-
-

PolicyDiff logo
-
Dashboard
-
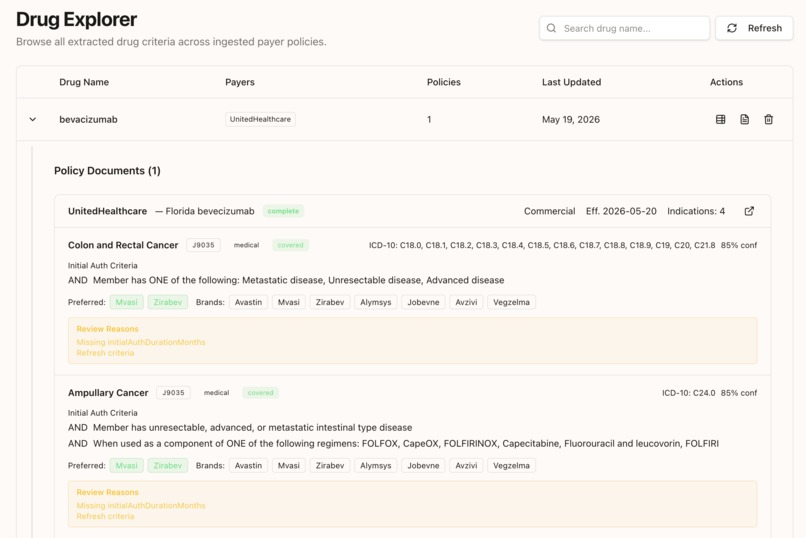
Drug Explorer
-
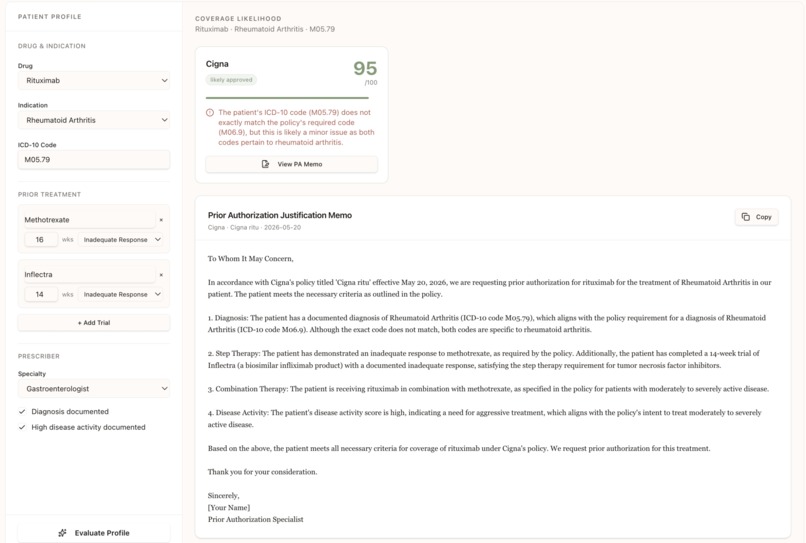
Approval Path Generator Score a patient profile against extracted payer criteria and generate a PA memo.

PolicyDiff
Inspiration
It started with a number that honestly made us mad.
Three days. That is how long an Anton RX consultant can spend on a single drug policy update. Three full days reading PDFs from UnitedHealthcare, Aetna, and Cigna, highlighting step therapy rules in different colors, copying dosing limits into spreadsheets one cell at a time, and trying to figure out what changed since last quarter by comparing two printed documents side by side.
Three days for one drug. And there are hundreds.
The moment it became real for us was when we heard about a patient on Remicade who got denied because one payer had quietly added a biosimilar-first requirement. The update was buried deep in the document and nobody caught it until the prior auth came back rejected. That stuck with us. This was not just annoying admin work. It was the kind of broken system that directly affects whether patients get treatment on time.
