-
-
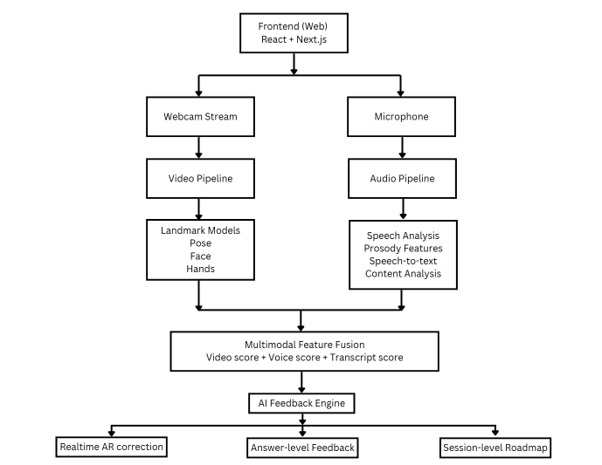
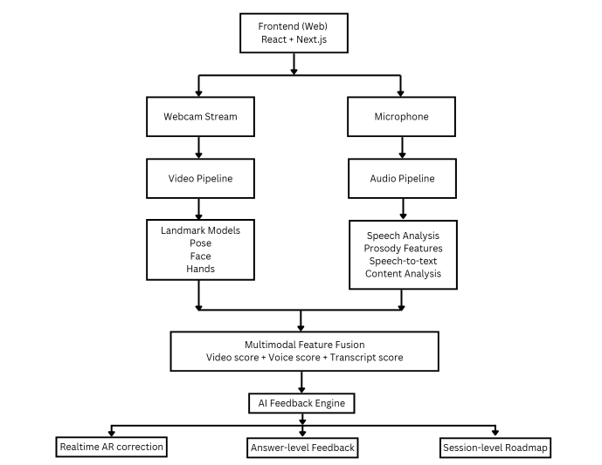
App workflow (details in AI Architecture section)
-
