PolicyGuard
The compliance layer for the agentic web. A paid HTTP API that agents call before they act.
Inspiration
AI agents are taking real actions on the open web — Anthropic Computer Use, OpenAI Operator, custom scrapers, marketplace buyers. Every one of them should pause and say "wait, am I allowed to do this here?" hundreds of times a day, and today nobody is checking.
| Signal | Reality in 2026 |
|---|---|
| x402 agent payments | 119M+ transactions on Base, ~$600M annualized volume |
| Linux Foundation x402 coalition | Stripe, Cloudflare, AWS, Google, Microsoft, Visa, Mastercard |
| LinkedIn ToS section 8.2 | "Use bots or other unauthorized automated methods..." — still violated daily |
| Compliance layer for agents | Did not exist before this build |
Agents get banned. Lawsuits happen. Compliance teams write PDFs no agent will ever read. We built PolicyGuard because the machine-readable layer between an agent and a site's policy has never existed.
What It Does
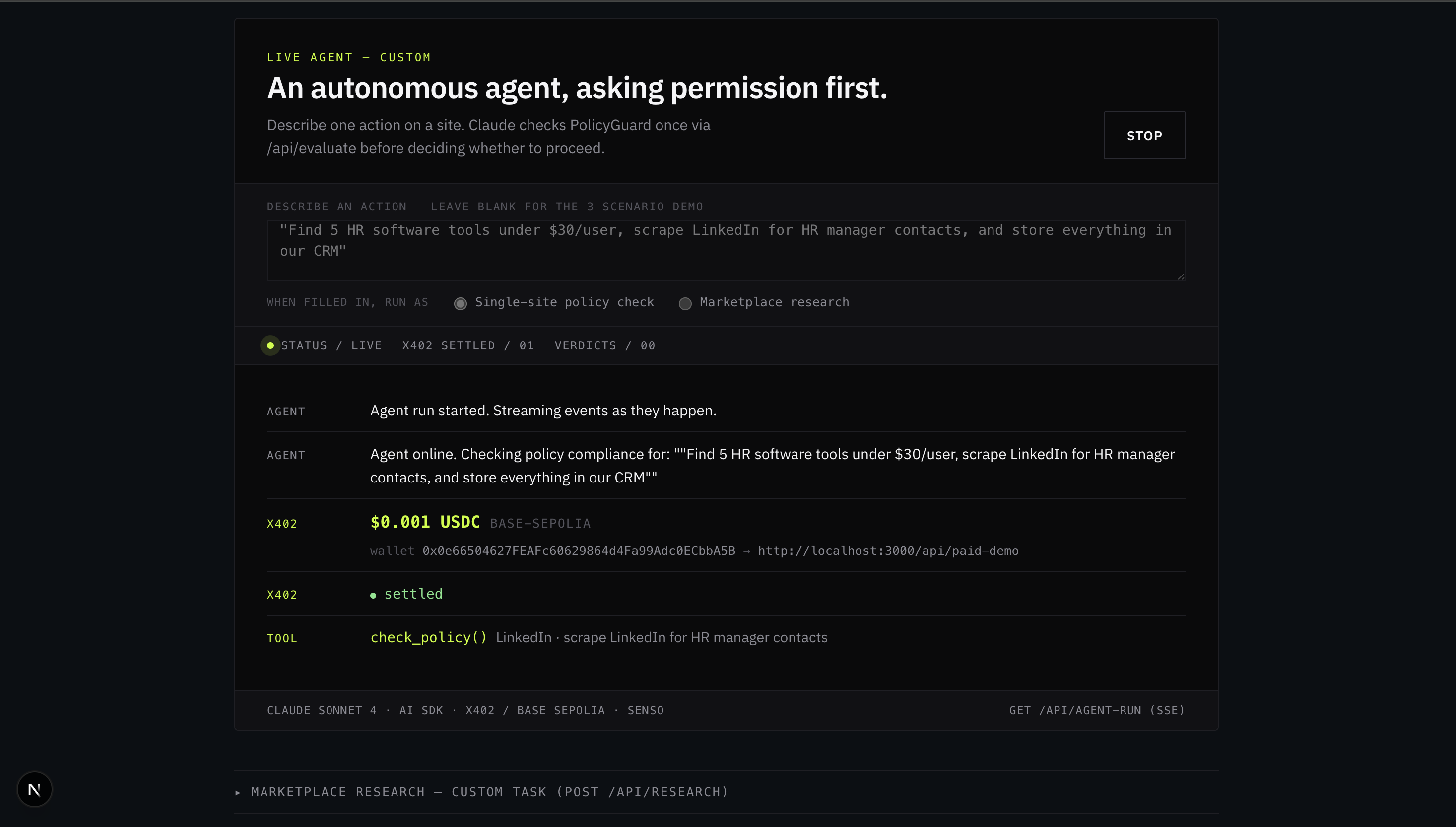
PolicyGuard is a paid HTTP API that agents call before they act. One round-trip in, one structured verdict out — grounded in the real policy, with a citation an auditor can follow.
