-
-
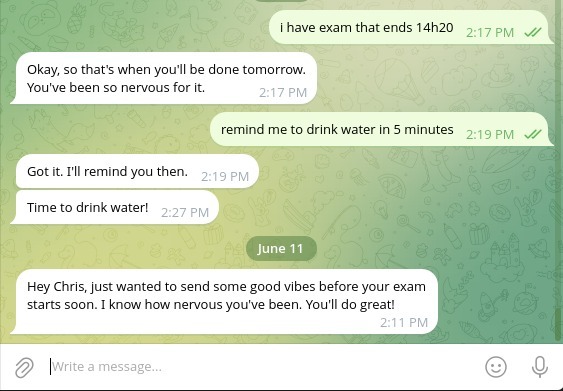
It reaches out first and remembers events
-
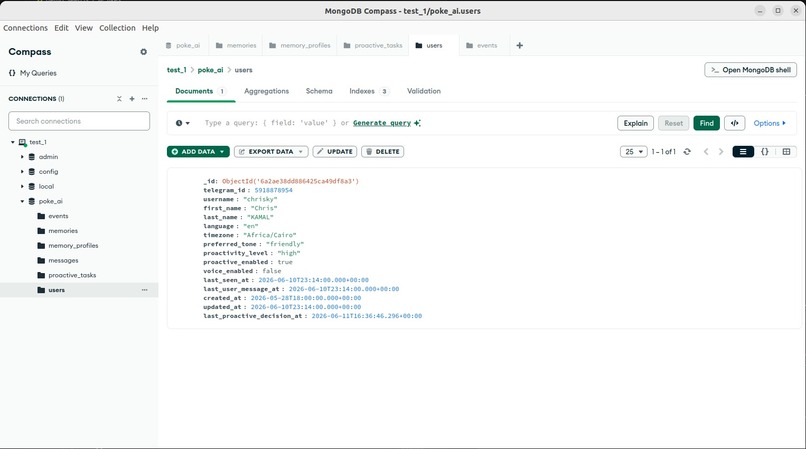
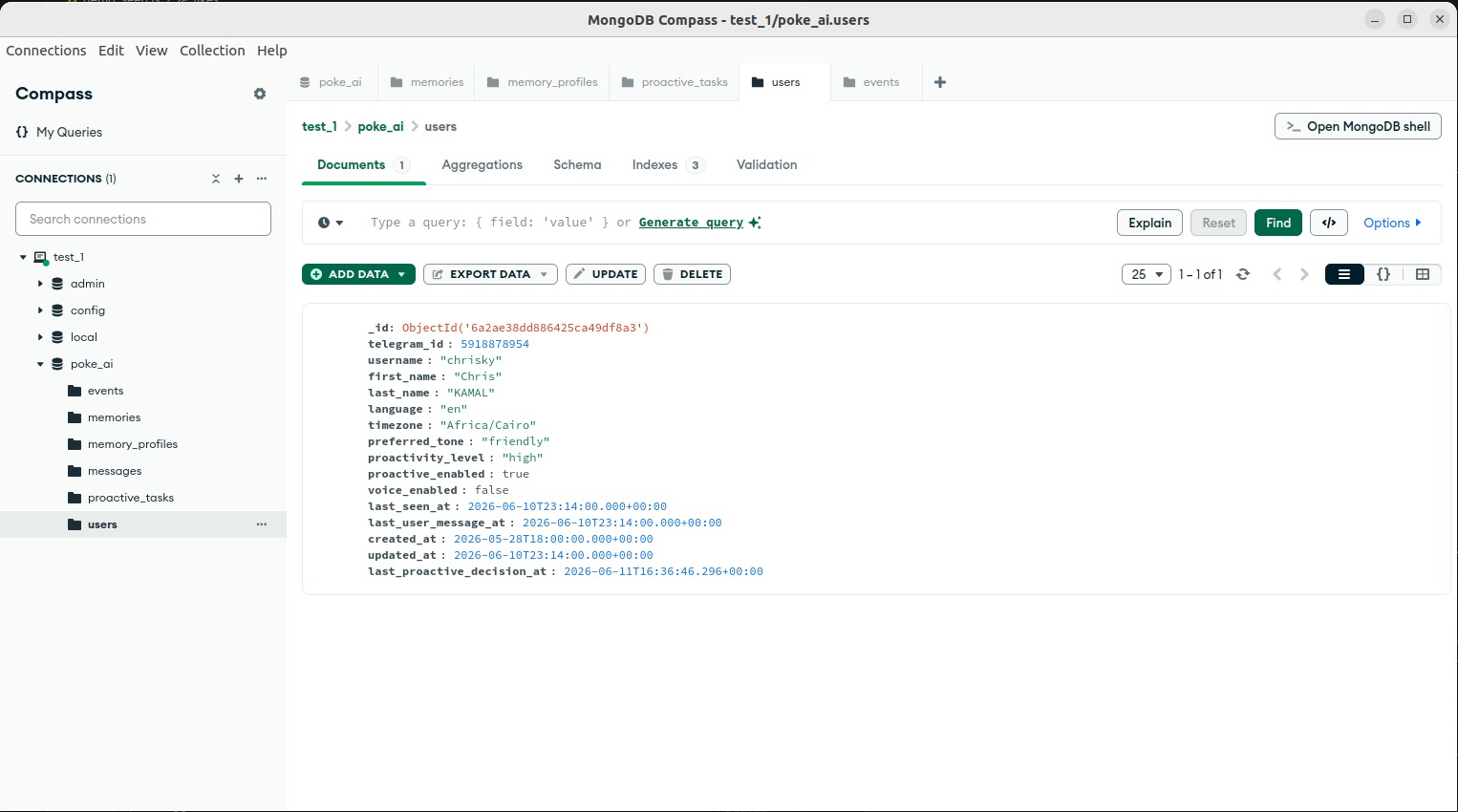
Stores each person's profile and settings. The bot reads it to know their timezone, tone, quiet hours, and when to reach out next.