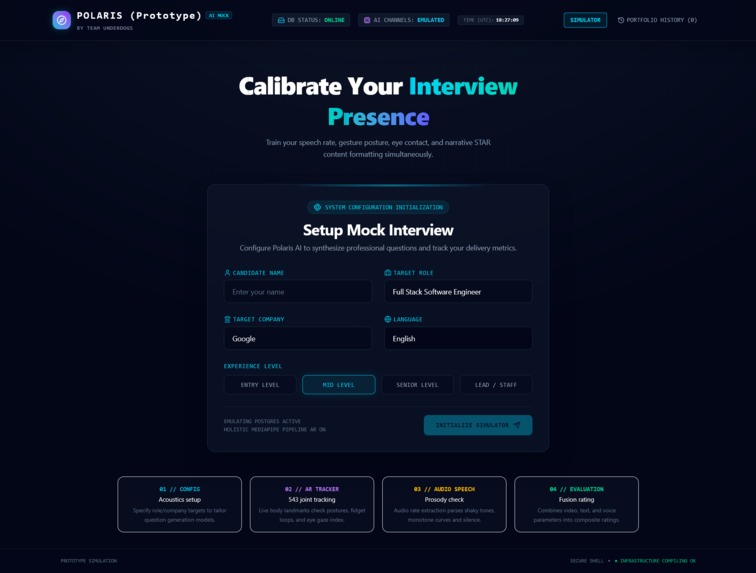
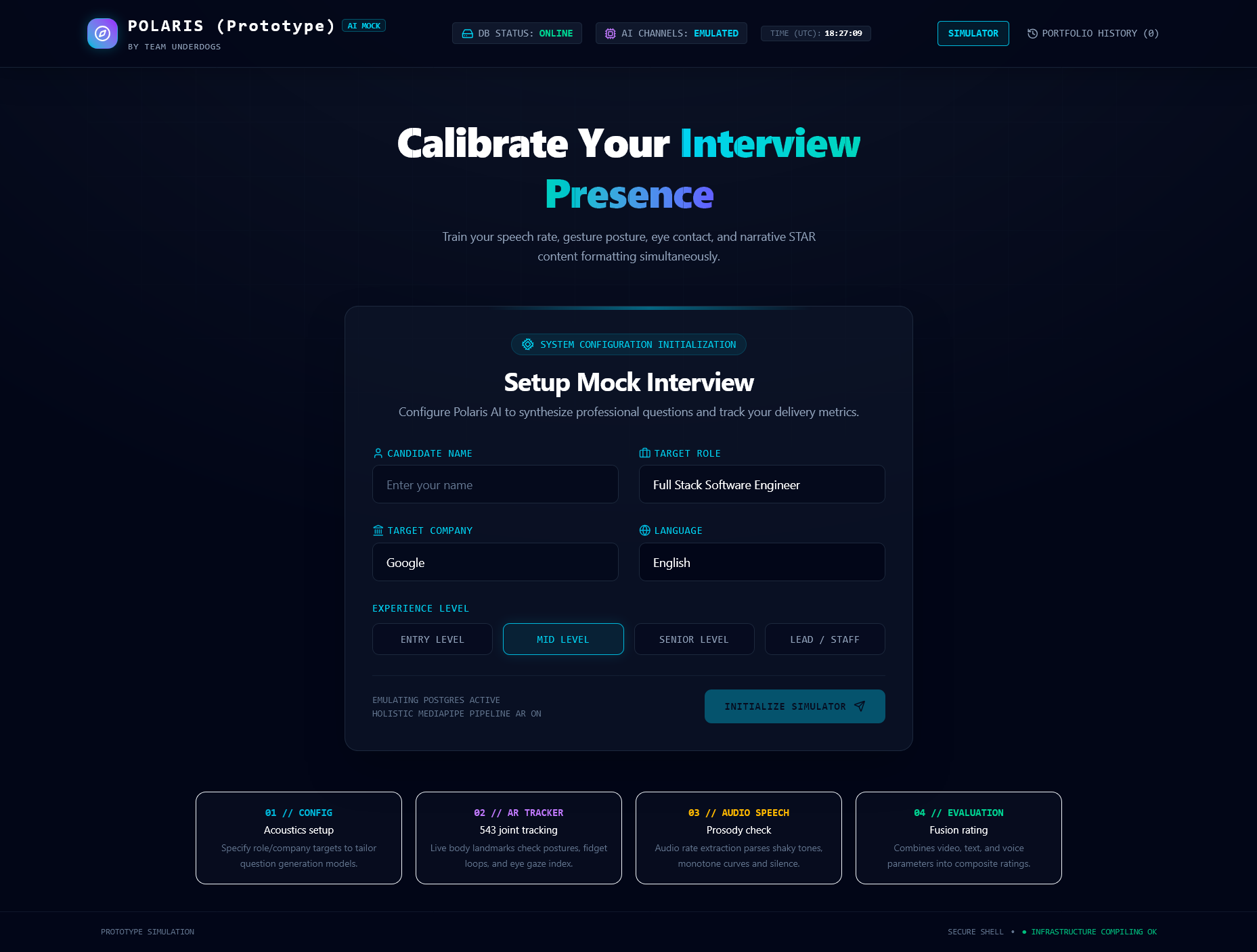
Home Page
-
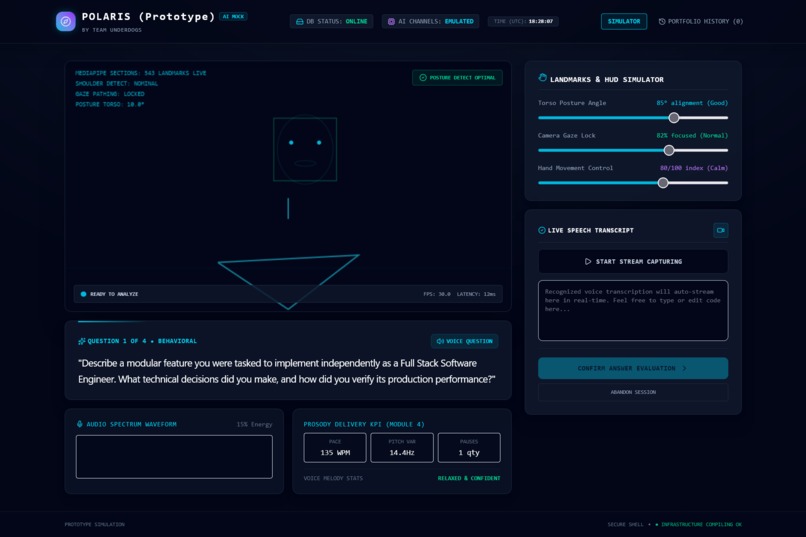
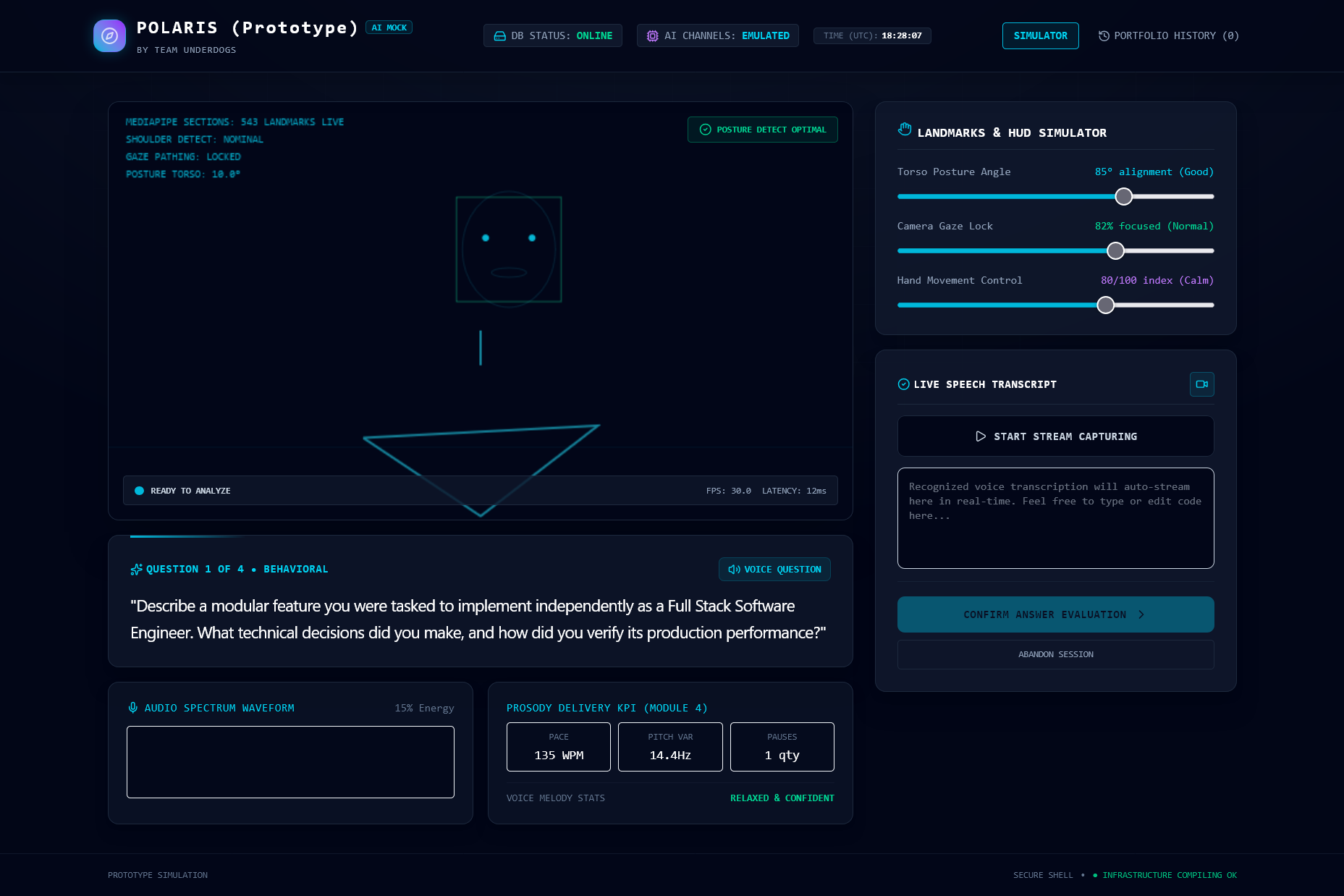