So we asked a simple question: what if AI could actually understand these policies the way a pharmacist or reimbursement consultant does?
Not just summarize them. Not just chunk them into embeddings. Actually understand the difference between "all of the following" and "one of the following," track which drugs have to fail first, and catch when a payer quietly makes access more restrictive.
None of us had worked with medical benefit policy documents before. None of us had built on AWS before. We had three nights, a Bedrock API key, and a strong feeling that this process should not be this painful.
That was enough.
What it does
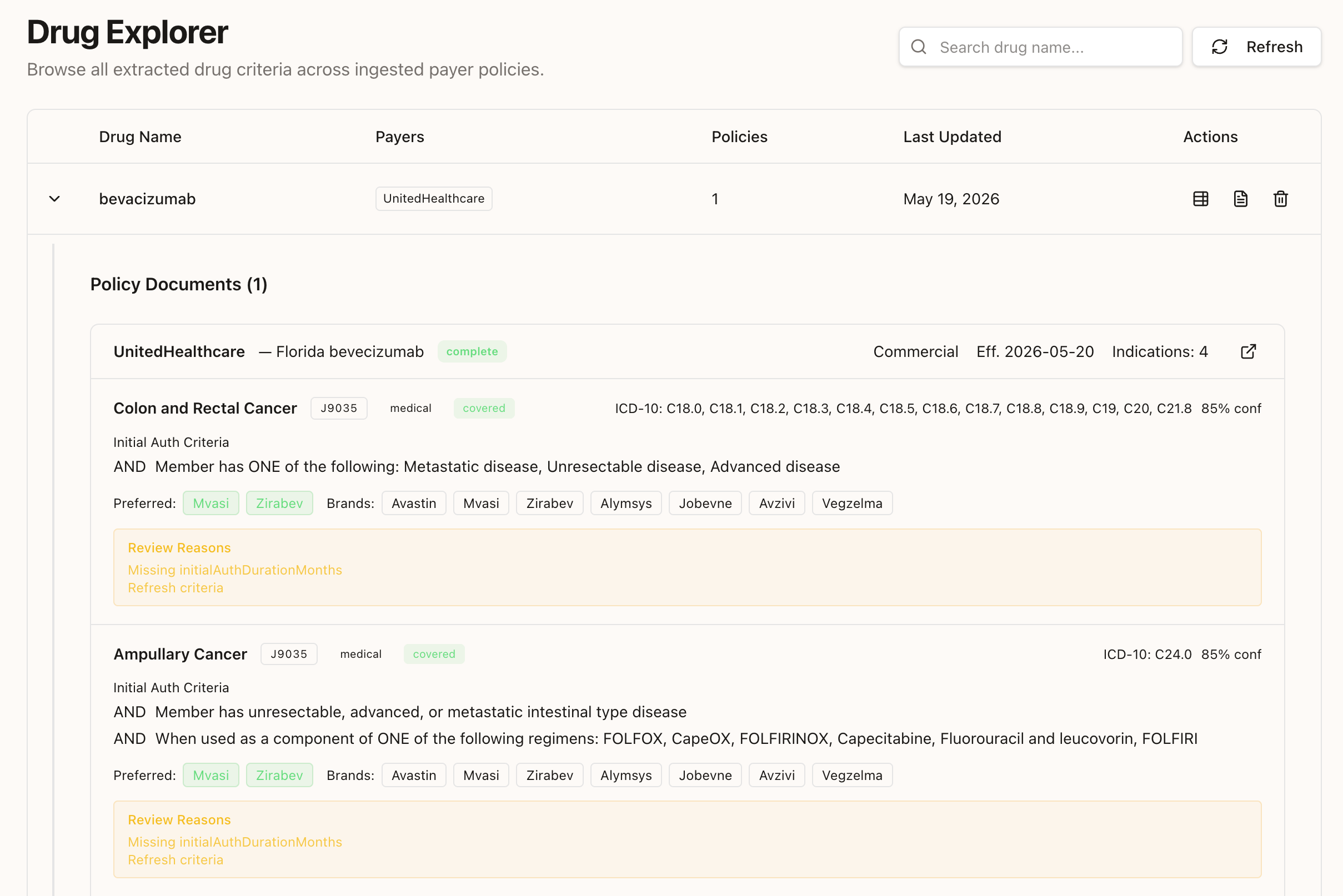
PolicyDiff takes a dense medical benefit drug policy PDF and turns it into structured, searchable, comparable data in seconds.
