Inspiration
Every year, hospitals lose hundreds of millions of dollars not because care was denied — but because insurance payers like UnitedHealthcare, Aetna, Cigna, and Humana quietly update their Clinical Policy Bulletins, prior authorization rules, and medical-necessity criteria. By the time a billing team discovers the change, it's already too late: claims are denied, appeals take months, and revenue is gone.
The problem isn't a lack of data — payer policies are public documents. The problem is that nobody is watching them systematically, and even when a change is spotted, no one is translating it into dollar-denominated risk before it hits the revenue cycle. We built PolicyDiff to close that gap.
What It Does
PolicyDiff is an AI-powered payer policy monitoring system that detects coverage changes before hospitals feel the financial impact.
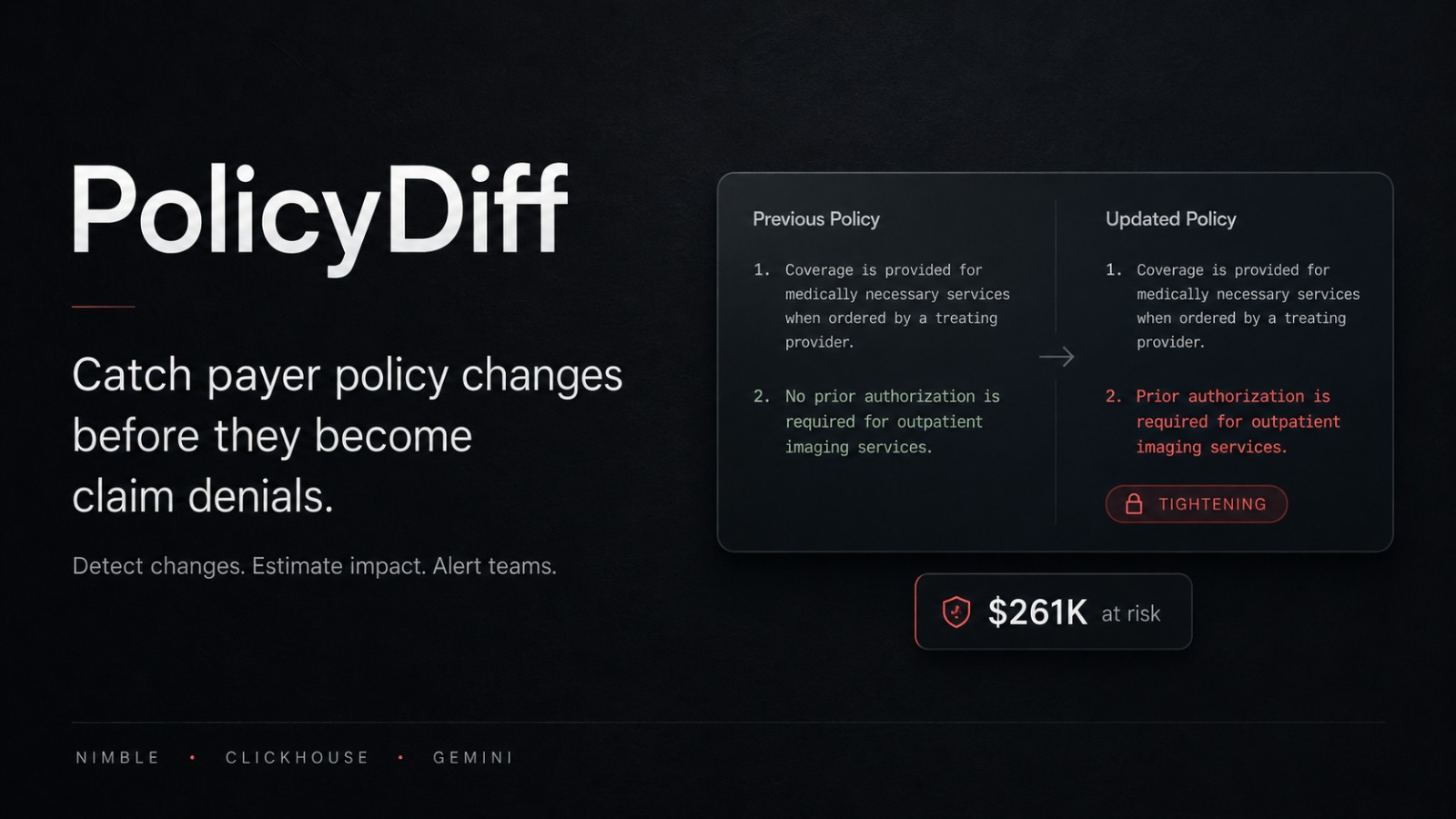
It continuously scrapes policy documents from major payers, detects meaningful version changes, and uses Gemini AI to classify them — tightening, loosening, scope change, or stylistic. It then maps each change to CPT billing codes, computes annualized revenue at risk, and surfaces everything in a live dashboard with AI-generated evidence briefs.
When PolicyDiff detects that UnitedHealthcare tightened its Cardiac MRI criteria, it doesn't just flag it. It outputs: "This affects CPT 75561, creates $792K in annualized revenue risk, and here is the cited evidence brief." Billing and coding teams can act on it immediately — before a single claim is denied.