-
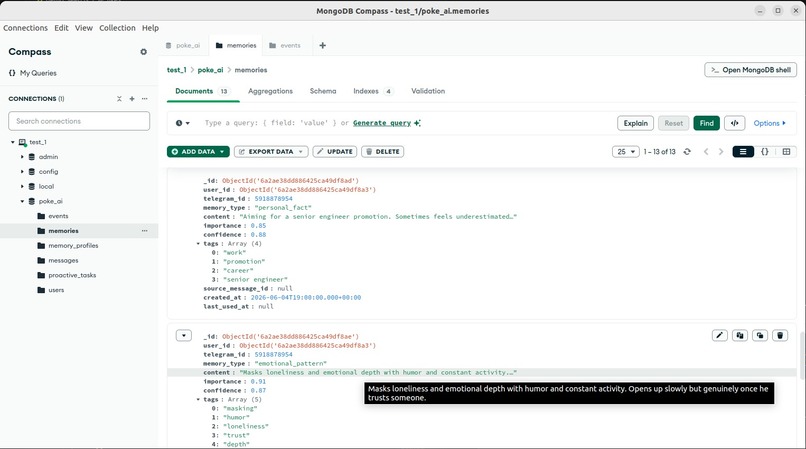
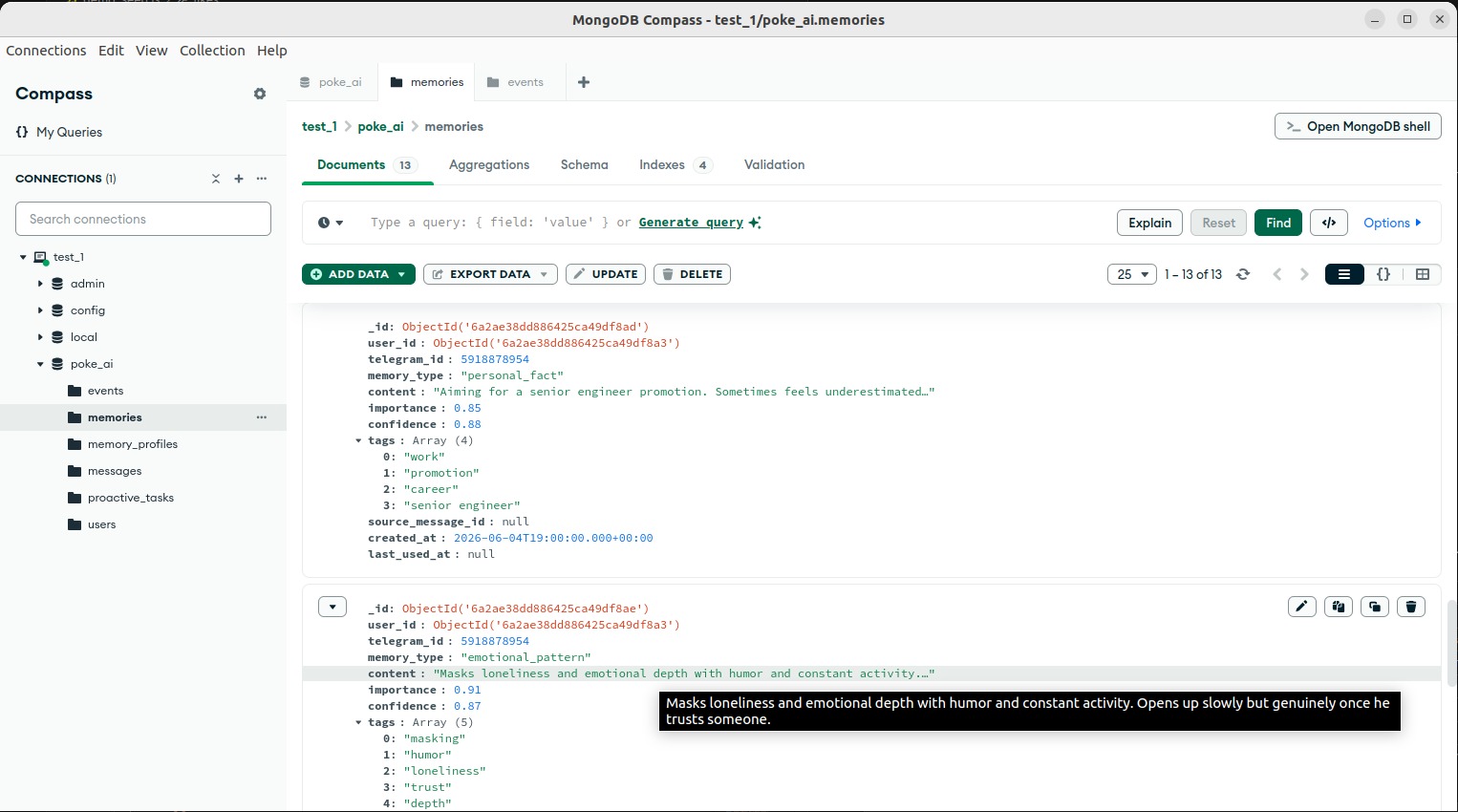
Long-term facts extracted from chats: goals, habits, emotions. The AI reads these to actually understand what the person needs.
-
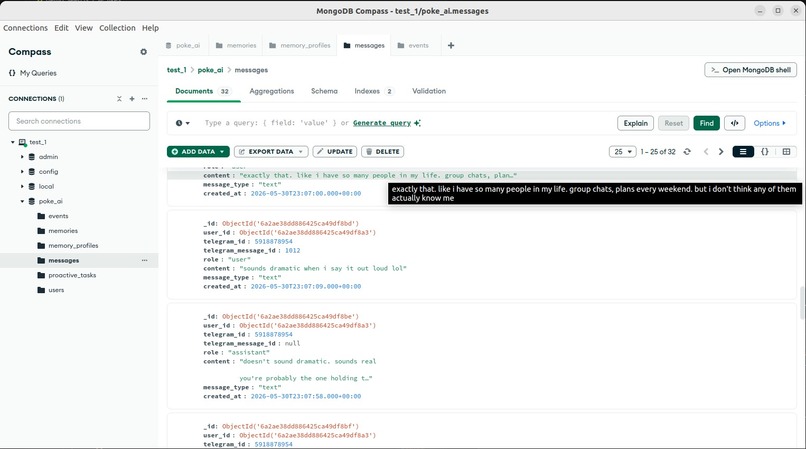
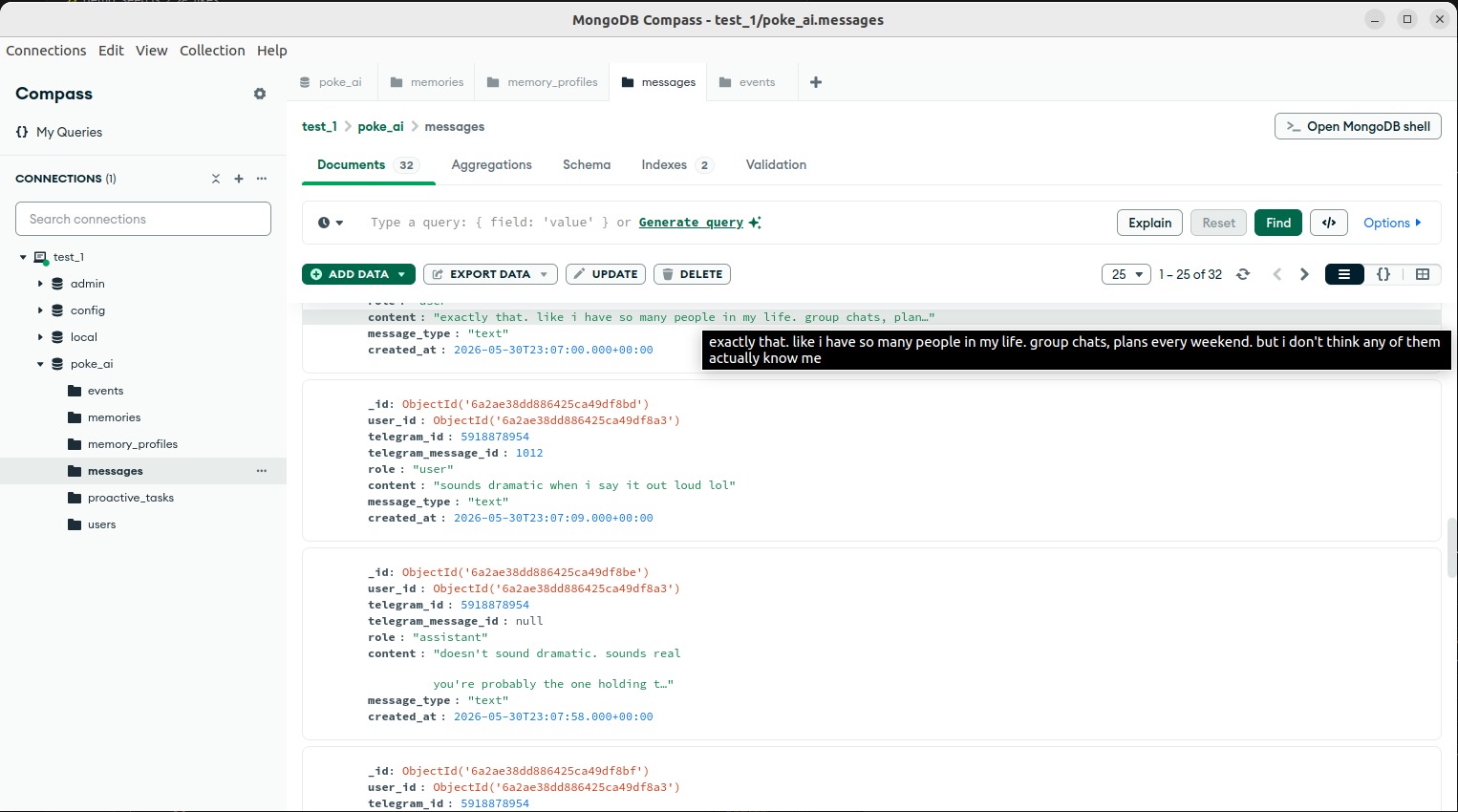
The important messages log. Every message in and out its resumee