Upload a policy for something like infliximab, and the system extracts the important parts: drug and indication pairs, step therapy requirements, dosing limits, preferred product rules, prescriber restrictions, and other access criteria. Then it stores everything in a normalized format so policies from different payers can finally be compared side by side.
That comparison view is where it really clicks.
Pick a drug and indication, like infliximab for rheumatoid arthritis, and PolicyDiff shows UHC, Aetna, and Cigna in one color-coded table. The most restrictive payer is highlighted in red. The least restrictive is green. If one payer requires a 14-week biosimilar trial, another requires 12 weeks, and a third has no step therapy at all, you see it instantly.
What used to take three days now takes a few seconds.
We also built a temporal diff engine. When a new version of a policy is uploaded, PolicyDiff compares it field by field against the previous one and flags what changed. If coverage got removed, if documentation got stricter, if a new step therapy rule got added, it tells you exactly what changed and how severe it is.
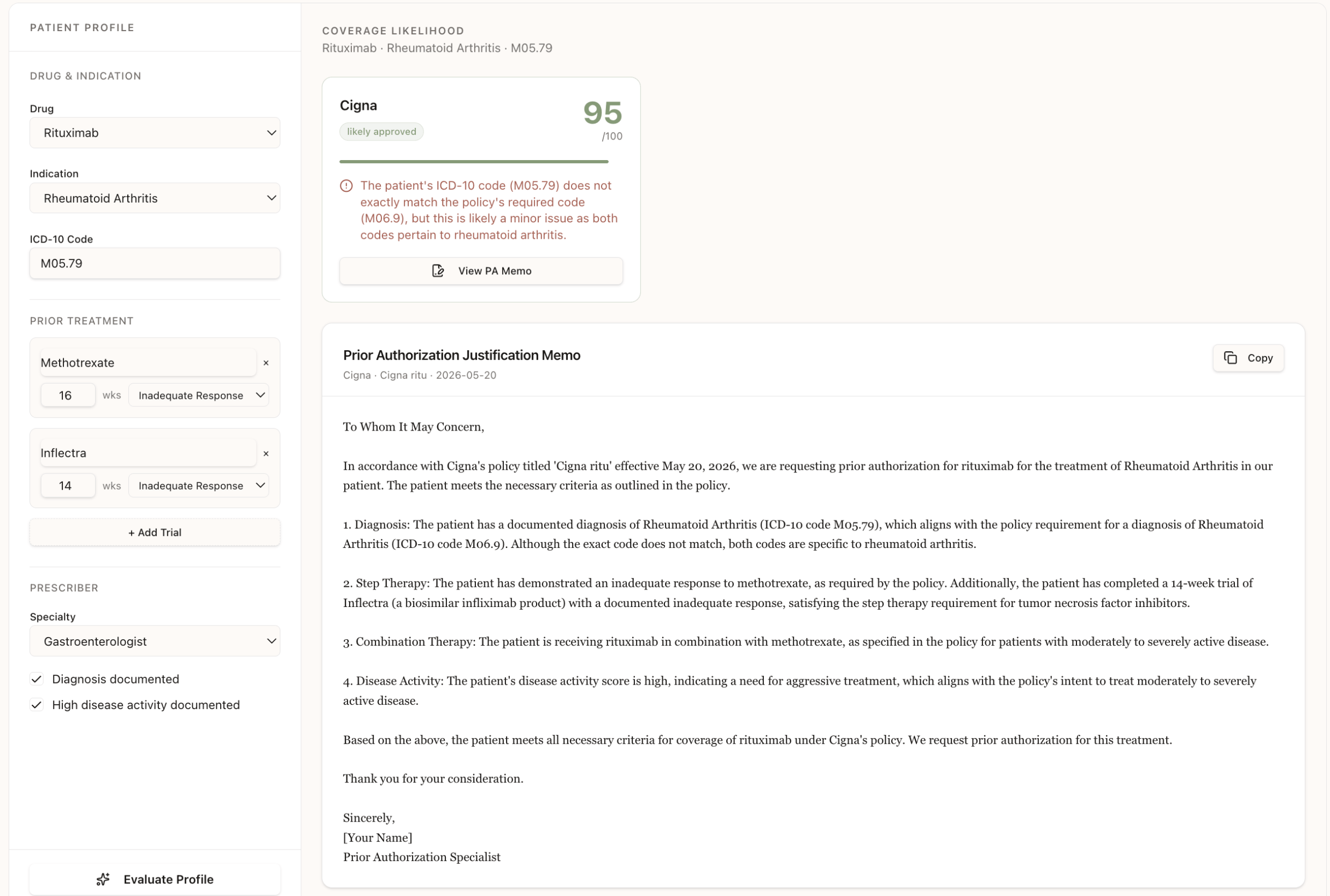
And the feature we are most excited about is the Approval Path Generator.
Given a patient profile, diagnosis, prior therapies, labs, prescriber specialty, the system estimates how well that patient matches each payer's criteria, identifies the gaps, and generates a prior authorization memo written in that payer's own language. Not generic filler text. A memo that maps the patient's case directly to the policy criteria by name.
Something a consultant could actually use the next morning.
How we built it
The first thing we learned was that there was no such thing as a universal extraction prompt.
Each payer writes policies differently, and those differences matter a lot. UHC has its own structure and logic patterns. Aetna frames criteria differently and sometimes routes review through delegated entities like EviCore or Evolent. Cigna nests criteria deeply and places AND and OR logic in ways that are easy to misread if you are not careful.
So instead of forcing one prompt to do everything, we built separate extraction templates for each payer.
