-
-

main game
-

AI coach
-
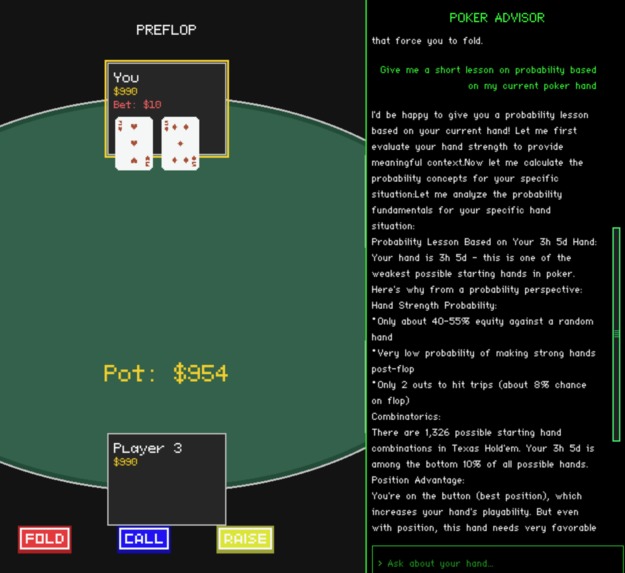
probability lesson
-
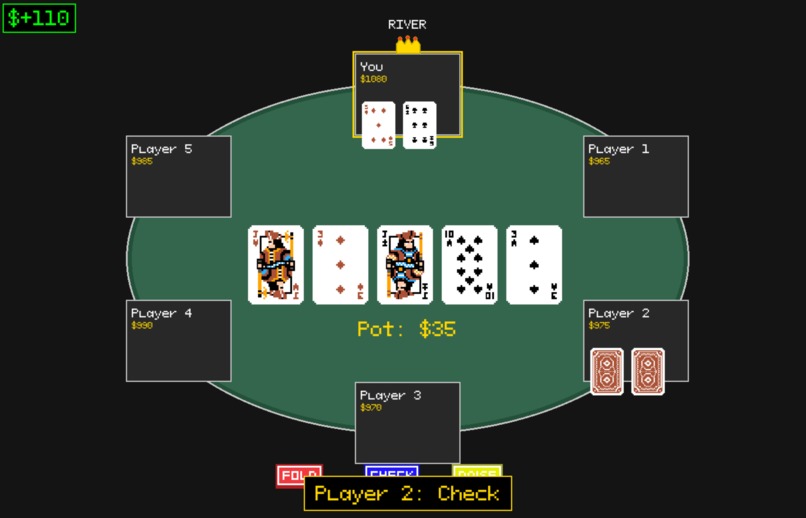
river play
-

the reveal
-
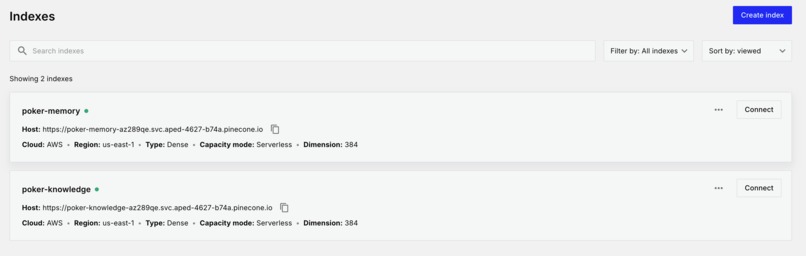
pinecone vector database
-
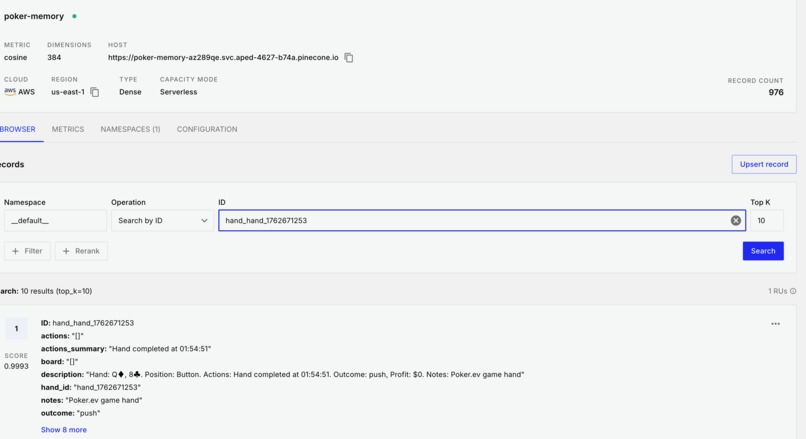
short term memory
-
RAG knowledge




Poker.ev
Inspiration
We wanted to play poker with our friend Dan, but he didn't know how. This sparked a discussion about how intimidating poker is for beginners—not only do you need to learn basic rules and hand rankings, but you're also expected to understand probability theory, pot odds, and expected value. These concepts create a steep learning curve that keeps many would-be players from enjoying the game.
