-

Poker
-
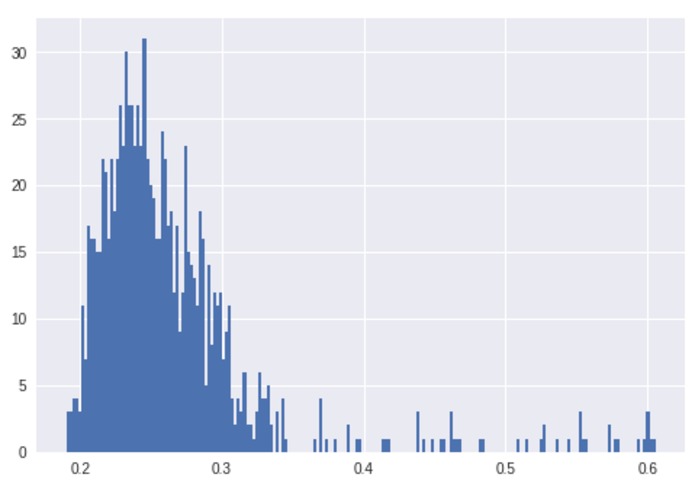
1st round histogram
-

Other round histograms



Inspiration
We have created a bot that can play well a modification of Texas Holdem Poker game. The modification consists in introducing superpowers to the game, which makes it more challenging and interesting. Our strategy is based on calculating a score for our hand and then selecting a suitable action. The score can be loosely interpreted as the probability of winning. We use different thresholds for the score to select our next action.
What it does
It is a bot that uses simulations and probabilistic methods to play Poker well.
How we built it
Details on the strategy as well as some additional details follow.
Calculating the score of hand in combination with the board:
We used Treys library to calculate the rank of our hand. The best rank 1 is obtained by a Royal Flush, while the worst rank is 7642. We used this to calculate a score which could be loosely interpreted as the probability of winning given our hand and the board. The formula is: p(win|hand, board)=1.0 - rank(hand, board)/7642.0
Strategy of selecting action:
1st round:
- Only two cards (pocket cards) are available and the board is empty. This presents a problem for Treys library as it can only evaluate combinations with five cards (which can be chosen out of 5, 6 or 7 cards). To solve this, and to get a score for our two cards, we decided to perform Monte Carlo simulations. We keep the first two cards fixed and then we generate 3 other cards, repeatedly 1000 times. We then calculate the rank of each such combination and take the average of all ranks. This allows us to find a score even in the initial round, which we can use for decision making based on the probability.
- We take into account the currently available actions (depending on the current state and previous actions), with preference first for raise, call, check and fold in this order. The minimum required score for raising is 0.33, 0.27 for calling and 0 for checking or folding. We always prefer to check over fold if we can check. If an action is not available in a current state (even if we have good cards), we select the next preferred action.
- We obtained the thresholds by running 1000 rounds of simulations of games to find the frequency of the different ranks/hands. A histogram plot is below (x-axis is the score, y-axis is the count/frequency).

Other rounds:
- In this case, we can directly use Treys library to find a score for our hand. Based on the score and the available actions, we select the action.
- We take into account the currently available actions, with preference first for raise, call, check and fold in this order. * The minimum required score for raising is 0.55, 0.2 for calling and 0 for checking or folding. We always prefer to check over fold if we can check. If an action is not available in a current state (even if we have good cards), we select the next preferred action.
- We obtained these thresholds by running 1000000 rounds of simulations of games to find the frequency of the different ranks/hands (we could run 1000 times more simulations than in the first round because we do not need to run 1000 simulations for the possible board cards). A plot follows (x-axis is the score, y-axis is the count/frequency).

- The lowest scores are the most common and they describe a high card (the least valuable category - no calling or raising). The next bucket is a pair of cards, for which we have decided to call or check. Next, we have cards with at least two pairs (and other more valuable combinations), for which we raise as these actions are relatively uncommon. We keep in mind that a relatively aggressive strategy in poker is more likely to win (because of that we use a relatively low threshold for raising).
Stake raising strategy:
- The maximum raise of stake that we consider is max_raise = our_chips - (table_stake - our_stake)
- The raise of stake that we do actually do is min(max_raise, 2*table_stake)
Superpowers:
As a modification to the standard Texas Holdem Poker, Square point introduced superpowers to make the game more interesting. Our bot has support for these superpowers. We use the superpowers (spy, seer, leech) when we have not used them yet, they are available and the pot has at least ten times more money than we have (it needs to be really valuable to use them).
Infrastructure and implementation aspects:
- Communication with the server: we used Python socket library for connecting to Square Point server via TCP.
- The server gives a different representation of cards than can be used in Treys library, hence we need to convert the format of the cards.
Challenges we ran into
Treys library does not support evaluating situations with only two cards (pre-flop situation). We had to come up with our own, innovative way of handling this situation - by doing Monte Carlo simulation. We also had to deal with quite many issues in communicating with the server.
Accomplishments that we're proud of
Our bot plays the game really well and it has won all tournaments so far. We are also proud of our decision making strategy based on simulations and modelling, and also the fact we found a good way to find thresholds. Another very important thing that we are very proud of is that we managed to connect and work with the server.
What we learned
How to create bots playing poker and how to work with the server giving responses.
What's next for PokerStarz poker bot
We could use advanced Reinforcement Learning strategies such as SARSA, Q-Learning or even Deep RL Q-Learning.

Log in or sign up for Devpost to join the conversation.