Our backend runs entirely on AWS. PDFs land in S3. That triggers a Step Functions Express Workflow that runs the extraction pipeline. Textract pulls structure-aware text, a Lambda reconstructs hierarchy from the raw blocks, and Bedrock Claude Sonnet handles payer-specific extraction into structured policy records. We added a verification layer to cross-check outputs and flag low-confidence results for review. Everything gets stored in DynamoDB with indexes designed for fast cross-payer comparison.
One of the biggest technical problems was token overload. Some of these policy documents are huge, and feeding the entire thing into one model call gave poor results. The model would blur criteria across indications or invent details that were not there.
So we changed the approach. We chunked the text by indication section before extraction, then used semantic retrieval for question answering. We embedded curated excerpts instead of raw document noise, so the model only saw the most relevant sections at query time.
That one change improved both accuracy and efficiency in a big way.
On the frontend, we used Next.js 14, AG Grid for the comparison matrix, TanStack Query for status polling, Recharts for visualizations, and shadcn/ui for fast component building. The goal was to make it feel like an actual workflow product, not just a hackathon demo pretending to be one.
Challenges we ran into
The first wall we hit was IAM.
We lost hours on night one trying to figure out why one of our Lambdas could not call the model. The error message was technically correct but not useful. The issue ended up being that we had scoped the role to the wrong model ARN format. It was a tiny config mistake that took way too long to find, mostly because we were learning AWS in real time.
The harder challenge, though, was document logic.
Textract gives you blocks. It does not give you meaning. It does not know which line is a section header, which one is a nested criterion, or when a standalone AND changes the interpretation of everything below it. We had to build our own hierarchy reconstruction layer using formatting, indentation, and positional data just to recreate the structure a human reader sees naturally.