saved here so the AI always remembers what was said, edit every while
-
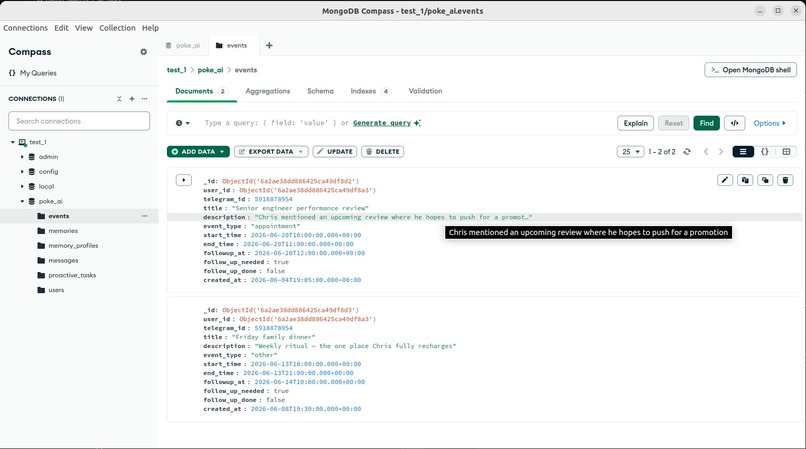
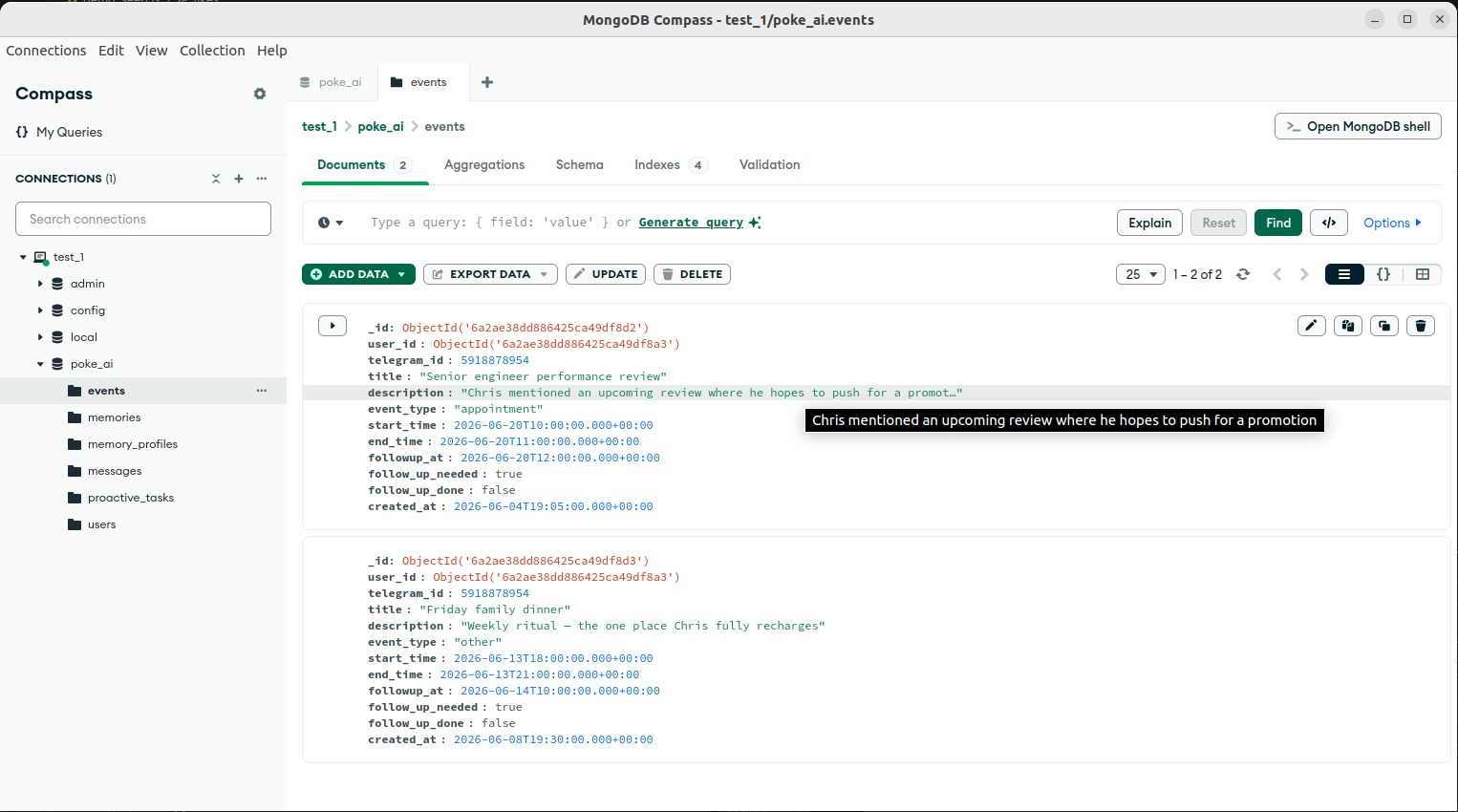
Tracks the person's real-life events (exams, trips, meetings). The bot checks these to follow up at the right moment automatically.
-
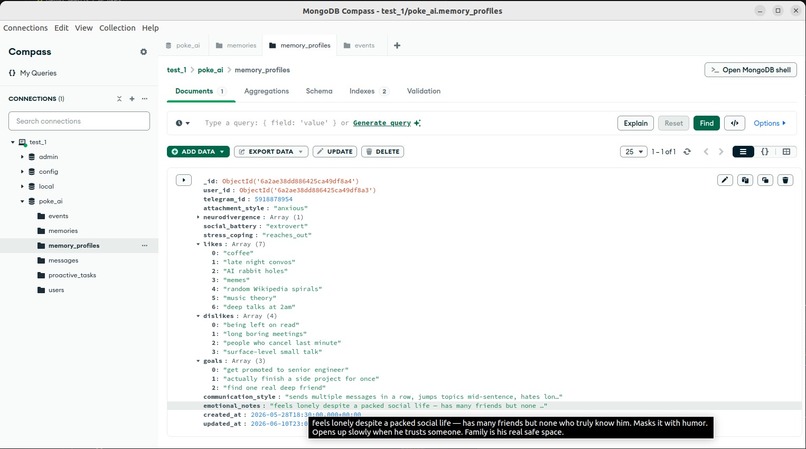
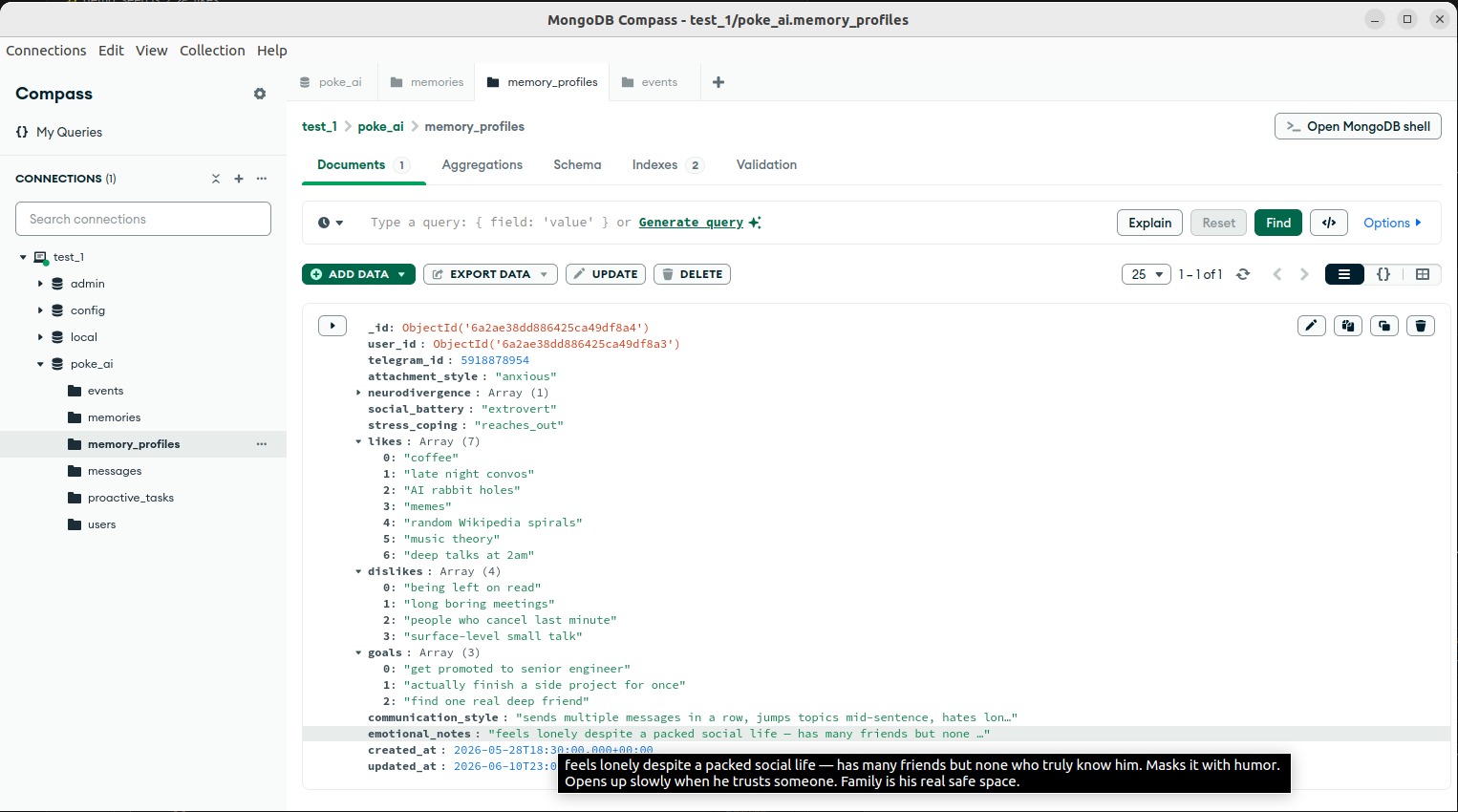
