
Inspiration
Internal policies live in PDFs and Markdown that nobody re-reads until something goes wrong. Generic chatbots sound confident but can hallucinate on compliance. We wanted a tool that behaves like a careful colleague: if it cannot point to a line in your document, it refuses to guess.
What it does
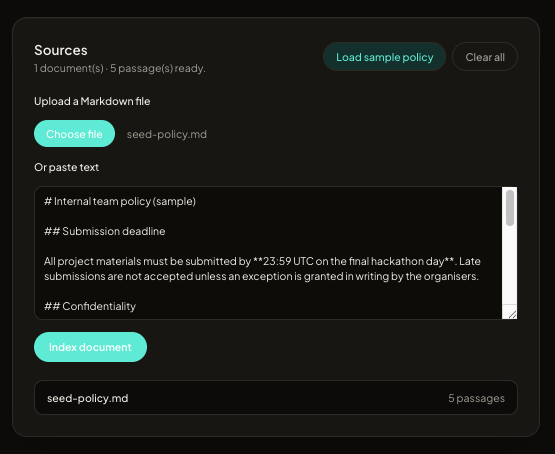
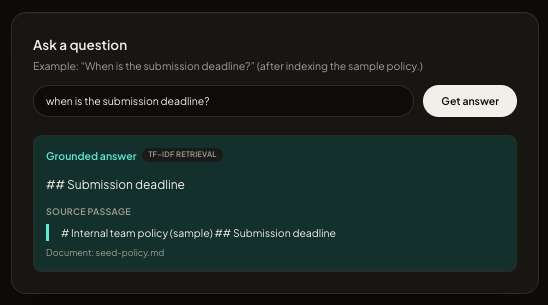
Policy Compass is a web app for citation-backed Q&A over uploaded policy text. Users add Markdown (or paste text), ask a question in natural language, and receive:
- a short grounded answer derived from the retrieved passage, and
- a verbatim source passage plus document name.
Retrieval combines open-source sentence embeddings (Hugging Face Inference API, default sentence-transformers/all-MiniLM-L6-v2) with a TF–IDF fallback so the demo still works without external calls. Passages and optional vectors persist in SQLite for the MVP; we describe PostgreSQL for production scale in our roadmap.
Optional math (retrieval): cosine similarity on L2-normalised embedding vectors can be written as
$$\cos(\theta) = \mathbf{\hat{q}} \cdot \mathbf{\hat{d}}$$
when both vectors are unit length—so scoring reduces to a dot product over the passage index.
How we built it
- Frontend: Next.js 15 (App Router), React 19, TypeScript, Tailwind CSS v4, polished UI with clear “embedding vs TF–IDF” feedback.
- Backend: Route handlers for document ingest, question answering, seed content, and non-secret
/api/meta. - Chunking: Markdown-aware splitting so headings do not detach from the body text (better quotes).
- Data:
better-sqlite3with documents + passage rows + optionalembedding_json. - Privacy / EU angle: in-repo privacy notes; no accounts in the MVP; subprocessors documented when HF is enabled.
Challenges we ran into
- Trust vs fluency: Making “no evidence” a first-class outcome instead of a vague answer.
- Chunk quality: Early versions merged headings incorrectly; we fixed heading/body chunking so deadlines appear in citations.
- Retrieval modes: Tuning when to prefer semantic (embedding) vs lexical (TF–IDF) scores and keeping the demo reliable if HF is slow or unrated.
- Environment gotchas:
.envcomments (#) accidentally disablingHF_TOKEN; we documented “active line vs comment” clearly.
Accomplishments that we're proud of
- A clear product story: Enterprise theme with audit-friendly citations, not generic chat.
- Working end-to-end MVP: ingest → persist → ask → grounded answer with source.
- Honest architecture: SQLite for hackathon speed, explicit path to Postgres for real deployments.
What we learned
- RAG quality is mostly chunking + evaluation, not only the fanciest model.
- Fallbacks matter for demos (TF–IDF when embeddings are unavailable).
- Small UX details (badges, privacy copy, sample files) build trust with judges and users.
What's next for Policy Compass
- Auth and workspaces (SSO, per-team corpora).
- PostgreSQL + pgvector (or equivalent) for multi-tenant production.
- Stronger evaluation harness and optional reranking for high-stakes policies.
Team
- Kamil Piejko — Full stack: Next.js UI, API routes, architecture, retrieval logic (TF–IDF / embeddings, similarity scoring).
- Mateusz Grabowski — Product direction, coordination, embeddings & Hugging Face integration support.
- Joanna Pich — Presentation narrative, UI/UX polish and demo flow.
Built With
- api
- markdown
- next.js
- node.js
- rag
- react
- sentence-embeddings
- sqlite
- tailwind
- tf-idf
- typescript


Log in or sign up for Devpost to join the conversation.