-
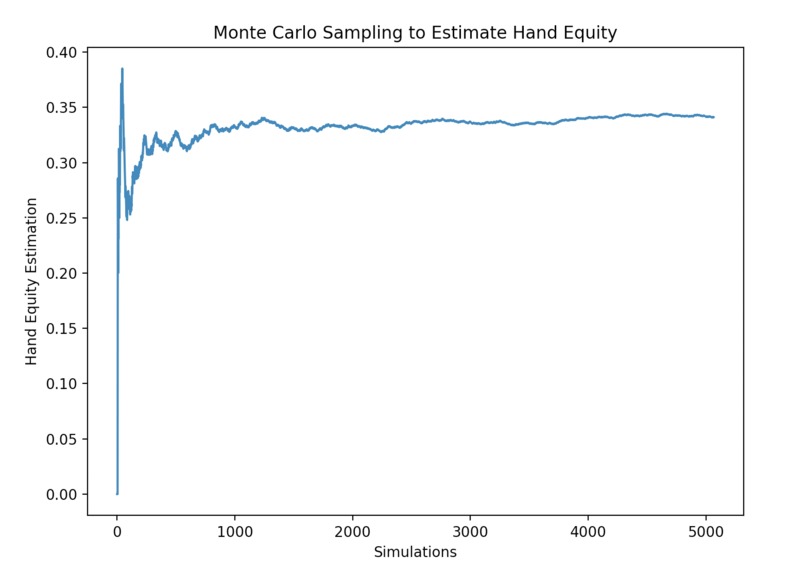
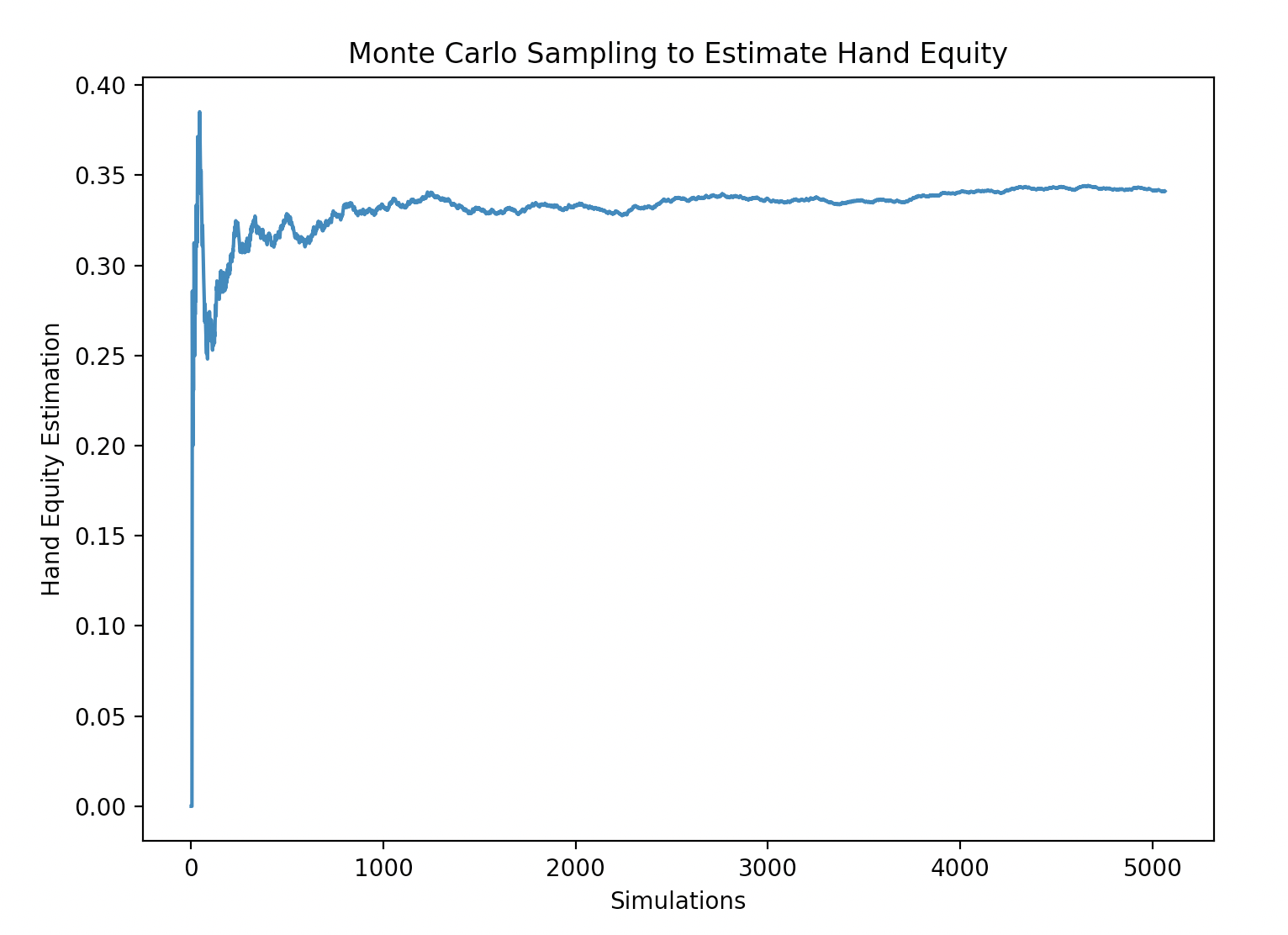
Figure 1. Monte Carlo Sampling converges on E[x] as the simulation count increases.
-

Photo 1. The Monte Carlo Sampling example is anecdotally validated here through an online hand equity calculator, pictured here.
-