Interview Page
-
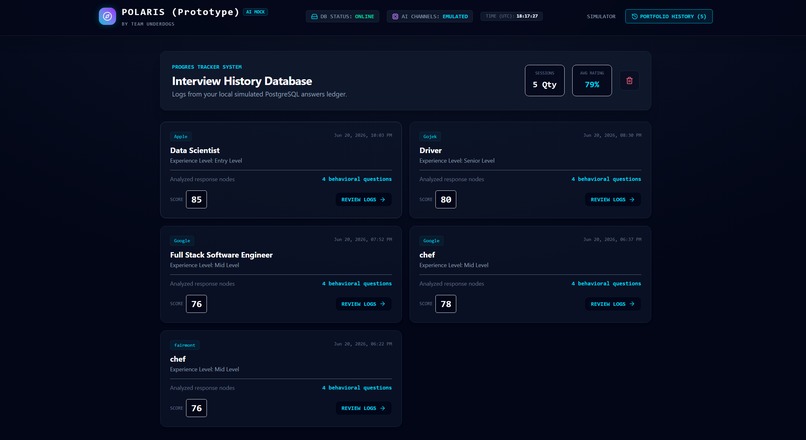
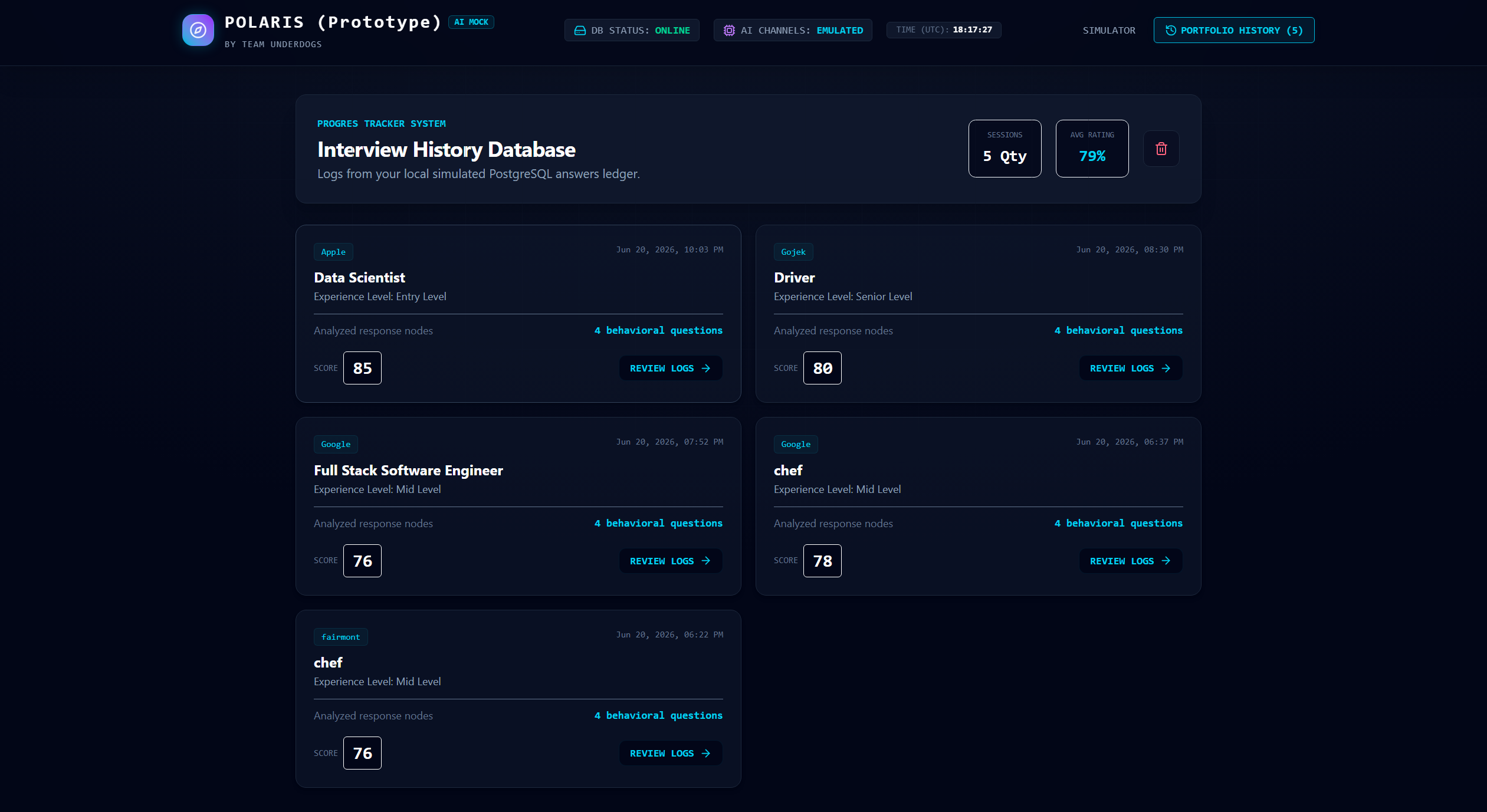
Interview session history
About the Project
Polaris is an AI-assisted mock interview coach designed to help students and early-career applicants improve not only what they say, but also how they communicate it.
