-

End result of a verification game. Learner won with 4 Pokemon left in only 8 turns.
-
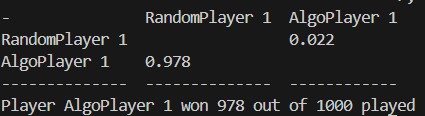
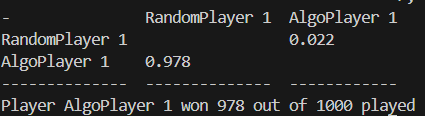
Winrate of verification games after a round of testing. This is not the most up to date model, but demonstrates learning.

Inspiration
When I think of reinventing the wheel, I think of making existing technology smarter. With a background in game development, I wanted to create a system that is smarter than some current technology. Thus the idea to create an AI that can play a very complicated game came to my head. Pokemon is one of the most complicated strategy games ever created, with trillions [citation needed] of possible games, learning Pokemon is a bigger challenge than learning chess. Thus, I tried to make a robot learn it better than I can.
What it does
The program runs simulated battles using the Pokemon Showdown API. Over time, it learns how to play the game better using PPO and a network. After playing against a random player for baseline data, the program then battles against itself to get better. Then it plays against that version, again and again, slowly learning over time. This can be thought of like a ladder system in a game, where winning increases the difficulty of opponents faced. The weights can then be configured to play live on servers against real people.
How we built it
The Pokemon Showdown website API is open source. Additionally, there is a python module, poke-env, that uses a Showdown server to create a petting-zoo compatible learning environment. From this, I created a custom environment to parse the details of a match to the AI, then used CleanRL's PPO with a pytorch neural network to facilitate learning.
Challenges we ran into
The creation of the environment had many stalls, as while the APIs are useful, they did not enable learning. The hardest part was masking, which is blocking moves that are not available (i.e. switching to a fainted pokemon, using an attacking move on yourself, etc.). Additionally, near the end of training, it was discovered that the Pokemon Zoroark caused many many problems. Zoroark's ability lets it disguise itself as a different Pokemon from your team. However, it is really good at this. So good that the environment couldn't tell when the original Pokemon or Zoroark was out. Thus, Zoroark was disabled in this environment as a simple solution.
Accomplishments that we're proud of
On the first run-through, the algorithm did WORSE than random choices. One of the accomplishments I am most proud of is being able to isolate the environments scope to measure that the program can actually learn. On a limited dataset in a fixed situation (as the epochs needed for the full scope of this project is massive) my program was able to achieve consistently over a 95% winrate against random players that focused on attacking. This demonstrates the clear ability to learn and develop.
What we learned
Reinforcement learning environments are based on steps. Parsing the game world into an environment was a challenge, but a worthwhile one. The biggest accomplishment was being able to fine-tune the algorithm to facilitate learning. This included varying the size of the neural network, how many layers there were, and how many nodes per layer were used.
What's next for Poke-AI
Continuing learning on broader situations to create an even better algorithm. Ideally, this project will be able to be implemented into an extension for Pokemon Showdown that can recommend moves to the player.
Built With
- cleanrl
- poke-env
- pokemon-showdown
- python
- torch

Log in or sign up for Devpost to join the conversation.