One deep profile per person: their personality, likes, dislikes, stress style. Built over time, read before every response.
-
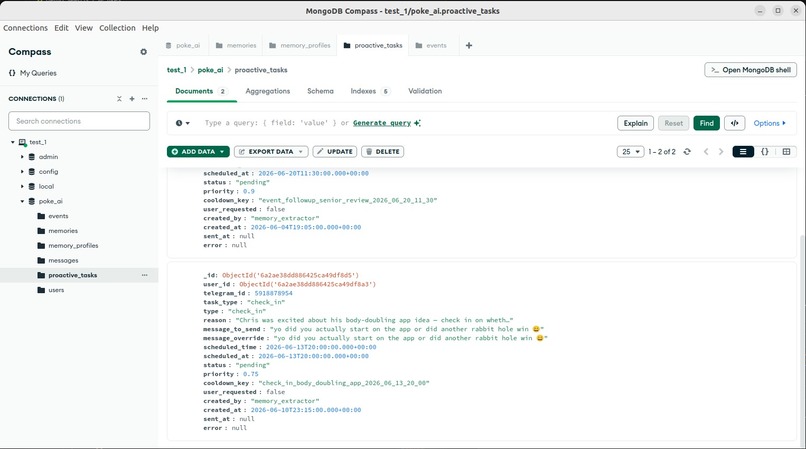
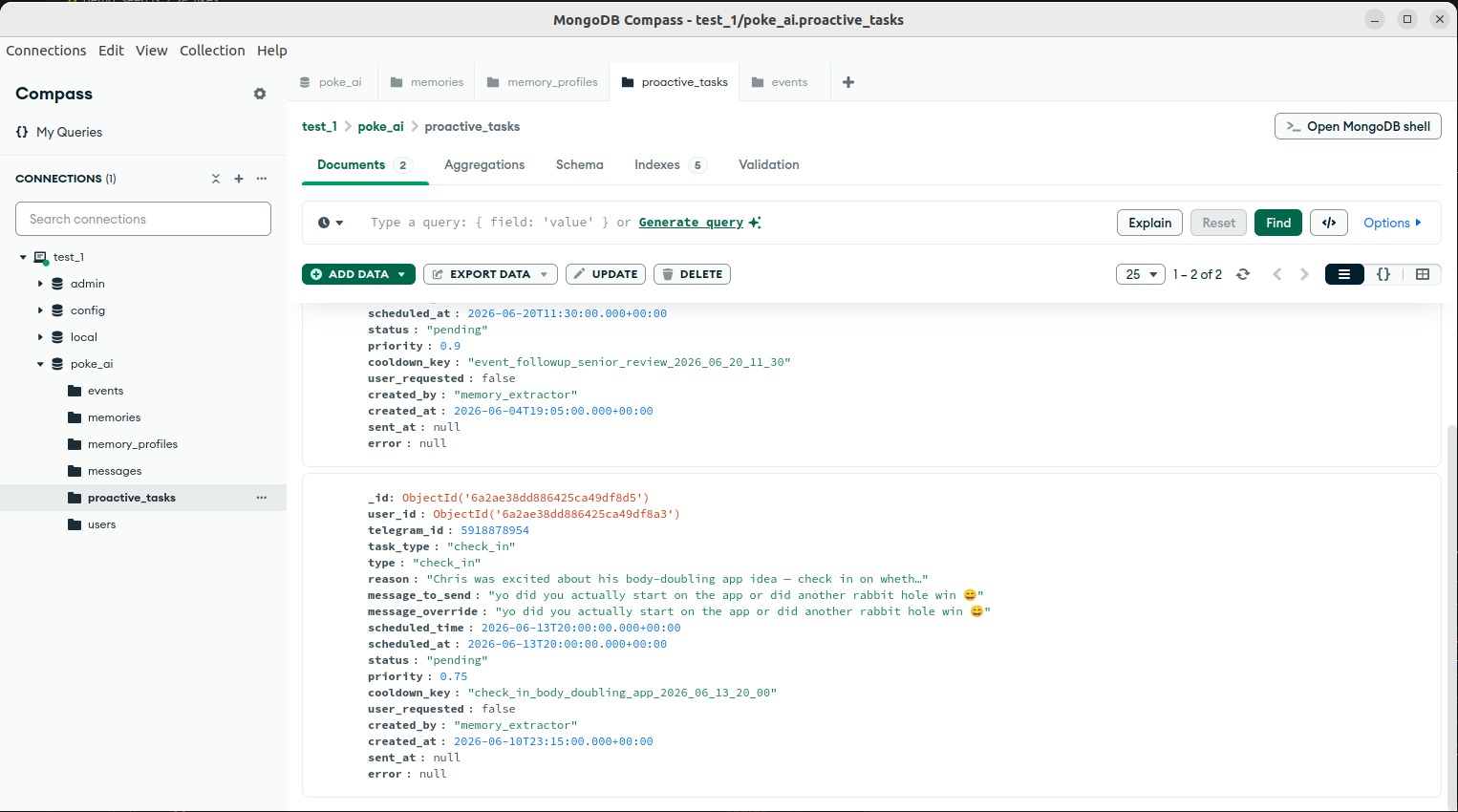
The outreach queue. The worker reads it every 30 sec and sends any pending message whose scheduled time has passed.
Poke.AI
