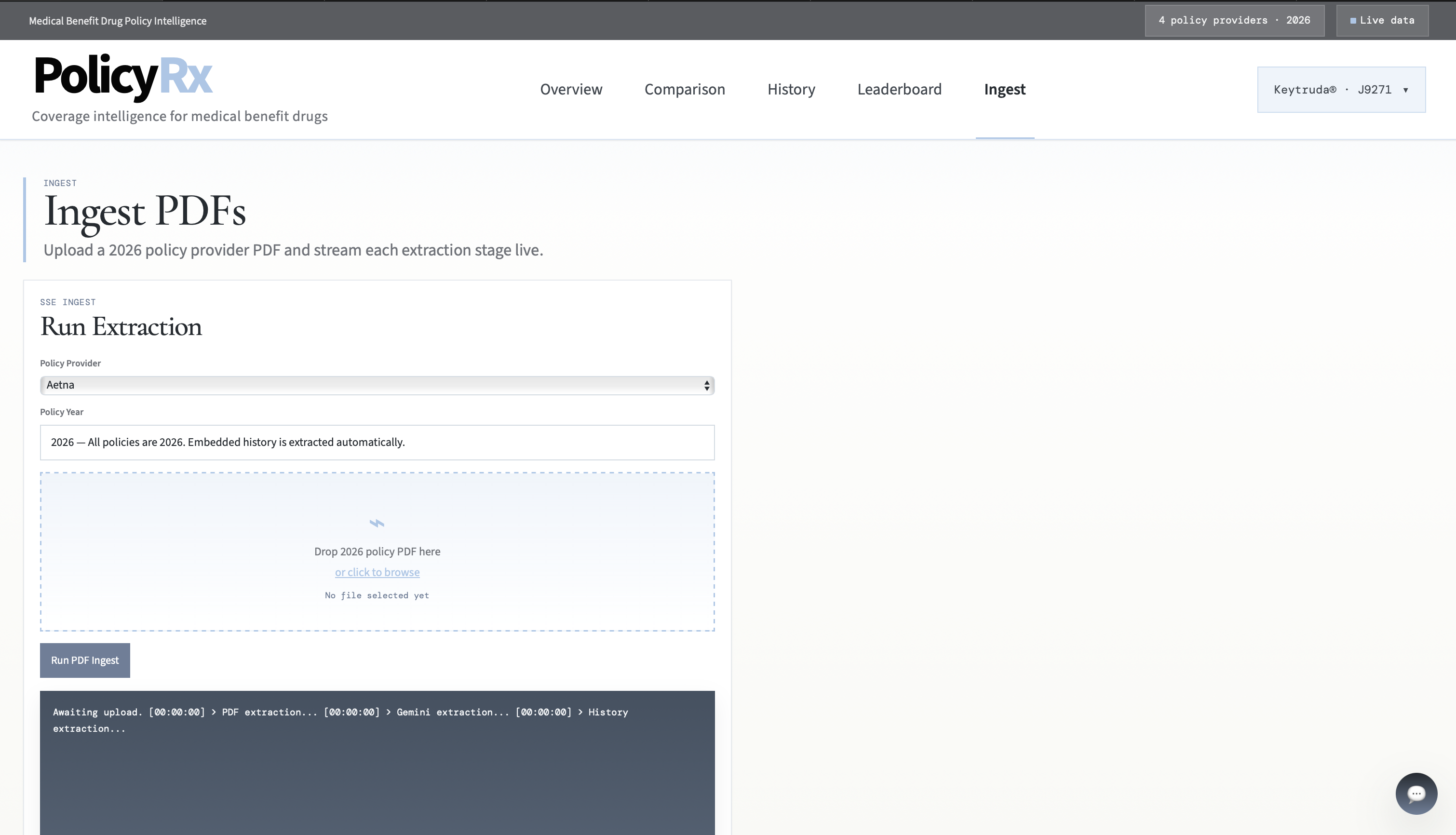
Ingest PDFs page
-
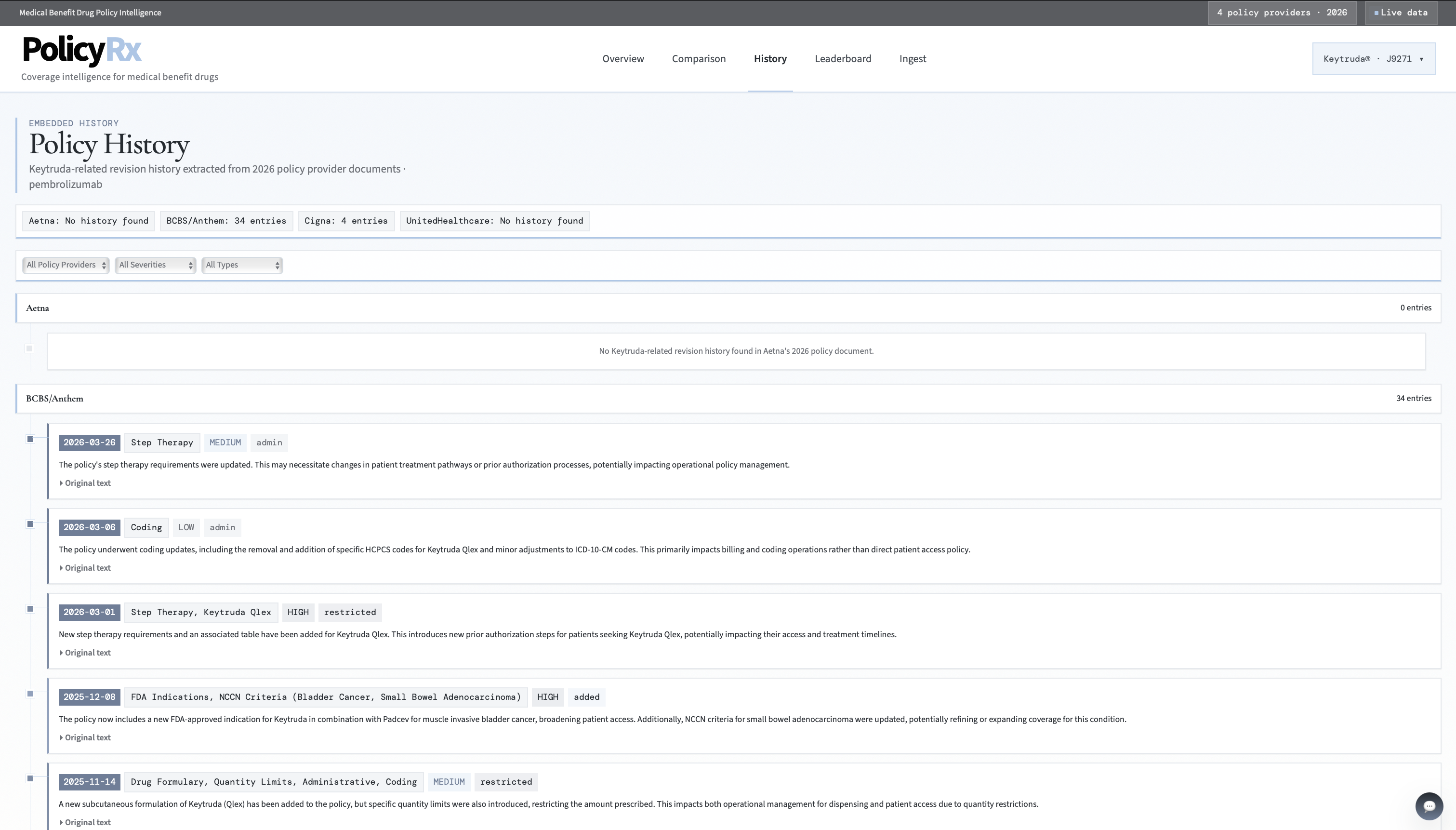
Policy History Page
-
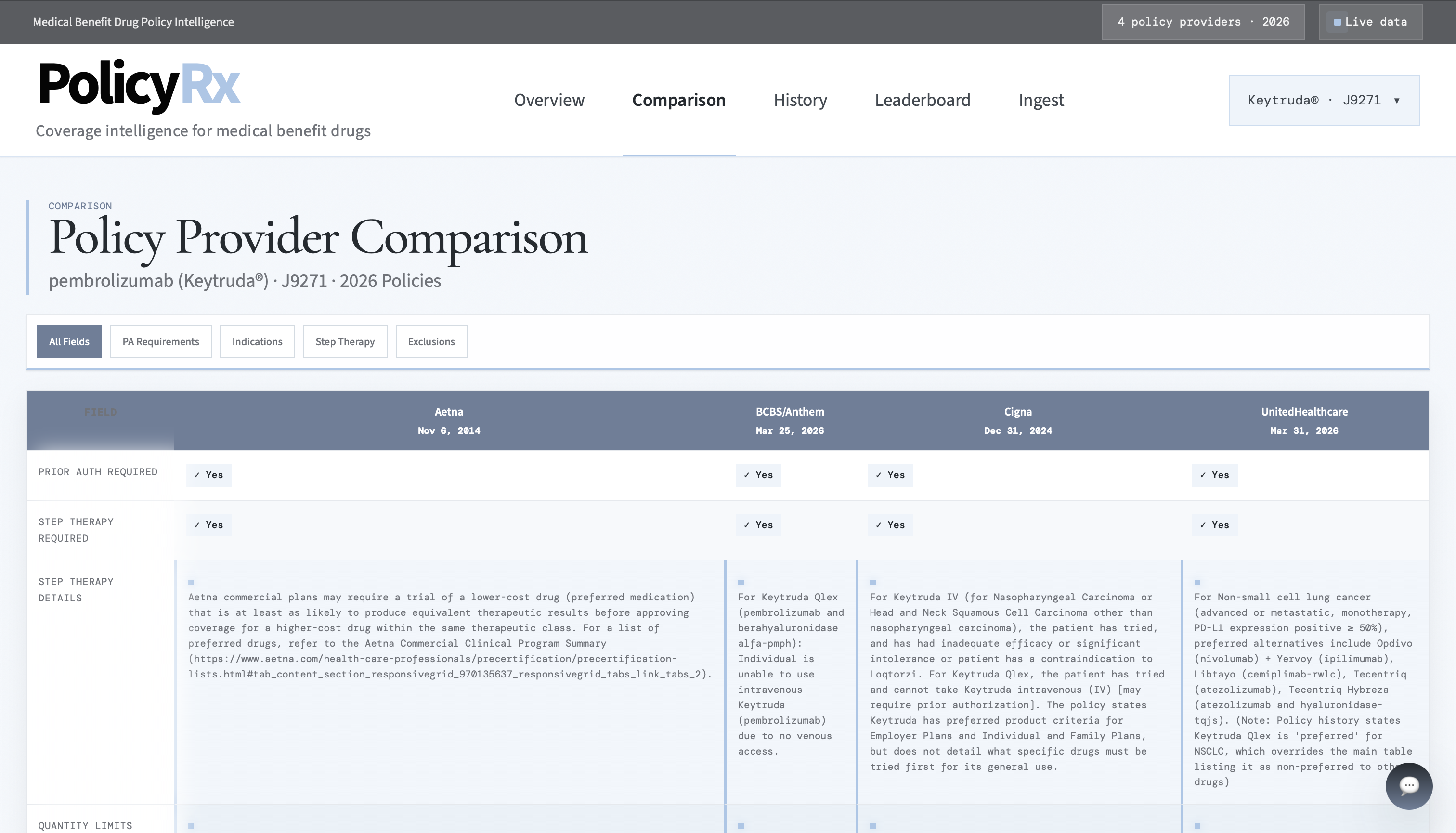
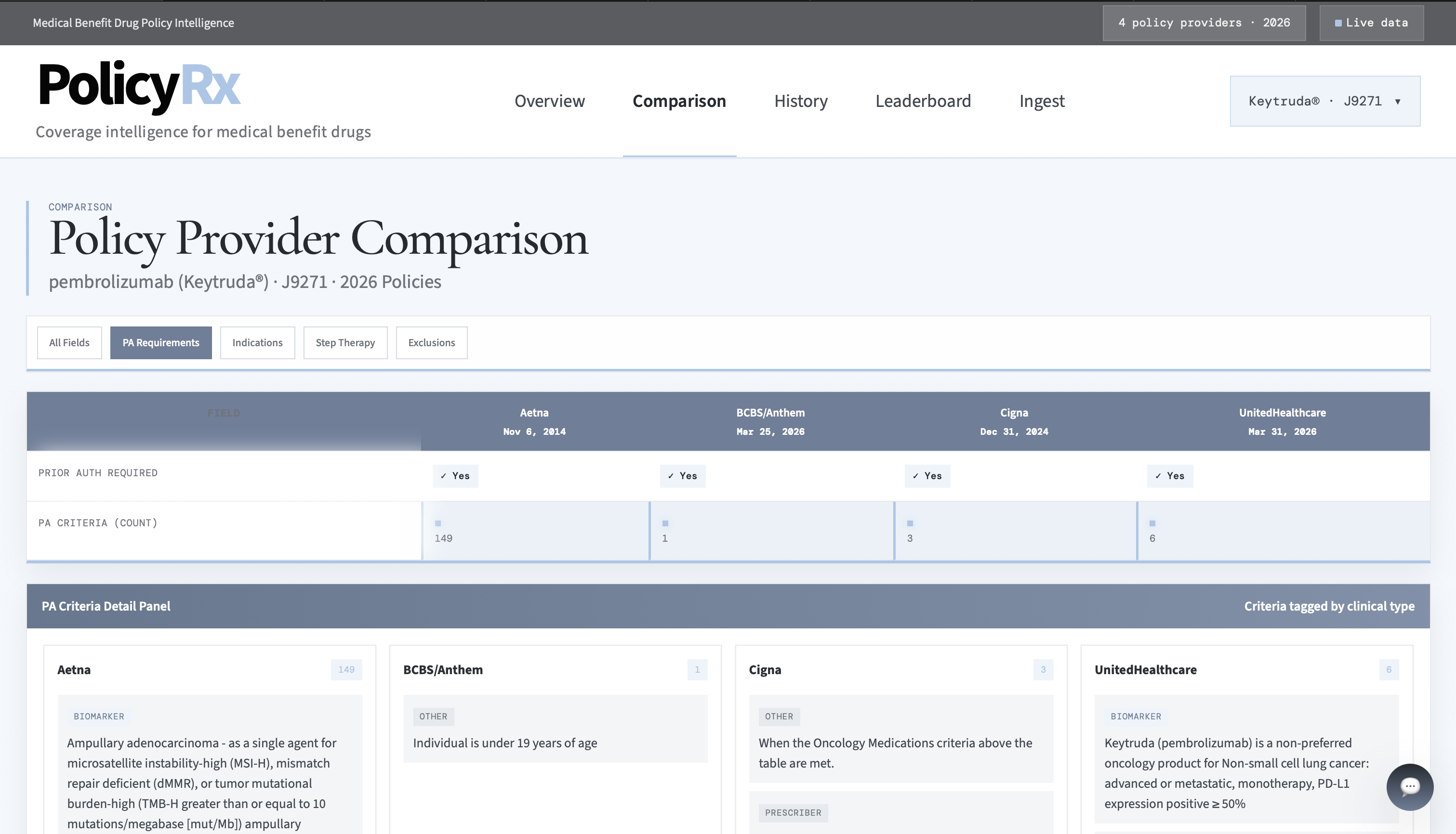
Comparison Page
-
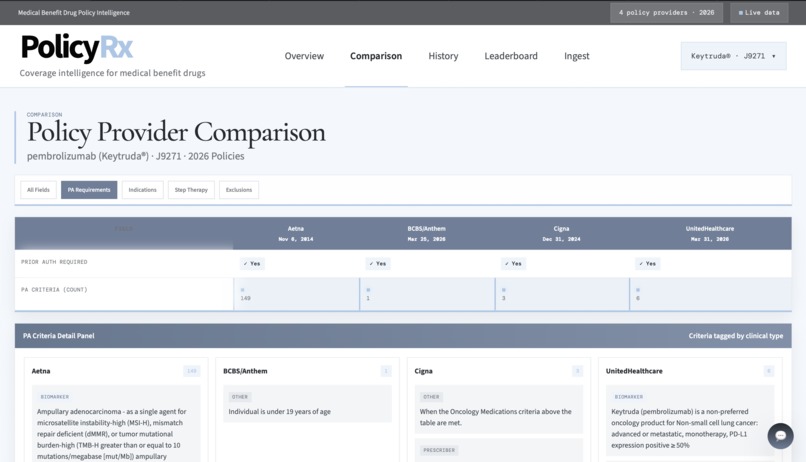
