Inspiration
Machine learning models strongly depend on the quality of their training data. However, data poisoning attacks are often subtle and do not immediately affect validation accuracy.
If we represent data using a model ( f(x) ), poisoned samples may preserve labels but still distort internal representations.
Instead of waiting for model failure, we wanted to detect poisoning early, at the data level.
This insight inspired Poison Guard — a system that monitors embedding behavior to protect ML pipelines.
What it does
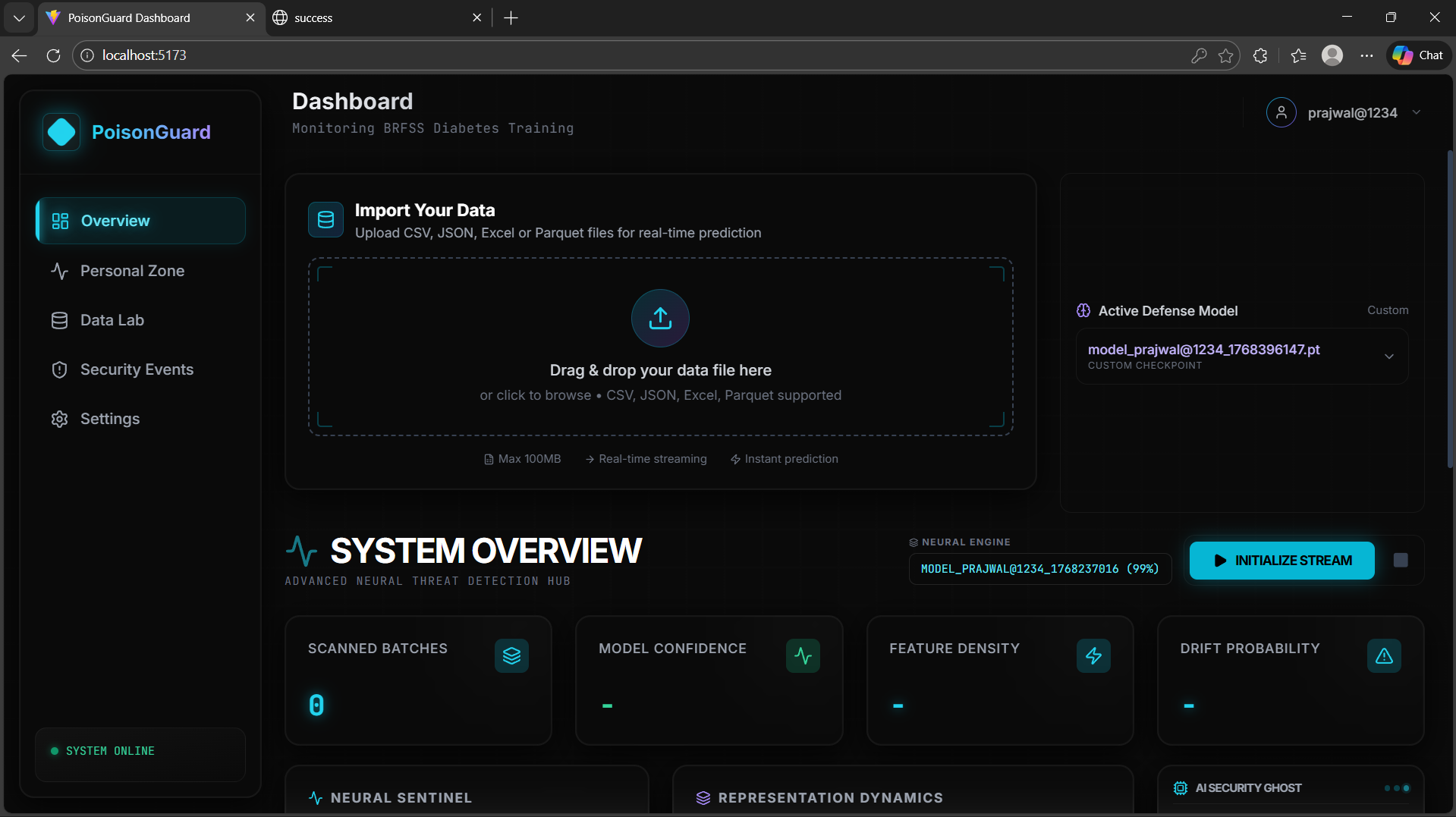
Poison Guard is a real-time data poisoning detection system.
It:
- Learns stable data representations using contrastive learning
- Monitors embedding drift and distribution changes
- Detects poisoning using multiple complementary signals
- Uses an LLM (Google Gemini) to catch semantic inconsistencies
- Provides live alerts and dashboards
Poison Guard acts as a security layer for training data.
How we built it
Representation Learning
Each input sample ( x ) is encoded into a latent representation:
( z = f(x) )
where ( f ) is a neural encoder trained to preserve similarity between clean samples.
A projection layer ( g(z) ) improves separation, and the model is trained using contrastive loss so that similar samples stay close in embedding space.