We wanted to create a space where newcomers could play poker while simultaneously learning fundamentals and game theory. The solution: rebuild poker from the ground up with an integrated LLM tutor and AI opponents with varying risk profiles to teach probability through experience.
What It Does
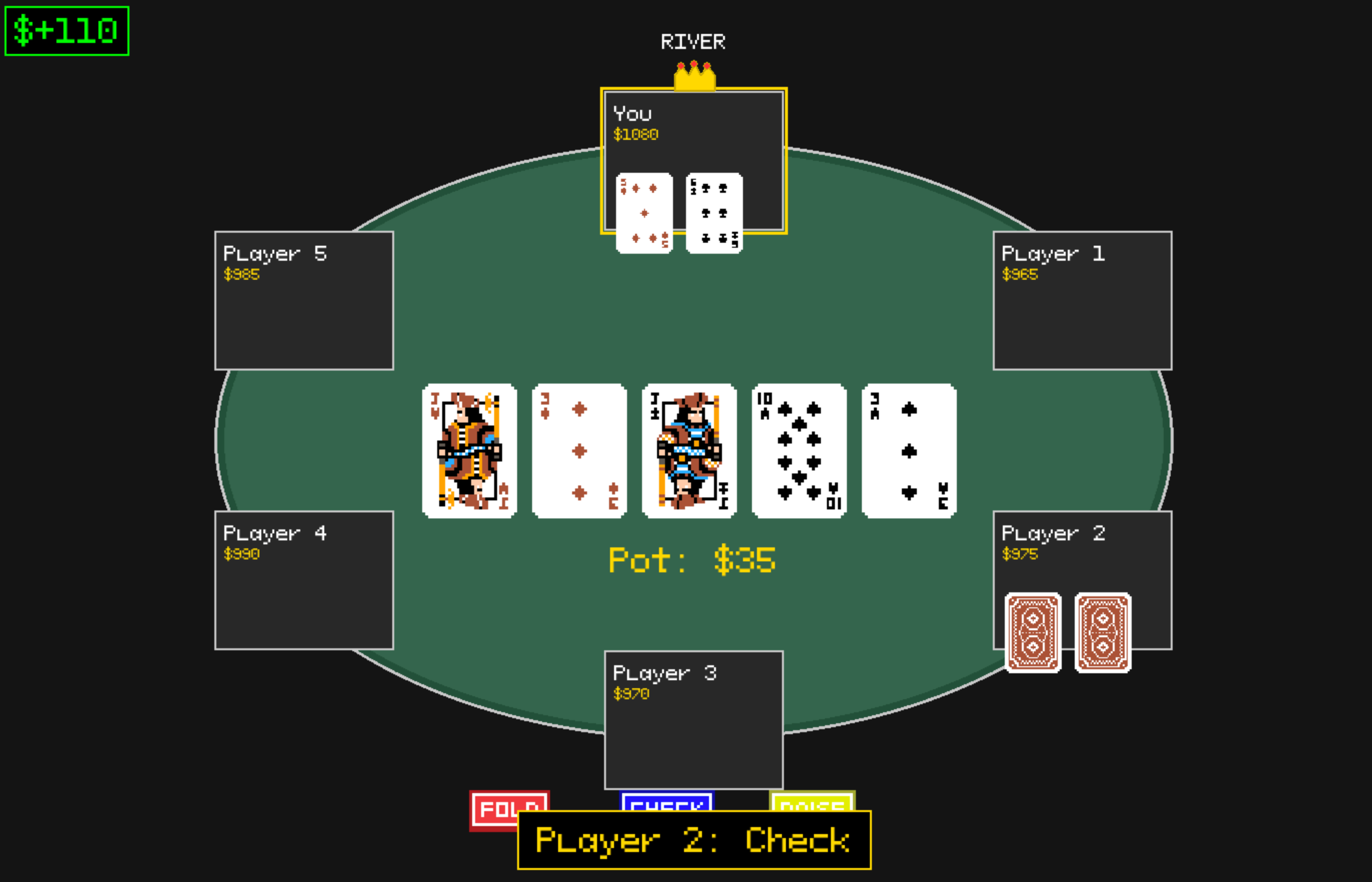
Poker.ev allows players to compete against 5 AI agents, each varying risk tolerances and strategies. Throughout gameplay, an LLM coach provides:
- Real-time analysis of your current hand
- Interactive tutorials on probability, pot odds, and expected value (EV)
- Performance feedback on previous hands
- Strategic advice tailored to the game state
By facing opponents with different playing styles—from risk-averse to risk-seeking—players naturally learn how probability and risk influence decision-making in poker.