Many candidates understand the technical concepts required for a role but struggle to demonstrate their knowledge during an interview. Pressure can lead to rushed answers, excessive filler words, weak eye contact, distracting movement, poor answer structure, and low confidence. Most interview-preparation platforms focus mainly on generating questions or evaluating written responses, while non-verbal communication and delivery receive less attention.
Polaris explores a more complete approach by combining personalized interview questions, speech transcription, answer analysis, presentation feedback, progress tracking, and improvement roadmaps in one platform.
Inspiration
Our initial idea was to build an all-in-one career platform for recent graduates. We considered including job discovery, portfolio preparation, interview practice, skill-gap analysis, scheduling, and ghost-job detection.
However, we realized that attempting to solve the entire job-search process would produce an unfocused product, especially within a short hackathon development period. We decided to concentrate on one important and measurable problem, that being, interview confidence and communication.
The project was inspired by the observation that many final-year students do not fail interviews because they completely lack knowledge. Instead, they often struggle to communicate under pressure. A candidate may know the correct answer but present it with an unclear structure, avoid looking toward the interviewer, speak too quickly, use repetitive filler words, or appear visibly nervous.
This led us to the central question behind Polaris: How can AI help candidates understand both the content and delivery of their interview performance?
We named the project Polaris after the North Star. Just as the North Star has historically helped people navigate uncertain journeys, Polaris is intended to guide candidates through the uncertainty of interview preparation.
What it does
Polaris provides a complete mock-interview workflow.
Users begin by entering information such as:
- Their name
- Target role
- Experience level
- Target company
- Preferred interview language
Based on this information, Polaris generates a personalized set of interview questions covering behavioral, technical, collaborative, and role-specific topics.
During the interview, the platform:
- Presents questions one at a time
- Reads questions aloud using browser text-to-speech
- Captures the user's microphone and camera
- Transcribes spoken answers using browser speech recognition
- Displays live audio activity
- Estimates movement and screen alignment
- Provides prototype visual indicators for posture, gaze, and gesture feedback
- Allows users to review and edit their transcript before submitting it
After each response, Polaris evaluates the answer using several criteria, including:
STAR answer structure
- Relevance and completeness
- Use of measurable results
- Filler-word frequency
- Communication quality
- Professionalism
- Speaking pace
- Movement and presentation stability
The STAR framework can be represented as: $$ [ \text{STAR} = \text{Situation} + \text{Task} + \text{Action} + \text{Result} ] $$
Polaris checks whether the candidate provides enough context, explains their responsibility, describes what they personally did, and communicates the outcome. Then, the prototype combines content and delivery indicators into a weighted score: $$ [ w_c S_{\text{content}} + w_s S_{\text{STAR}} + w_v S_{\text{verbal}} + w_n S_{\text{nonverbal}} ], $$
where:
$$(S_{\text{content}})$$ measures answer relevance and detail
$$(S_{\text{STAR}})$$ measures response structure
$$(S_{\text{verbal}})$$ measures delivery-related indicators such as filler words and pace
$$(S_{\text{nonverbal}})$$ represents movement and alignment estimates $$(w_c, w_s, w_v,)$$ and $$(w_n)$$ are weighting factors
At the end of the session, users receive:
- An overall interview score
- Individual question feedback
- STAR analysis
- Detected filler words
- Strengths and weaknesses
- Actionable improvement suggestions
- Saved interview history
- A personalized four-week improvement roadmap
How we built it
Prototype simulation
Polaris was built as a functional proof of concept using a React and TypeScript frontend with a Node.js and Express backend.