Poisoning Detection Signals
We continuously monitor three signals:
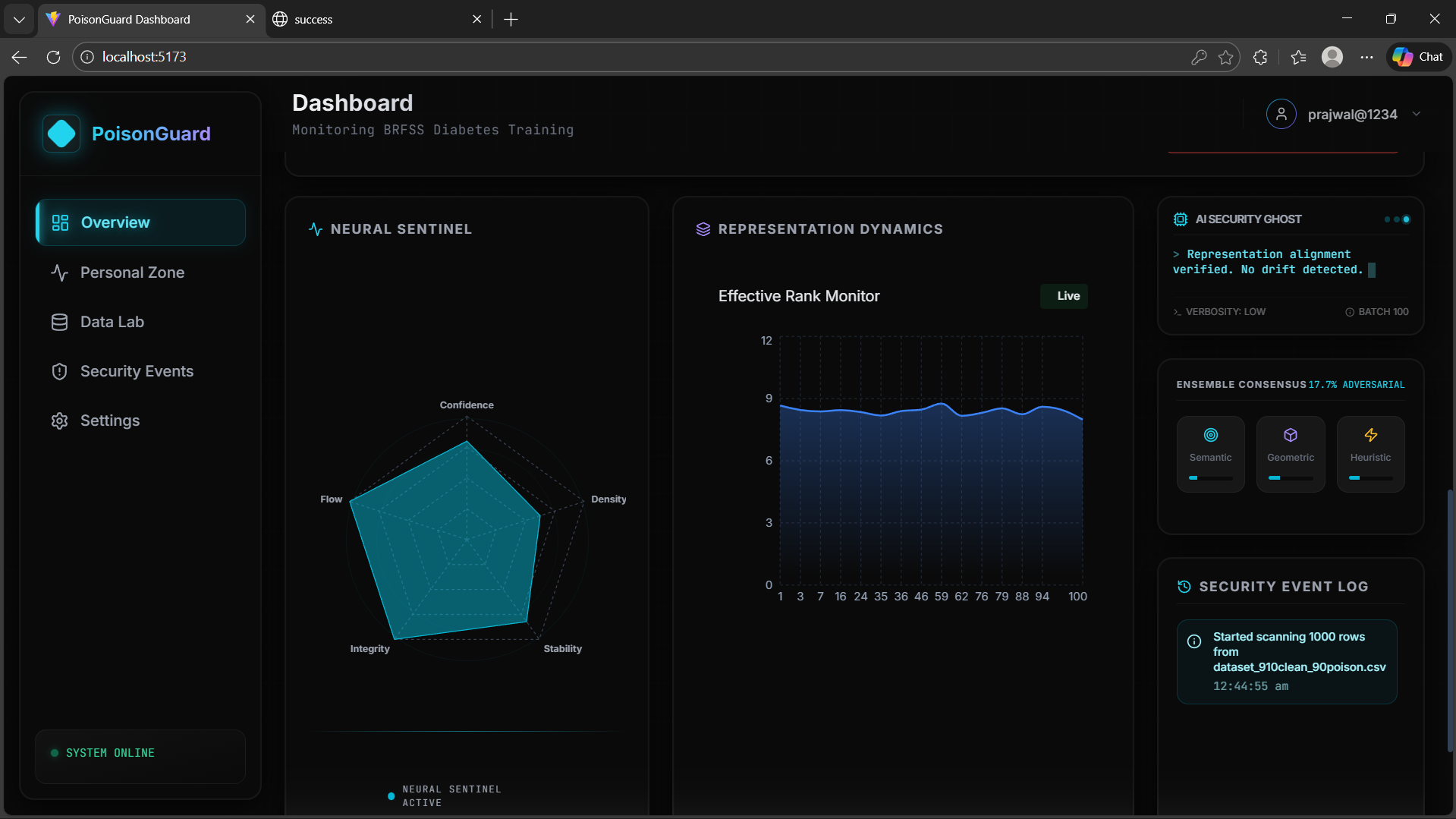
Effective Rank
Measures how spread out embeddings are. Poisoned data increases representation complexity.Embedding Density
Clean samples form dense clusters, while poisoned samples appear in low-density regions.Drift Score
Measures changes between consecutive embedding distributions using mean and variance shifts.
A sample is flagged only when multiple signals agree, reducing false positives.
LLM-Based Semantic Check
Some poisoned samples look statistically valid but are logically incorrect.
We integrate Google Gemini to:
- Analyze feature relationships
- Detect semantic contradictions
- Flag logically inconsistent data
This adds a semantic defense layer on top of numerical detection.
Real-Time Architecture
Incoming Data → Encoder → Embedding Metrics → Drift Detection → Alert System
- Backend streams metrics using WebSockets
- Frontend displays real-time charts and alerts
- Engineers receive instant warnings
Challenges we ran into
- Applying contrastive learning to tabular data
- Balancing early detection and false alarms
- Efficient real-time monitoring
- Integrating LLM reasoning without latency
- Making the system model-agnostic
Accomplishments that we're proud of
- Detects poisoning before training is affected
- Works in real-time pipelines
- Combines statistical, geometric, and semantic signals
- Provides interpretable alerts
- Scales to streaming datasets
What we learned
- Data poisoning often hides in representation space
- Accuracy alone is not a security guarantee
- Monitoring embeddings provides early warning
- LLMs enhance robustness through semantic reasoning
- ML systems need observability, not just performance
What's next for Poison Guard
- Support for image and text data
- Automatic data quarantine
- Integration with MLOps platforms
- Continuous learning over time
- Open-source release
Poison Guard protects ML systems where attacks start — the data.
Built With
- fastapi
- framer-motion
- google-gemini-2.0-flash
- gridfs
- mongodb
- numpy
- pandas
- python
- pytorch
- react
- recharts
- scikit-learn
- tailwind-css
- typescript
- uvicorn
- websockets

Log in or sign up for Devpost to join the conversation.