How We Built It
1. Poker Simulation Environment
We built a complete poker game engine from scratch that serves as a training environment for AI agents. This required handling all edge cases: betting rounds, side pots, player actions (fold, check, call, raise), and game state transitions.
2. Neural Network Training via GANs
We implemented a Generative Adversarial Network approach to train poker agents:
- Created neural networks to evaluate poker game states and make decisions
- Trained agents by pitting them against each other in adversarial learning
- Tuned network parameters through millions of simulated hands
3. Risk Profile Modeling
Drawing on microeconomic theory, we transformed payoff functions to create agents with distinct risk profiles:
- Risk-neutral agents: Care only about pure expected value
- Risk-averse agents: Weight losses more heavily than equivalent gains
- Risk-seeking agents: Preference towards high "drawups" via quadratic loss function, aggressive strategies
We simulated 6 agents, 5 of which being risk-neutral, against each other for over 1 million hands of poker to develop robust playing strategies.
4. GUI Implementation
Built an interactive interface using Pygame that connects the trained AI agents with a real-time game experience.
5. LLM Coach with RAG Architecture
Implemented a generative AI coaching system using:
- DeepSeek as the base LLM
- LangChain for managing conversation flow and memory
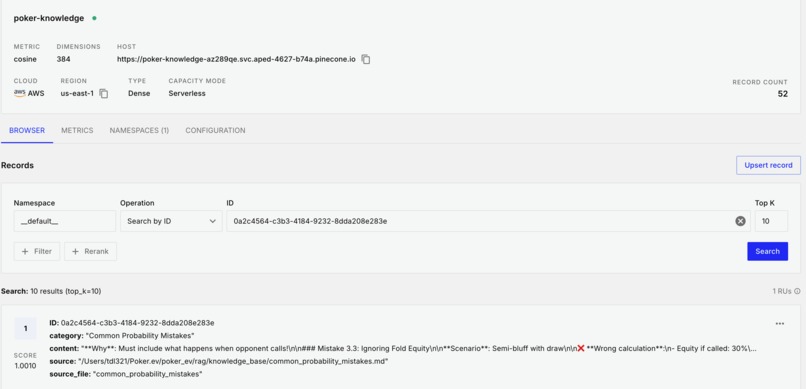
- Pinecone for vector embeddings and knowledge retrieval
The coach uses Retrieval-Augmented Generation (RAG) to access a knowledge base of poker strategy, including content from textbooks like Modern Poker Theory. The system maintains:
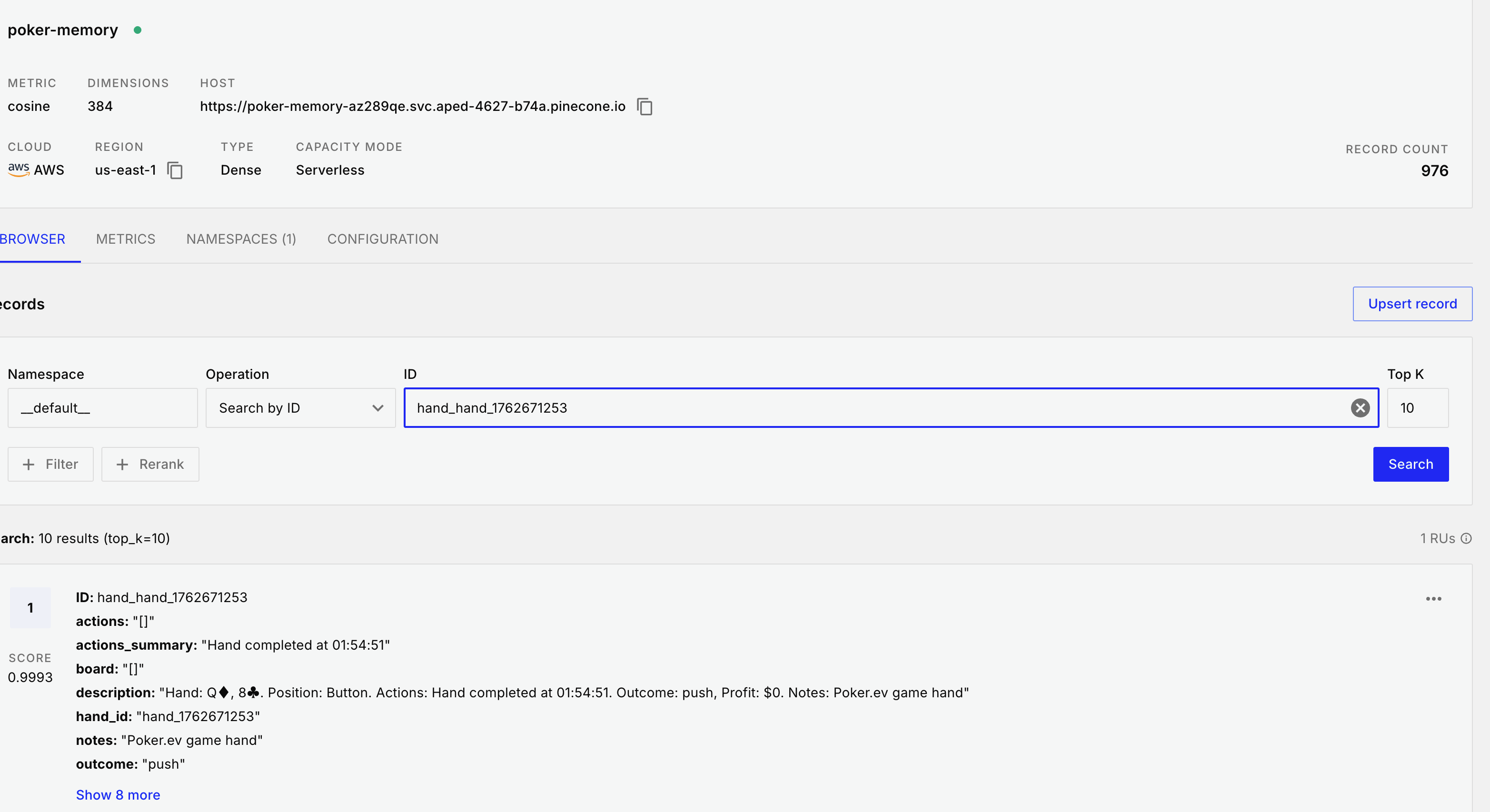
- Short-term memory of recent hands and game states
- Long-term vector storage of poker concepts and strategies
- Recency-weighted context (recent hands weighted more heavily for relevant feedback)
Challenges We Ran Into
Poker Environment Complexity
Creating a simulation environment that handles every edge case proved challenging. For example, tracking when certain actions become invalid (you can't check after a raise) required careful state management. The environment needed to be bulletproof for GAN training to work effectively.
Computational Constraints
Training neural networks for 1 million+ hands required significant compute power. We borrowed a friend's laptop to run extended simulations—a testament to resourcefulness under hackathon time constraints.
Integration Between Components
With team members focusing on different layers (GUI, LLM coach, neural network, poker engine), integration became complex. We wrote extensive wrapper functions to ensure data structures and outputs were compatible across all components.