And then came the boolean logic problem.
This was the part that almost broke the project. In these policies, the difference between AND and OR is the difference between a patient qualifying for treatment or getting denied. Our first generic extraction approach got that wrong far too often. Once we stopped pretending the documents were all the same and started writing payer-specific prompts, accuracy jumped immediately.
Also, sleep deprivation is a very real engineering risk.
At one point we accidentally used the drug name as a database key, which meant one payer's infliximab policy overwrote another's. Later we had a timezone bug that made every temporal diff look unchanged. The fix was tiny. Finding it while running on coffee and three hours of sleep was not.
Accomplishments that we're proud of
The biggest thing we are proud of is that the core workflow actually works on real data.
This was not a polished UI sitting on top of hardcoded JSON. We used real UHC, Aetna, and Cigna policy documents, processed them through our actual pipeline, stored the extracted criteria, and rendered real comparisons in the app. When you see one payer marked more restrictive than another, that came from the source PDFs.
We also surfaced a real medical versus pharmacy benefit discordance in a major drug policy. Same drug, same payer, different benefit channel, different access rules. That was exactly the kind of thing this system is meant to uncover, and seeing it happen for real was a huge moment for us.
The other big win was prompt quality. The payer-specific templates took time, but they were worth it. Once we stopped treating policy extraction like a generic summarization task and started treating it like domain-specific logic parsing, the system got dramatically better.
And the Approval Path Generator felt like the moment the product stopped being just an analysis tool and started becoming something operational. It did not just explain policy. It turned policy into action.
What we learned
The biggest lesson was that domain-specific AI is a different game.
You cannot throw a complicated medical policy PDF into a model and hope for reliable output. These documents contain structure, hierarchy, exceptions, and logic that actually matter. If the model gets one relationship wrong, the downstream consequence is not a bad summary. It is a bad decision.
We also learned that input quality matters more than brute force. Our early instinct was to use bigger context and more tokens. What worked better was cleaner inputs, better structure, and retrieval over curated excerpts.
And maybe the most hackathon-specific lesson was this: when time is brutally limited, clarity wins. We stopped overthinking architecture and focused on one question the whole weekend: does this help the demo and does it solve the real problem? If yes, build it. If not, cut it.
That pressure made the product simpler and sharper than it would have been otherwise.
What's next
The immediate next step is expanding payer coverage.
UHC, Aetna, and Cigna are a strong start, but there are many more major payers with their own formatting quirks and policy logic. The good news is that the schema holds up. Once we map a new payer's document style, we can build and validate an extraction template pretty quickly.
After that, the obvious next move is automated monitoring. Right now, PolicyDiff depends on someone manually uploading a policy. But these documents are published at predictable URLs and updated on a regular cadence. If we automatically detect updates and trigger ingestion, PolicyDiff becomes a continuous surveillance system instead of a point-in-time tool.
The stretch feature we did not get to, but still really want to build, is a Policy Simulator. The idea is simple: take a real payer policy, change one access rule, and instantly see how that hypothetical version compares against the market. That opens up a much more strategic use case around market access and formulary decision-making.
And the long-term vision is to close the loop completely.
Not just analyze policies. Not just generate the memo. Actually plug into the workflows providers already use so the output can move directly toward submission.
From policy PDF to prior auth action in one continuous pipeline. That is the product we want to build.
Built With
- ag-grid
- amazon-bedrock
- amazon-dynamodb
- amazon-eventbridge
- amazon-textract
- amazon-web-services
- auth0
- aws-api-gateway
- aws-cdk
- aws-lambda
- aws-step-functions
- css
- git
- github
- html
- javascript
- next.js
- nova-2-pro
- prompting
- python
- regex
- shadcn/ui
- tailwind-css
- typescript
- vectorless-search

Log in or sign up for Devpost to join the conversation.