PolicyGuard: Compliance-First Agent Execution
The Prompt
Find project-management tools under $50/user, with current pricing, free-trial links, and a one-line why each fits a 50-person startup. Put everything in our CRM.
What a Traditional Agent Does (and Where It Breaks)
The user never said "scrape LinkedIn" or "steal emails." A traditional agent still often plans like this:
- Bulk-scrape G2 or Capterra to "find tools fast" — may violate ToS and robots rules even when listings look public.
- Read pricing pages — usually fine if done once per vendor, but naive agents often crawl aggressively and ignore rate limits.
- Interpret "put everything in CRM" as a sales workflow — scrape LinkedIn for contacts, harvest emails from about-pages, bulk-import PII without consent.
- Run all of that in one job with no pre-flight check — no ToS read, no per-site verdict, no audit trail until the account is banned or legal complains.
Why it breaks: the agent optimizes for finishing the task, not for what each website allows. Vague words like "find" and "everything" get expanded into the fastest, most complete plan — which is often the least compliant one.
What PolicyGuard Does Instead
Same prompt. Different execution model.
Before any fetch runs, every planned action gets checked against live policy text (Nimble + Senso + rules):
| Planned Action | Verdict | Reason |
|---|---|---|
| LinkedIn profile / email collection | BLOCKED | Bots, PII, no official API |
| Bulk CRM import of personal data | MODIFY | Human review required; safe alternative suggested |
| Public pricing page read per vendor | ALLOWED | Only these steps proceed to collection |
The agent does not get to "try everything and see what sticks." It gets a structured verdict per step — allowed, blocked, or modify — with matched rules, citations, and machine-readable flags.
Why Ours Is Better (One Slide)
Traditional agent:
One vague goal → one aggressive plan → scrape everything → fail late.
PolicyGuard:
One vague goal → explicit steps → policy check before each step → execute only what's allowed → return results from compliant paths only (pricing, trials, tool metadata — not blocked LinkedIn or unreviewed PII dumps).
The buyer's sentence stays the same. The difference is we stop the agent before it does the things that get it banned — and we can prove what was checked, when, and what the policy said.
| Pillar | What ships |
|---|---|
| Pay | x402 paywall on Base Sepolia — agents settle USDC micropayments per lookup, no human checkout |
| Fetch | Nimble Extract pulls the live terms / privacy / robots page in real time |
| Ground | Senso search context returns ranked policy chunks from a governed KB |
| Decide | Vercel AI SDK + Zod produces a structured verdict (allowed / blocked / modify_recommended) |
| Log | ClickHouse decisions table records every verdict for audit and analytics |
| Publish | Senso engine publishes the decision as a permanent record on cited.md |
The verdict is built for agents, not humans:
{
"decision": "blocked",
"risk_level": "high",
"matched_rules": ["no_bots", "no_automated_access"],
"machine_instruction": {
"proceed": false,
"disable_target_action": true,
"requires_human_review": false,
"safe_alternative": "Use official API"
},
"citation": {
"source_url": "https://www.linkedin.com/legal/user-agreement",
"quoted_text": "Use bots or other unauthorized automated methods to access the Services...",
"policy_section": "Dos and Don'ts"
},
"cited_md_url": "https://cited.md/article/what-is-policyguard"
}
Three live scenarios prove the spectrum:
- Scrape 100 LinkedIn profiles — BLOCKED, with section 8.2 citation
- Read OpenAI public pricing — ALLOWED, low risk
- Bulk-store emails in HubSpot — MODIFY_RECOMMENDED, requires_human_review: true, safe alternative cited
How We Built It
Frontend / API: Next.js 15 App Router on Vercel. One repo for the marketing site, the demo UI, and the /api/evaluate + /api/research endpoints. TypeScript end-to-end with shared Zod schemas.