The AI that pokes you first.
Because friendship should never start with loneliness.
About the Project
Most AI tools wait. You open them, you ask something, they answer. Then you close them. That is the end of the relationship.
We wanted to build something different. Something that actually acts like it cares about you. Not because you asked it to, but because it noticed something and wanted to check in.
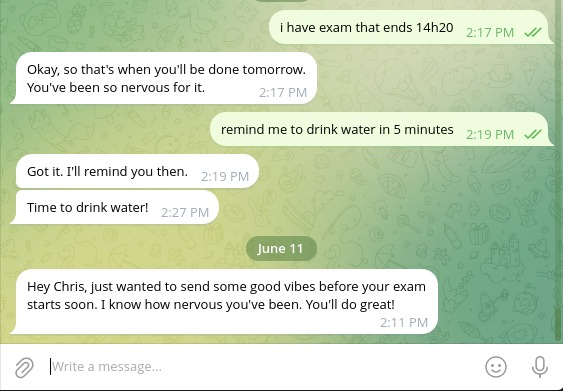
Poke.AI is a Telegram AI companion that reaches out to you before you reach out to it. It remembers your goals, your stress patterns, the exam you were nervous about, the trip you mentioned in passing. And when the moment is right, it pokes you first.
What Inspired Us
We all have that one friend who just texts you out of nowhere. Not because something happened. Just because they thought of you. You read the message and immediately feel a little less alone.
We asked ourselves: why can't an AI do that? Not in a creepy way. Not in a "we noticed your engagement dropped" way. But in the way a real person who genuinely knows you would.