Prior Authorization Criteria Filter on the Comparison Page
-
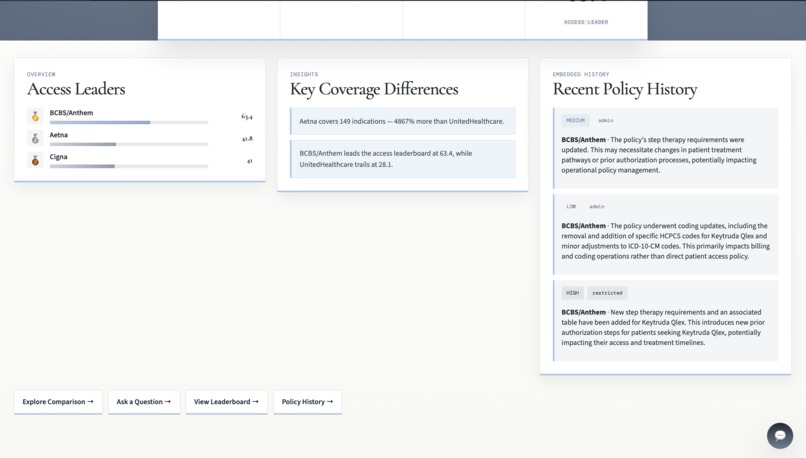
Overview Continued
-
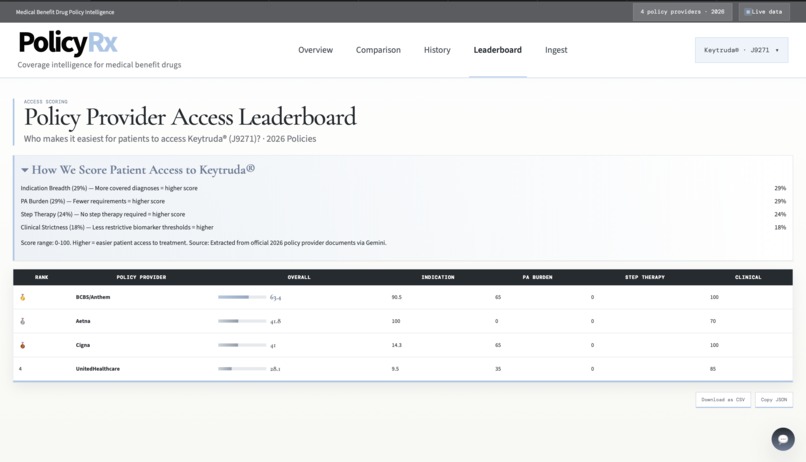
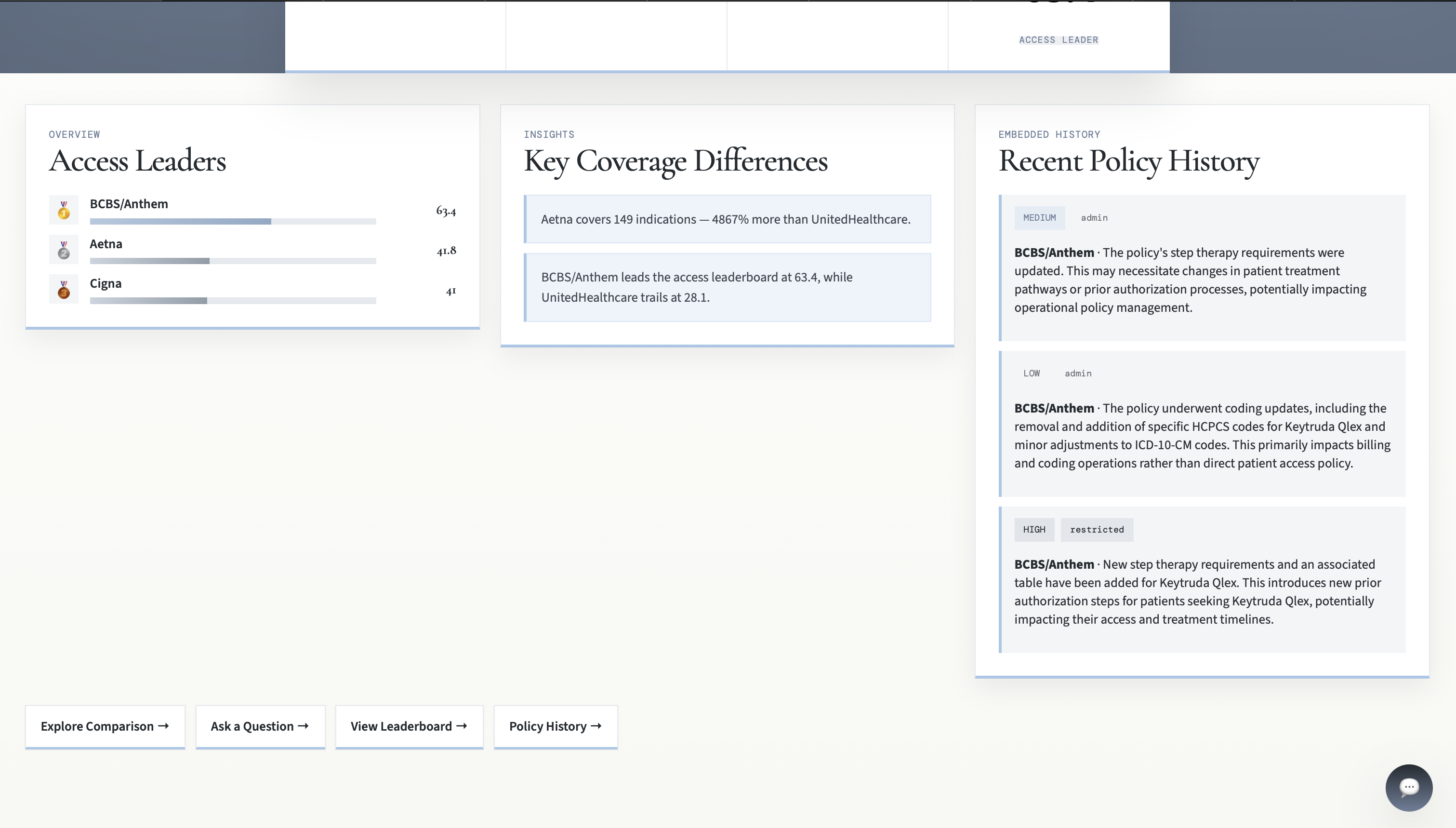
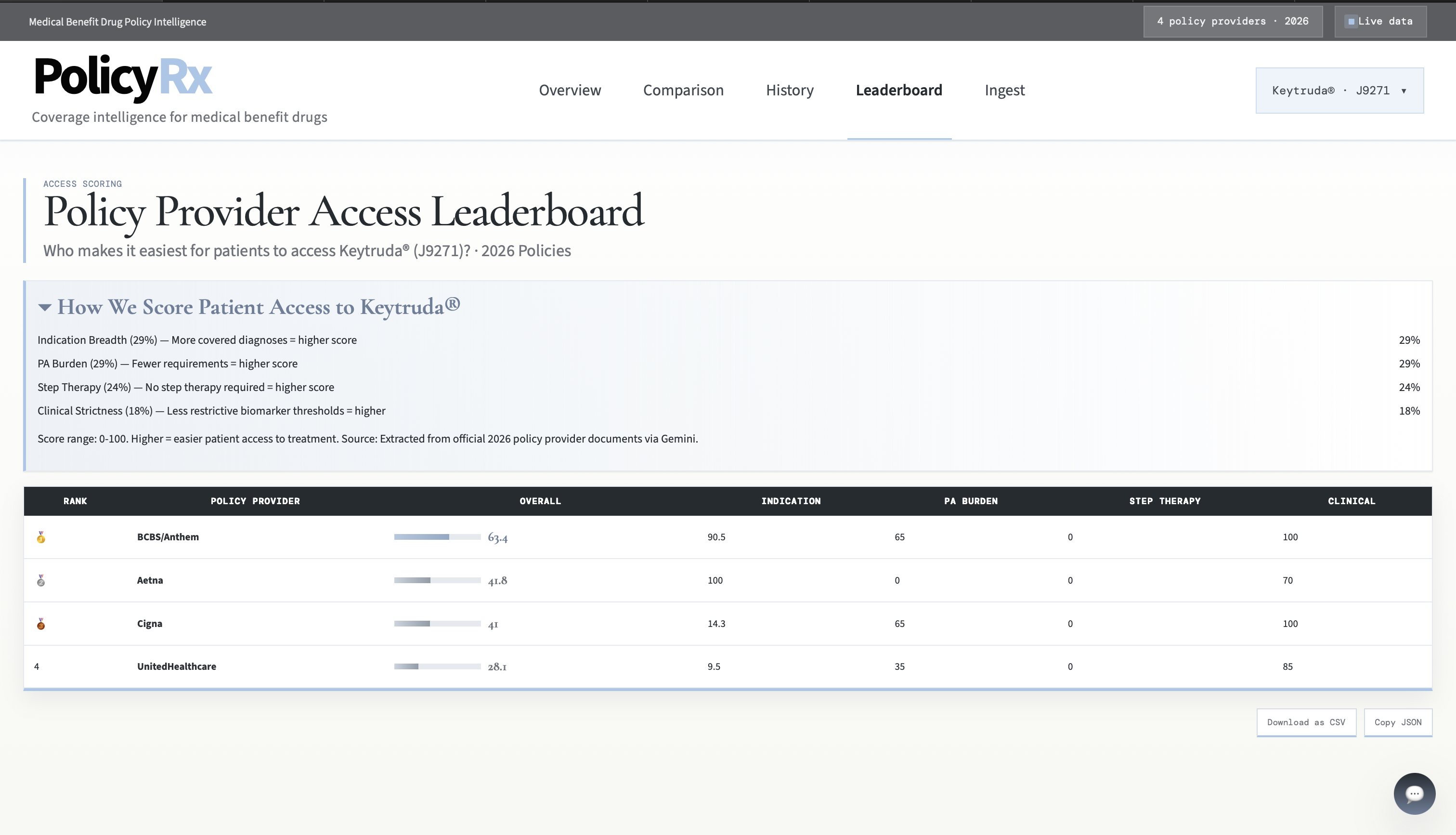
Policy Provider Leaderboard
-
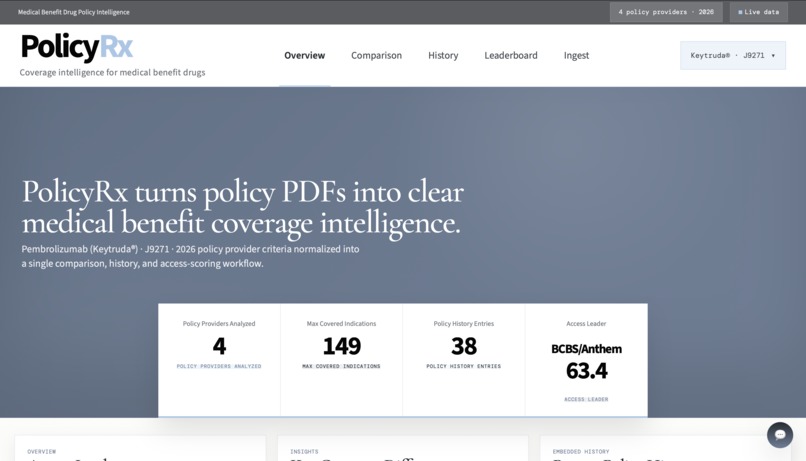