How We Built It
PolicyDiff is a three-service microarchitecture built in parallel by three engineers.
Ingestion Service uses Nimble to scrape HTML and PDF policy documents from payer websites on a rolling schedule. It normalizes raw text into a canonical format, computes a content hash per document, stores every version in ClickHouse, and writes a diff_candidate row whenever a meaningful change is detected.
Classifier Service polls ClickHouse for pending diff candidates and sends old vs. new policy text to Gemini 2.5 Flash for classification. It categorizes each change, extracts the changed clause and CPT codes, computes annualized revenue at risk from historical claims data, publishes AI-generated evidence briefs to Senso, and traces every LLM call through Datadog LLM Observability. An APScheduler polls continuously so every new diff is classified within seconds.
API & Dashboard Service is a FastAPI backend backed by a Next.js frontend. It reads classified change events from ClickHouse and displays a live feed of policy changes with revenue risk breakdowns by payer, service line, and change type. It includes a demo trigger, inline markdown evidence viewer, and system health status.
All three services share a cloud ClickHouse instance on AWS, wired together through a shared schema.
Challenges We Ran Into
ClickHouse CANNOT_UPDATE_COLUMN — The initial diff_candidates table had status in the ORDER BY key, which meant ClickHouse blocked all ALTER TABLE ... UPDATE mutations on it. We had to switch from mutation-based status updates to a delete + reinsert pattern to correctly mark records as processed.
Gemini API model availability — The spec called for gemini-2.0-flash, but that model had a 0/0/0 rate limit on the free tier. We had to discover this at runtime, enumerate available models, and switch to gemini-2.5-flash — which required figuring out the correct model name format for the new google-genai SDK after the older google-generativeai was deprecated.
Datadog agentless mode — The initial Datadog setup sent traces to a local agent on port 8126, which wasn't running. Getting LLM Observability to work in a local dev environment without a Datadog Agent required enabling DD_LLMOBS_AGENTLESS_ENABLED=1 and adding manual span annotations, since the new google-genai SDK isn't in ddtrace's auto-instrumented library list.
ClickHouse HTTP multi-statement SQL — The HTTP interface rejects multi-statement SQL files, so we had to split every schema migration into individual statements and apply them one by one.
Senso API endpoint discovery — The Senso REST API returned 404 on every endpoint we tried. We had to install and use the Senso CLI instead, then wire the published URLs back into our pipeline.
Cross-engineer integration on a shared cloud DB — When Engineer A moved to a cloud ClickHouse instance on AWS with SSL, the other services were still pointing to localhost. Wiring SSL (CLICKHOUSE_SECURE, CLICKHOUSE_VERIFY) and discovering that the recommended_action column referenced by the dashboard wasn't in the schema required quick coordination and a mid-session migration.
Vercel deployment constraints — Deploying the Python classifier to Vercel's Hobby plan required removing ddtrace and uvicorn from requirements (incompatible with Vercel's serverless runtime), switching from APScheduler to Vercel's daily cron, and adding explicit sys.path manipulation and includeFiles config to bundle the app package correctly.
Accomplishments We're Proud Of
- End-to-end AI pipeline running live — Nimble fetches a real payer policy, Gemini classifies the change at 0.98 confidence, revenue at risk is computed ($792K for a single Cardiac MRI policy change), and the result appears in the dashboard in seconds.
- Full observability — every Gemini call is traced in Datadog LLM Observability with workflow spans, LLM spans, input/output annotation, and model metadata.
- Three independent services merging cleanly with no schema conflicts on a shared cloud ClickHouse instance.
- AI-generated evidence briefs published to Senso with inline markdown fallback so the dashboard always has content to display, even before the Senso URL is populated.
What We Learned
The hardest part of building a multi-service AI pipeline isn't the AI — it's the plumbing. Getting three independent services to agree on a shared data contract (table schemas, column names, status values) under time pressure required clear ownership boundaries and placeholder strategies so no engineer was blocked.
AI model availability on free tiers is not a given — the model named in a spec may have a 0/0/0 rate limit, and you need to enumerate what's actually accessible before your pipeline can run. Building retry logic and graceful degradation around LLM calls isn't optional.
On the observability side: running ddtrace in an environment without a local Datadog Agent is a common footgun. Agentless mode and manual span annotation are the path forward for local dev and serverless deployments.
What's Next for PolicyDiff
- Senso cited.md URLs — completing the Senso org content generation pipeline to give every change event a publicly linkable evidence brief.
- x402 payment flow — gating full evidence packet exports behind a micropayment for revenue-cycle teams who want exportable PDFs.
- Luminai webhook routing — automatically pushing high-risk tightening events into clinical workflow tools so the alert reaches the right person without anyone having to check a dashboard.
- Broader payer watchlist — expanding beyond UHC, Aetna, Cigna, and Humana to cover regional payers and specialty-specific policies.
- Alert thresholds — email or Slack notifications when a change exceeds a configurable revenue-at-risk threshold, so teams don't need to monitor the dashboard continuously.

Log in or sign up for Devpost to join the conversation.