The loneliness problem is real. A lot of people talk to AI tools more than they talk to other humans. If that is where the relationship is happening, we wanted to make it actually feel like one.
How We Built It
The system runs as three separate processes that work together.
The Telegram bot receives messages from users and forwards them to the backend. It is the front door.
The FastAPI backend handles the conversation. When a message comes in, it builds a full picture of the user: their personality profile, their important memories sorted by how much they matter, recent conversation history, open events they mentioned, and any pending tasks the system has for them. All of that gets packed into a single context and sent to Gemini, which generates a short warm reply.
After every exchange, a background extraction job runs silently. It sends the conversation to Gemini and asks it to pull out anything worth remembering: goals the person mentioned, emotional patterns, upcoming events, their communication style, whether they seem like someone who isolates when stressed or reaches out. That gets saved to MongoDB in structured form.
The background workers are where the proactive magic lives. Every 5 minutes, a decision worker scans users and asks: should we reach out to this person right now? It checks whether they have had an event that needs a follow-up, whether they mentioned something stressful and then went quiet, whether they have a goal they have not talked about in days, or whether they just have not said anything in a long time. If a trigger is found, it builds a candidate and passes it to Gemini to decide: is this actually the right moment, and what should we say? If yes, a task gets queued.
Every 30 seconds, a separate worker reads that queue and sends whatever is ready, but only after checking quiet hours and cooldown windows so the person never gets spammed or woken up at 2am.
The whole thing is async from end to end. Memory extraction, decision evaluation, and proactive sending all happen in background tasks so the user never waits.
What the AI Does
Gemini 2.5 Flash does three distinct jobs in this system.
Conversation replies. Given a full context window including the user's personality, their top memories by importance, recent chat history, and the current message, it generates a short warm reply in a specific voice: human, not therapeutic, never corporate. It avoids phrases like "as an AI" or "I completely understand." It uses at most one emoji. It asks at most one question. It sounds like a person who knows you.
Memory extraction. After each conversation turn, it reads the exchange and returns structured JSON with new memories, updates to the personality profile, any events it detected, and any proactive tasks it thinks should be scheduled. This is how the system learns. Every conversation makes the next one smarter.
Proactive decisions. When the decision worker finds a reason to reach out, it passes the candidate and the full user snapshot to Gemini and asks: should we actually do this? It can say no. It can rewrite the message. It acts as a filter to make sure outreach feels thoughtful and not random.
Technologies
| Layer | Technology |
|---|---|
| AI model | Google Gemini 2.5 Flash via Vertex AI |
| Backend API | FastAPI + Uvicorn |
| Database | MongoDB with async Motor driver |
| Telegram integration | python-telegram-bot 21.6 |
| Async runtime | Python asyncio throughout |
| HTTP client | httpx |
| Config management | pydantic-settings |
| Deployment credits | Google Cloud ($300 Rapid Agent hackathon credits) |
What We Learned
Building a proactive AI system is completely different from building a reactive one. Most of the hard problems are not about what to say. They are about when to say it, whether to say anything at all, and how to make it feel natural instead of surveillance-y.
We learned that the decision layer matters more than the generation layer. Gemini can always write a decent message. The hard part is deciding whether sending any message right now is a good idea. Getting that wrong, even once, breaks the trust the whole thing is built on.
We also learned that memory architecture is everything. It is not enough to store facts. You need to store them in a way that lets you rank them, retrieve them efficiently, and combine them into a picture that feels like a real person's understanding of someone else. Importance scores, memory types, a rolling conversation summary, and a separate personality profile all ended up being necessary for context that actually reads like someone who knows you.
The quiet hours and cooldown system taught us a lot about what "respectful" means in a proactive system. It is not a nice-to-have. It is the thing that separates a helpful companion from something that feels like an intrusion.
Challenges
The biggest technical challenge was making the proactive system feel non-creepy. Early versions sent messages at weird times or doubled up because two workers raced to process the same task. We solved the timing problem with timezone-aware quiet hours and per-user cooldown windows. We solved the race condition with atomic status transitions in MongoDB: a task moves from "pending" to "sending" in a single find_one_and_update call, so only one worker ever processes it.
Prompt engineering for extraction was harder than we expected. Getting Gemini to consistently return clean structured JSON, with the right fields, at the right level of inference (never assume neurodivergence, always infer attachment style from evidence), required careful iteration on the extraction prompt and a lot of edge case handling.
The rolling conversation summary was a late addition but ended up being critical. Without it, the context for long-term users became massive and expensive. Condensing each conversation into a ~150 word snapshot that Gemini updates after every exchange gave us persistent memory without ballooning the prompt.
Try It
The bot is live at @pokeai_test1_bot.
Text it anything. It will keep track of what matters. And at some point, without you asking, it will poke you first.


Log in or sign up for Devpost to join the conversation.