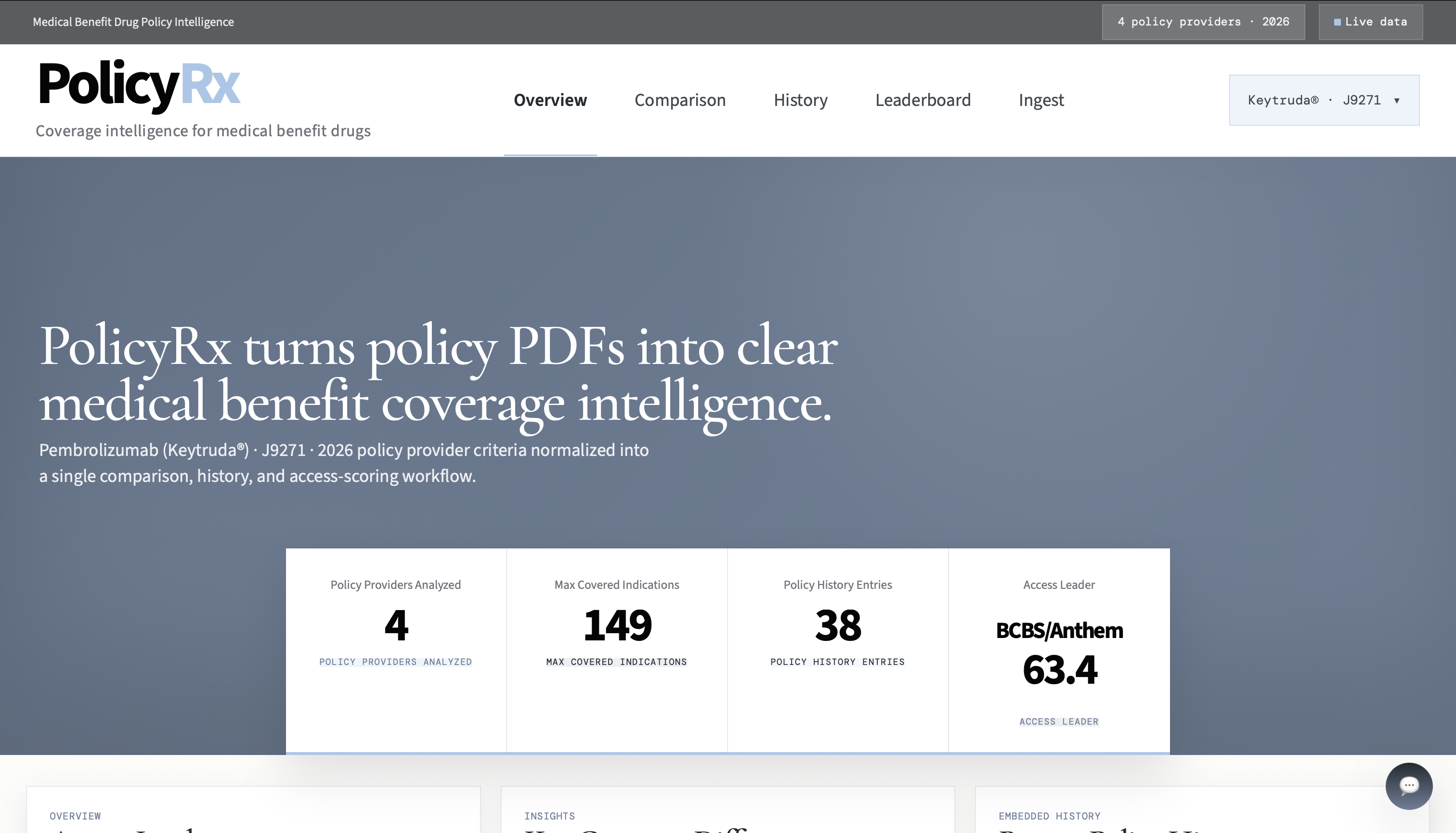
Overview
Inspiration
PolicyRx was inspired by a very real workflow problem from Anton Rx. Medical benefit drug coverage information still lives inside fragmented PDF policies, and analysts often have to read those documents manually