Photo 2. A screenshot of two PokerBots playing each other on PokerNow. The two pair of p0 beat the top pair of p1.
-
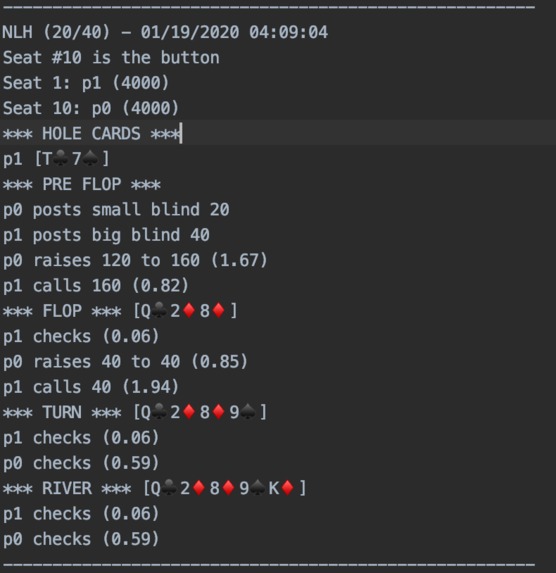
Photo 3. A screenshot of a hand history logged by a PokerBot
-
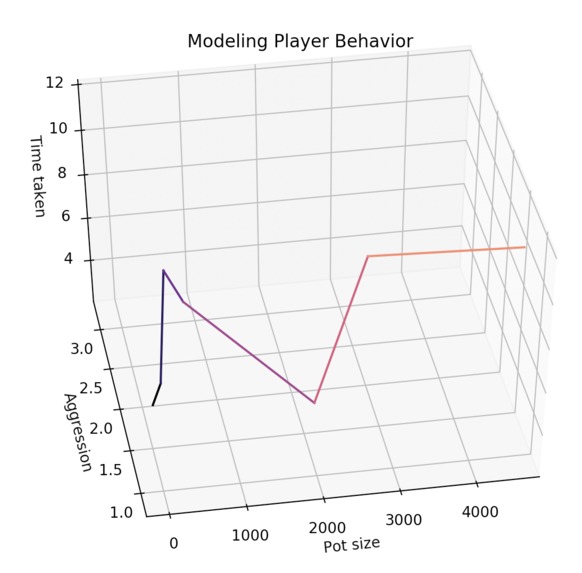
Figure 2. Each action that a PokerBot opponent takes is recorded and modeled. PokerBot can learn and exploit these tendencies.
-
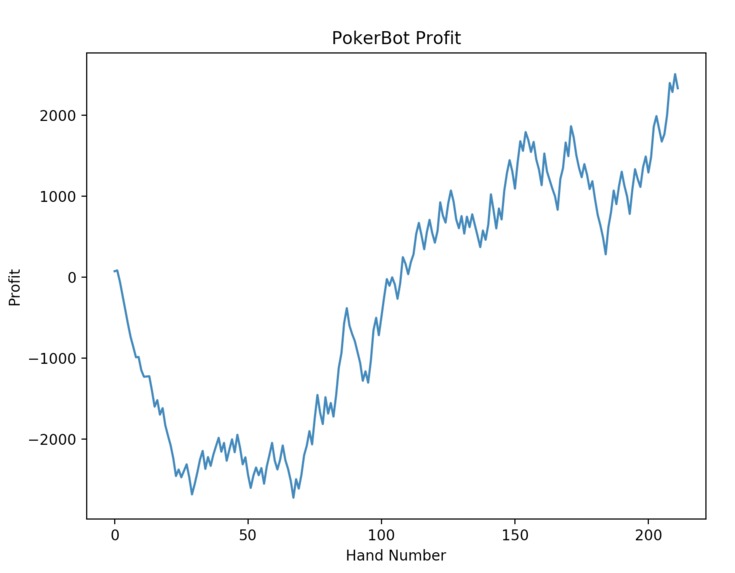
Figure 3. PokerBot profit when competing against a bot that behaves randomly.





Inspiration
I got hooked on Texas Hold'em poker at my internship this past summer. After my internship I joined the UNL Poker Club and began playing regularly during the fall semester. In November, our internship poker group started playing together online through a poker site called Poker Now (https://www.pokernow.club/). After some Venmo transaction analysis recently, I realized that I was slowly bleeding money playing poker on Poker Now. As a rational human, I wanted to learn where the weaknesses in my game were, as well as if I could use the skillset I have developed as a computer science student to create a bot that could beat my friends at poker.
Project Overview
Part 1: Interacting with Poker Now
PokerBot needs to connect to Poker Now, interpret opponent behavior and game state updates, and be able to behave following instructions from itself. This was nontrivial, and accomplished using Python and Selenium.
Part 2: PokerBot logic
PokerBot uses Monte Carlo Sampling to estimate hand equity, Bayesian inference and k-nearest neighbors to perform opponent modeling, and Q-learning for decision making and risk management.
Results
During this hackathon, PokerBot did not have enough time to face an unbiased human opponent. However PokerBot was run against a bot that behaved randomly and was able to generate considerable EV. As time steps progressed in this simulation, PokerBot was characterized by aggressive behavior when having high hand equity and and extremely passive behavior when hand equity was middling or low. Likewise, the profit graph of this simulation was characterized by large increases and small decreases. This likely is not the optimal learned behavior against a human opponent.
What I Learned
A key insight that made this problem tractable was to used Monte Carlo Sampling to approximate hand equity. To do an exhaustive search of the remaining possible board cards for each possible combination of opponent hole cards was computationally expensive and caused the algorithm to take minutes before acting.





Log in or sign up for Devpost to join the conversation.