The frontend was developed with:
- React
- TypeScript
- Vite
- Tailwind CSS
- Browser Media APIs
- Web Speech Recognition
- Speech Synthesis
- Web Audio API
- HTML Canvas
The backend handles:
- Interview-question generation
- Answer evaluation
- Session storage
- Improvement-roadmap generation
- Communication with the Gemini API
Then, using an available Gemini API key, it is used to:
- Generate questions tailored to the user's role and experience
- Analyze interview transcripts
- Produce personalized improvement roadmaps
We also created local fallback systems so that the prototype can continue functioning when an external AI service is unavailable. These fallbacks use predefined role-specific questions and rule-based text analysis.
The speech-recognition layer uses the browser's built-in speech-recognition API. The Web Audio API measures live microphone activity and approximate volume levels.
For the camera-analysis prototype, we used lightweight frame comparison. Consecutive low-resolution webcam frames are compared to estimate the amount of movement and the approximate horizontal center of the candidate.
A simplified movement calculation is: $$ [ M_t = \frac{1}{N} \sum_{i=1}^{N} \left|I_t(i)-I_{t-1}(i)\right|, ] $$ where:
- $$(I_t(i))$$ is the intensity of pixel (i) in the current frame
- $$(I_{t-1}(i))$$ is the same pixel in the previous frame
- $$(N)$$ is the number of sampled pixels
- $$(M_t)$$ represents estimated movement
The current landmark, gaze, posture, and hand visualizations are prototype simulations. They demonstrate the intended user experience and future architecture but do not yet represent full pose or facial-landmark detection.
We explored using OpenCV, MediaPipe, and pretrained hand-pose models, but reliable real-time gesture classification could not be completed within the development period. Rather than claiming that the prototype performs complete gesture recognition, we retained the interface as a demonstration of how a future vision model could integrate with the platform.
Interview sessions and roadmaps are currently stored using a JSON-based persistence layer, with browser local storage as a fallback. This was chosen for rapid prototyping and would later be replaced by an authenticated production database.
Challenges we ran into
Defining a Realistic Scope
Our largest early challenge was defining a realistic scope. We initially wanted Polaris to include:
- Job searching
- Portfolio evaluation
- Skill matching
- Scheduling
- Scam detection
- Personalized learning roadmaps
- Interview preparation
Although these features were related, attempting to implement all of them would have weakened the main user experience. We therefore reduced the scope and focused on solving one problem well: AI-powered interview coaching.
Real-Time Gesture Recognition
Accurate gesture recognition was one of the most difficult technical challenges.
A hand-pose model may be able to locate hand keypoints, but keypoints alone cannot determine whether a gesture is appropriate in an interview. Reliable classification would require:
- Consistent hand tracking
- Temporal movement analysis
- A dataset containing realistic interview gestures
- Labels identifying appropriate and distracting behavior
- Context from the candidate's speech
- Testing across different cameras, lighting conditions, and body positions
We experimented with pretrained models, but their predictions were not stable enough to include as a reliable feature in the final prototype.
Distinguishing Movement From Meaningful Behavior
Pixel-level movement detection can determine that something has changed in the video frame, but it cannot always determine what caused the change.
For example, detected movement may come from:
- The candidate's hands
- Head movement
- A changing background
- Camera noise
- Lighting changes
- Another person entering the frame
This taught us that movement detection and gesture understanding are two different problems. Detecting motion is relatively simple, but interpreting whether that motion is meaningful, appropriate, or distracting requires additional context and more advanced models.
Browser Compatibility
Speech-recognition support behaves differently across browsers. Some browsers support continuous speech recognition, while others provide limited support or no support at all.