just to answer straightforward questions like:
- Does this policy provider cover Keytruda?
- Did the criteria change this quarter?
- Which policy provider is easiest for patients to access?
There is no standardized, formulary-style source for medical benefit drugs, so we wanted to build a system that turns policy PDFs into structured, comparable intelligence.
What it does
PolicyRx ingests medical benefit policy PDFs for pembrolizumab (Keytruda, J9271) across four 2026 policy providers:
- Aetna
- UnitedHealthcare
- Cigna
- BCBS/Anthem
It then:
- extracts structured coverage information from the PDFs
- normalizes drug names and indications into comparable fields
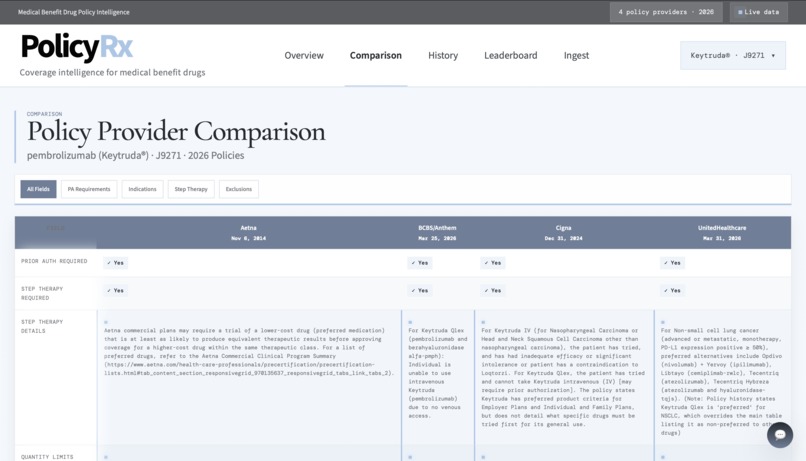
- compares policy providers side by side
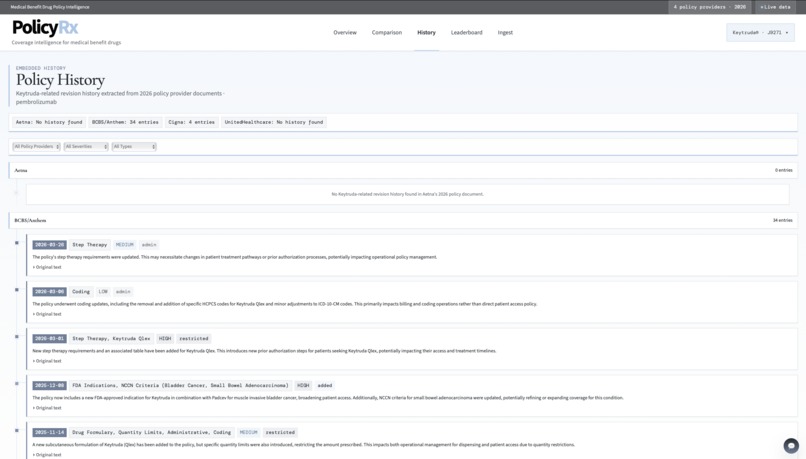
- extracts embedded Keytruda-related policy history
- ranks policy providers with an access leaderboard
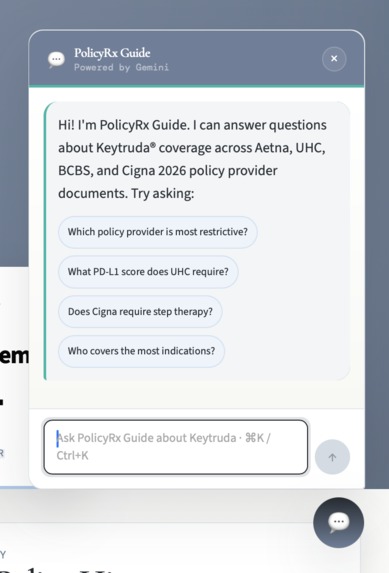
- answers natural-language questions through PolicyRx Guide, a floating chatbot
The goal is to reduce manual document review and make policy intelligence easier to search, compare, and explain.
