-
-

Logo
-
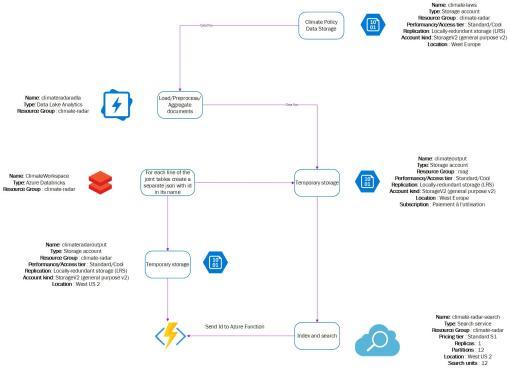
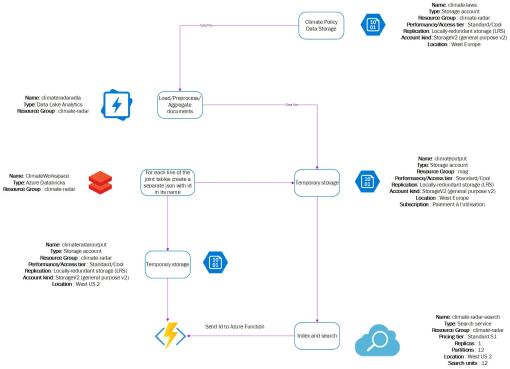
How it works

Inspiration
The climate crisis is accelerating at an unprecedented rate, and we are not ready for it. While the crisis has many factors that play a role in its exacerbation, there are some that warrant more attention than others. Poor governance is one of them. According to economists like Nicholas Stern, the climate crisis is a result of multiple market failures. Economists and environmentalists have urged policymakers for years to increase the price of activities that emit greenhouse gases (one of our biggest environmental problems), the lack of which constitutes the largest market failure, for example through carbon taxes, which will stimulate innovations in low-carbon technologies. Policymakers still face huge uncertainty regarding their choices and don’t know what policy instruments to employ, and which ones will be most effective. We were challenged by the startup Climate Policy Radar to develop solutions to querying full-text documents in the global climate legislation database.
What it does
For this hackathon, we have created an Azure search engine based on the legislation documents (legislation, laws, and events) and added cognitive skills to it (extraction of names, locations, entities). This allows performing full-text research by expressing a request in a natural language. For instance, "What events are the laws NNN focusing on?" The next step is to extend the understanding of the request by adding the Knowledge Graph, for a better query mapping.
How we built it
By using powerful technologies such as Python, frameworks: Sematic (Semantic Entity Similarity Framework), Platform: Azure, cloud services: Azure Cognitive Search, database: no database, we only used Azure Storage Account, API: a search engine is published as a RESTful API.
Challenges we ran into
Querying a list of entities from these heterogeneous structured KGs is challenging as we needed to master the syntax of a structured query language (such as SPARQL) and to acquire sufficient knowledge of the underlying ontology (schema and vocabulary).
Accomplishments that we're proud of
We've now a clear understanding of the data structure and of the ways it may serve the environmentalist's needs. We are very proud of our architecture, which seems to reveal the technical implementation of our solution, and will allow us to keep working on the project even after the hackathon.
What we learned
We've learned some frameworks for semantic entity search in SRTQ (Single Relation Type-based Queries) over heterogeneous KGs (Knowledge Graphs).
What's next for Poli Radar
The next step is to extend the understanding of the request by adding the Knowledge Graph, for a better query mapping. Furthermore, more researches will be followed in refining the semantic similarity-based type expansion algorithm to optimize both the execution time and search performance.







Log in or sign up for Devpost to join the conversation.