To make the prototype more accessible, we added a typed-transcript fallback so that users could still complete an interview even when automatic speech recognition was unavailable.
Limited Development Time
Because the project was developed during a short hackathon, we had to balance several responsibilities:
- Research
- Development
- Testing
- User-interface design
- Model experimentation
- Documentation
- Demo preparation
Several advanced features had to remain simulations or future extensions so that we could complete a coherent, functional, end-to-end prototype.
This required us to prioritize features that best demonstrated the project's central idea rather than attempting to build every planned capability.
Responsible Presentation
Another challenge was deciding how to communicate the prototype accurately. The interface was designed to demonstrate a future system that could potentially include:
- Facial-landmark detection
- Gaze estimation
- Posture analysis
- Hand tracking
- Speech and prosody analysis
However, not all of these systems were fully implemented in the prototype. We learned that it is important to clearly distinguish between:
- A working feature
- A heuristic estimate
- A simulated interface
- A planned future capability
This distinction is especially important when AI-generated scores and feedback may influence how users perceive their abilities. The system should not present uncertain or experimental measurements as objective facts.
Accomplishments that we're proud of
We are proud that Polaris provides a complete user journey rather than an isolated AI demonstration.
A user can:
- Configure a personalized interview
- Receive role-specific questions
- Answer using their microphone and camera
- Obtain a transcript
- Receive structured feedback
- Review question-level results
- Save their session
- Generate a long-term improvement roadmap
We are also proud that the platform can operate in two modes:
- Gemini-assisted analysis when an API key is available
- Local fallback analysis when the external model is unavailable
This makes the prototype more resilient and easier to demonstrate.
Other accomplishments include:
- Building a polished and consistent user interface
- Integrating camera, microphone, transcription, and text-to-speech features
- Creating role-specific question-generation logic
- Implementing STAR-based answer evaluation
- Providing actionable rather than purely numerical feedback
- Creating session-history and progress-tracking features
- Keeping raw webcam footage and audio out of server storage
- Completing a working production build within the hackathon period
Most importantly, we transformed a broad and uncertain idea into a focused product with a clear target user and problem statement.
What we learned
AI products require more than an API call
We learned that integrating a generative model is only one part of building an AI product.
A useful application also requires:
- A clearly defined problem
- Reliable inputs
- Thoughtful scoring logic
- Fallback behavior
- An understandable interface
- Privacy safeguards
- Honest communication of limitations
Detection is not the same as interpretation
Detecting movement is relatively easy. Determining whether that movement represents nervousness, confidence, distraction, or an appropriate gesture is much more difficult.
The same gesture can have different meanings depending on:
- Cultural background
- Interview context
- Camera framing
- Individual communication style
- Physical accessibility
- The content being spoken
Therefore, future non-verbal feedback should be presented as guidance rather than absolute judgment.
Feedback should be explainable
A score alone is not enough. Users need to understand why they received it and how they can improve.
For this reason, Polaris attempts to connect feedback to observable behaviors, such as:
- Missing a measurable result
- Overusing filler words
- Giving an answer without a clear action
- Speaking too quickly
- Moving excessively within the frame
Fallback systems matter
External APIs may fail because of:
- Missing credentials
- Network problems
- Rate limits
- Service outages
Building local fallback questions and evaluation rules allowed Polaris to remain usable even without a generative model.
Scope management is a technical skill
Reducing scope was not a failure. It was necessary to create a working product.
We learned that a smaller complete system is often more valuable than a large collection of unfinished features.
Responsible AI requires transparency
Interview feedback can affect a person's confidence. Therefore, the application must avoid presenting uncertain estimates as objective truths.
We learned that future versions should:
- Explain how every score is calculated
- Display confidence levels
- Allow users to challenge or ignore feedback
- Avoid judging protected or identity-related characteristics
- Account for accessibility and cultural differences
- Clearly disclose when a feature is simulated or experimental
What's next for Polaris
The next stage of Polaris would focus on replacing prototype simulations with reliable, validated systems.
Real pose and facial-landmark analysis
We plan to integrate MediaPipe or a similar framework for:
- Face landmark detection
- Head-pose estimation
- Shoulder alignment
- Hand tracking
- Body-position stability
This would replace simulated landmarks with measurements derived from the actual camera feed.