How we built it
We built PolicyRx as an end-to-end pipeline using:
PythonFastAPISQLitepdfplumberGoogle Gemini- a single-file HTML frontend
The pipeline works in 8 stages:
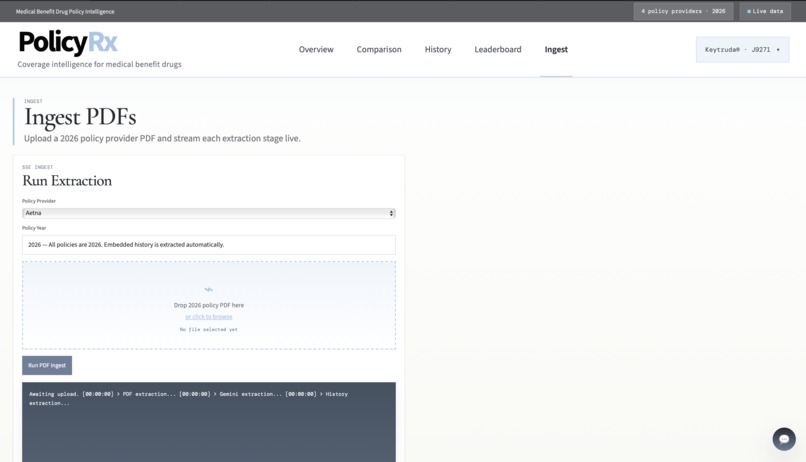
- PDF extraction with page-level text parsing
- Document-format detection
- Drug-specific text filtering
- Gemini-based structured extraction
- J-code normalization
- Indication and criteria normalization
- Storage, scoring, and deduplication
- Chunking and RAG-based policy Q&A
We also built a web interface with pages for:
- Overview
- Comparison
- Policy History
- Leaderboard
- Ingest PDFs
And we added PolicyRx Guide, a floating chatbot that lets users ask questions about Keytruda coverage without leaving the page they are on.
Challenges we ran into
One major challenge was that not all policy PDFs were structured the same way.
- Aetna and BCBS/Anthem were mostly drug-specific
- UnitedHealthcare and Cigna were broader oncology documents where Keytruda appeared inside a much larger policy
That meant we had to isolate only the relevant Keytruda sections before extraction.
Another challenge was making the output truly comparable. Raw extraction alone is not enough when different policy providers describe the same clinical idea in different language. We needed normalization layers for drug identity, indications, and PA criteria.
We also ran into challenges around keeping the history view relevant. Some documents included broad administrative revision history, so we had to filter the history down to Keytruda-related entries only.
Accomplishments that we're proud of
We are proud that PolicyRx is not just a concept demo. It is an end-to-end working system.
Some of the accomplishments we are most proud of are:
- building a full ingest-to-interface workflow
- extracting structured Keytruda coverage data from four different policy providers
- handling both drug-specific PDFs and broad oncology PDFs
- turning embedded policy revision history into a timeline view
- creating an access leaderboard from policy language
- building a clean, Anton Rx-aligned interface for non-technical users
- adding a cited chatbot experience through PolicyRx Guide
We are also proud that the product feels like a real workflow tool rather than just a backend pipeline.
What we learned
We learned that this problem is not just about using AI to summarize PDFs. The harder and more valuable part is building the structure around the extraction.
We learned the importance of:
- filtering the right sections before model calls
- normalizing medical benefit drug identity with J-codes
- converting free text into comparable clinical fields
- designing the output for usability, not just technical correctness
We also learned that stakeholders need more than extracted text. They need comparison, change tracking, prioritization, and a fast way to ask follow-up questions.
What's next for PolicyRx
The next step for PolicyRx is to scale beyond a single live drug and become a broader medical benefit policy intelligence platform.
Future directions include:
- adding more drugs beyond Keytruda
- expanding the future-scope drug dropdown into real multi-drug support
- moving from SQLite to Postgres + pgvector
- improving retrieval with embeddings
- automating policy collection and refresh
- adding alerts for major policy changes
- supporting portfolio-level monitoring for Anton Rx teams
Our long-term vision is for PolicyRx to become the structured intelligence layer for medical benefit drug coverage, replacing manual PDF review with something much faster, more comparable, and more actionable.

Log in or sign up for Devpost to join the conversation.