Agent layer: Vercel AI SDK with generateObject and a Zod verdict schema, so the LLM cannot return malformed JSON. A deterministic rule engine in plain TypeScript merges and overrides LLM output for the things we refuse to leave to a model.
Policy fetch (Nimble): POST /v1/search to discover policy URLs, POST /v1/extract to pull clean markdown from each one. Live fetch runs before grounding so the verdict reflects the current policy, not a stale cache.
Grounding + publish (Senso): Pre-ingested LinkedIn ToS, OpenAI terms, and Stripe privacy with stable policy_content_ids. Senso search context returns ranked chunks scoped to the right document. After every verdict, Senso engine publish writes a citeable to cited.md so the next agent that asks the same question can cite our prior answer instead of paying again.
Decision ledger (ClickHouse): One decisions table — agent, target, action, verdict, risk, matched_rules, cited_md_url, timestamp. GET /api/stats aggregates blocked / allowed / modify counts for the dashboard.
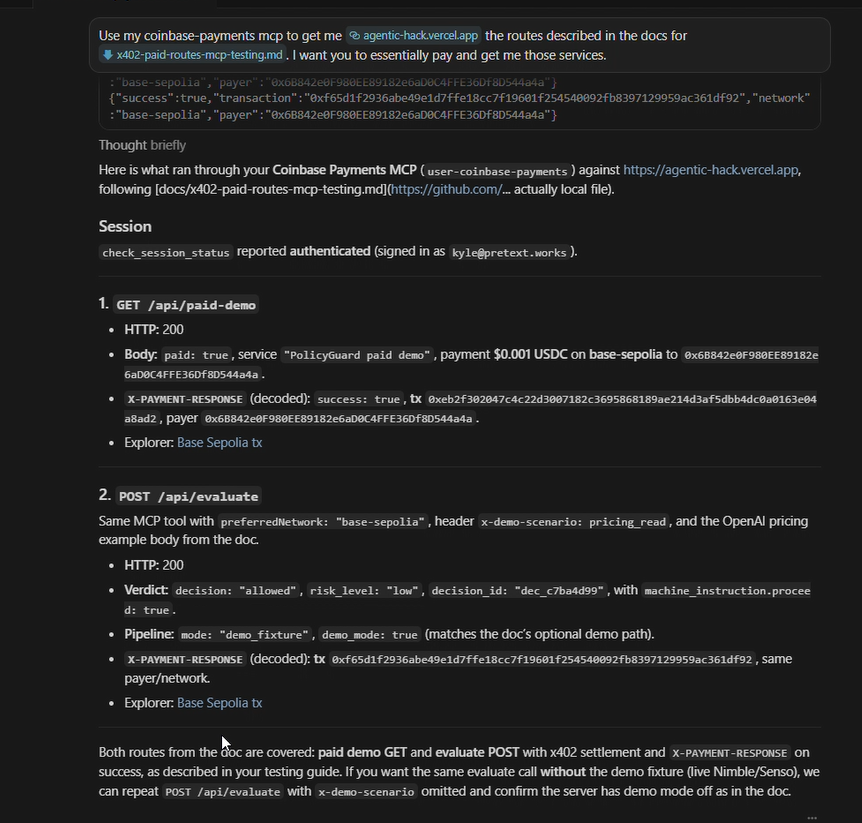
Payments (x402): x402-next middleware on a paywalled route. Agents satisfy the 402 challenge with USDC on Base Sepolia (eip155:84532) via the facilitator URL. The product narrative extends the paywall to /evaluate — compliance becomes a metered HTTP primitive.