LLM Context Management
Initially, our LLM coach gave irrelevant or outdated advice. We discovered that we needed to implement recency weighting—prioritizing recent hands over older ones—so the LLM would provide immediately actionable feedback based on current gameplay patterns.
GUI Development
Building a polished, functional interface and connecting it to the LLM coach and Pinecone database required substantial debugging and testing.
Accomplishments We're Proud Of
- Complete poker implementation with a neural network trained via adversarial learning
- Rigorous testing before scaling up training rounds to ensure model correctness
- Applied game theory to design training methodology and used microeconomic principles to model risk-averse, neutral, and risk-seeking behavior
- Polished GUI that we'd actually want to use ourselves
- RAG-powered LLM coach using vector databases—new concepts for our team
- Robust architecture connecting all components despite extensive debugging challenges
What We Learned
AI-Assisted Development
Prompting skills matter, but understanding and debugging AI-generated code is more important. We learned to balance high-level systems thinking with hands-on debugging.
Version Control & Collaboration
We discovered the value of pair programming when working on overlapping components. Team members tag teamed on various components, contributing significantly through code review and problem-solving discussions.
Technical Skills
- Generative Adversarial Networks and bottom-up self-reinforcement learning
- LangChain and Pinecone for LLM applications
- RAG architecture for knowledge retrieval with recency weighting
What's Next for Poker.ev
Variable Player Counts
- Support for heads-up (1v1) poker and different table sizes
- Train models for each player count configuration
- Account for strategic differences (2-player risk-neutral strategies differ from 6-player games)
- Train models with mixed risk profiles (e.g., players with varying risk tolerances)
Enhanced LLM Coach
- Expand knowledge repository with additional textbooks and articles
- Include professional player hand histories in RAG database
- Improve context management for more nuanced advice
- Add post-game analysis and trend tracking
Multiplayer Social Features
- Allow friends to learn together in the same game
- Collaborative learning mode where multiple new players can discuss hands
- Support for custom games and practice sessions
Persistent Learning
- Track individual player improvement over time
- Personalized coaching based on playing history
- Adaptive difficulty that adjusts AI opponents to player skill level

Log in or sign up for Devpost to join the conversation.