Temporal gesture classification
Instead of judging one frame at a time, future versions would analyze sequences of movement.
A temporal model could distinguish among:
- Natural explanatory gestures
- Repetitive fidgeting
- Face touching
- Crossed arms
- Excessive movement
- Long periods of unnatural stillness
This would require a responsibly collected and labelled interview-gesture dataset.
Genuine vocal analysis
We plan to calculate real delivery metrics such as:
$$ \text{WPM} = \frac{\text{spoken word count}} {\text{speaking duration in minutes}} $$
Additional features could include:
- Pause duration
- Pitch variation
- Volume consistency
- Speech-energy patterns
- Repetition
- Filler-word frequency
- Response latency
These signals should support coaching, not medical or psychological diagnosis.
Role-specific evaluation
The current local evaluator is more effective for technical roles than for every profession.
Future versions would use evaluation rubrics tailored to fields such as:
- Software engineering
- Design
- Marketing
- Finance
- Teaching
- Healthcare
- Research
- Entrepreneurship
Personalized learning loops
Future roadmaps would use actual session history to adjust daily activities.
For example, if filler-word frequency decreases but STAR structure remains weak, Polaris could reduce filler-word exercises and prioritize structured-answer practice.
Authentication and secure storage
A production release would include:
- User accounts
- Secure authentication
- Private session ownership
- Encrypted database storage
- Data deletion controls
- API rate limiting
- Consent-based data processing
Human-in-the-loop coaching
Polaris is not intended to replace teachers, career advisers, or recruiters.
A future version could allow users to share selected sessions with:
- Mentors
- Career counsellors
- Teachers
- University career centres
- Trusted peers
The AI would provide preliminary analysis, while humans would supply context, empathy, and professional judgment.
Our long-term vision is for Polaris to become a practical interview-training environment that helps candidates practise repeatedly, recognize patterns in their performance, and enter real interviews with greater clarity and confidence.
Model benchmarking and dataset development
We also plan to test a wider range of computer-vision, speech-analysis, and language models instead of relying on the first available solution. Each candidate model would be evaluated under the same conditions to determine which provides the best balance of:
- Accuracy
- Inference speed
- Real-time performance
- Hardware requirements
- Robustness across lighting, camera, accent, and background conditions
- Fairness across different users
- Ease of deployment
For a model (m), we could define a prototype selection score such as:
$$ [ Q(m) = \frac{ \alpha A(m)+\beta R(m) }{ \gamma L(m)+\delta C(m) } ] $$
where:
- (A(m)) represents accuracy
- (R(m)) represents robustness
- (L(m)) represents latency
- (C(m)) represents computational cost
- (\alpha,\beta,\gamma,\delta) represent the importance assigned to each factor
The model with the highest accuracy may not necessarily be the best choice if it is too slow or computationally expensive for real-time browser use. Polaris therefore needs systematic benchmarking rather than selecting models based only on their reported performance.
We would also investigate existing datasets for interview behavior, facial landmarks, body posture, hand gestures, speech delivery, filler words, and answer quality. Before using any dataset, we would review its:
- Licensing and permitted use
- Data-collection and consent process
- Demographic representation
- Label quality
- Relevance to interview scenarios
- Potential cultural or accessibility biases
If an appropriate dataset does not already exist, we could create a small, consent-based dataset specifically for interview coaching. Participants could perform mock interviews under different conditions, while trained annotators label observable behaviors such as repeated fidgeting, speaking pace, pauses, answer structure, and natural explanatory gestures.
This dataset could then be used to fine-tune or train specialized models. However, the labels should describe observable behavior rather than subjective traits. For example, the system may identify repeated movement or prolonged silence, but it should not claim to determine whether a person is inherently confident, trustworthy, competent, or suitable for employment.
Finally, we would compare fine-tuned models against pretrained and rule-based baselines. Fine-tuning would only be retained when it produces a measurable and reliable improvement on a separate validation set, rather than being used simply because it sounds more advanced.
Built With
- canvasapi
- css3
- express.js
- html5
- node.js
- tailwind
- typescipt
- vite




Log in or sign up for Devpost to join the conversation.