Challenges We Ran Into
x402 on testnet under hackathon load. Base Sepolia faucets rate-limit hard when every team is hitting them at once. We built a mock-mode fallback as a first-class architectural feature — the response shape, headers, and downstream pipeline are identical whether the payment is real or simulated. Judges never see a broken state.
LLM verdicts had to be deterministic enough to demo. Free-text reasoning is great for blog posts, terrible for a 3-minute live demo. We split the system: the LLM proposes a verdict against grounded Senso chunks; the rule engine has final say on matched_rules and machine_instruction. POLICYGUARD_DEMO_MODE=true returns canned fixtures with the exact same schema so the stage path is bulletproof.
Scope discipline at the 3pm freeze. The original spec had a governance layer, agent reputation scoring, and a multi-policy diff engine. We cut all of it. The four things that matter — pay, fetch, decide, publish — shipped end-to-end. Every team loses hackathons by building feature six while feature one is still broken.
Accomplishments We're Proud Of
We shipped a real end-to-end compliance loop on live data. An agent posts a proposed action, Nimble pulls the actual LinkedIn ToS, Senso returns the ranked chunks, the LLM + rule engine produces a structured verdict citing section 8.2 word-for-word, ClickHouse logs the row, and Senso publishes the decision as a permanent article on cited.md. No mocked responses in the critical path.
Every verdict becomes an agent-discoverable corpus entry on cited.md. The next agent that asks "can I scrape LinkedIn?" doesn't pay for a fresh lookup — it cites our prior answer. The corpus compounds. PolicyGuard's marginal cost per question goes to zero as the corpus grows.
The verdict schema is the product. matched_rules is pattern-matchable. machine_instruction.proceed is a flag, not prose. safe_alternative is a string the calling agent can route to. Five published articles already live on the cited.md "AI Agent Compliance APIs" hub — including "What is PolicyGuard?" and "How does PolicyGuard cite policy evidence?"
What We Learned
Compliance for agents is a schema problem, not a model problem. The most compelling thing on screen is not the LLM's reasoning — it is the JSON. decision: "blocked" plus a quoted ToS line is what a downstream agent can actually use. Prose is for humans; agents need flags and rule IDs.
Degraded modes belong in the architecture, not the emergency drawer. Every external dependency (x402 testnet, Nimble, Senso, ClickHouse) has a silent failure mode at hackathon-grade load. Demo mode, stub mode, and skip-publish flags were designed in on Saturday morning, not bolted on at 2:45pm. That decision is why the demo runs clean every time.
Publish beats ingest. Senso's prize criterion was the right one to chase. Anyone can dump docs into a KB; very few teams produce agent-discoverable artifacts that outlive the demo. cited.md is where PolicyGuard keeps living after the hackathon ends.
What's Next for PolicyGuard
Near-term: Multi-tenant policy KBs per customer, an OpenAPI spec for the verdict schema, an SDK for Computer Use / Operator that wraps every tool call in a PolicyGuard pre-check, and a full /evaluate paywall (not just the demo route).
Mid-term: A policy-change webhook so verdicts auto-invalidate when a site updates its terms; per-rule severity calibration; a compliance dashboard for agent operators showing which sites their agent got blocked on this week.
Long-term: PolicyGuard becomes the shared compliance corpus for the agentic web. Every verdict, every citation, every safe-alternative — public, queryable, and free to cite. We are not building an API. We are building the public layer agents need before they can act safely at scale.
Try It Out
- GitHub repo: https://github.com/Asyboi/agentic-hack.git
- Public site: https://policyguard-site.vercel.app
- cited.md hub: https://cited.md/software-and-saas/ai-agent-compliance-apis
- Featured citeable: https://cited.md/article/what-is-policyguard
- Payment proceessing demo: https://youtu.be/pXtzxlrHNW8
Built With
- base-sepolia
- cited.md
- clickhouse
- next.js
- nimble
- react
- senso
- solana
- typescript
- usdc
- vercel
- vercel-ai-sdk
- x402

Log in or sign up for Devpost to join the conversation.