-
-

Landing Page
-
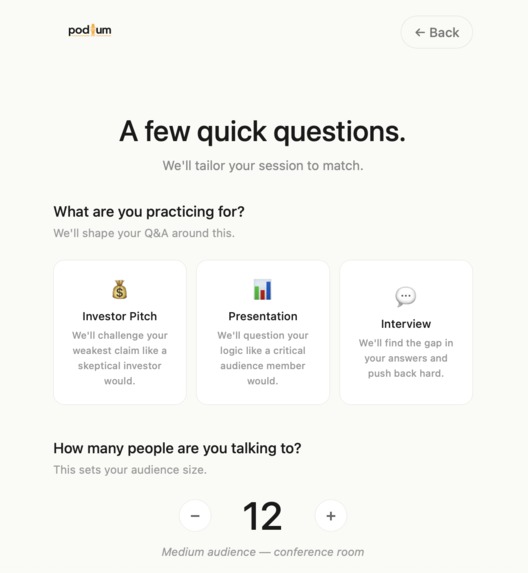
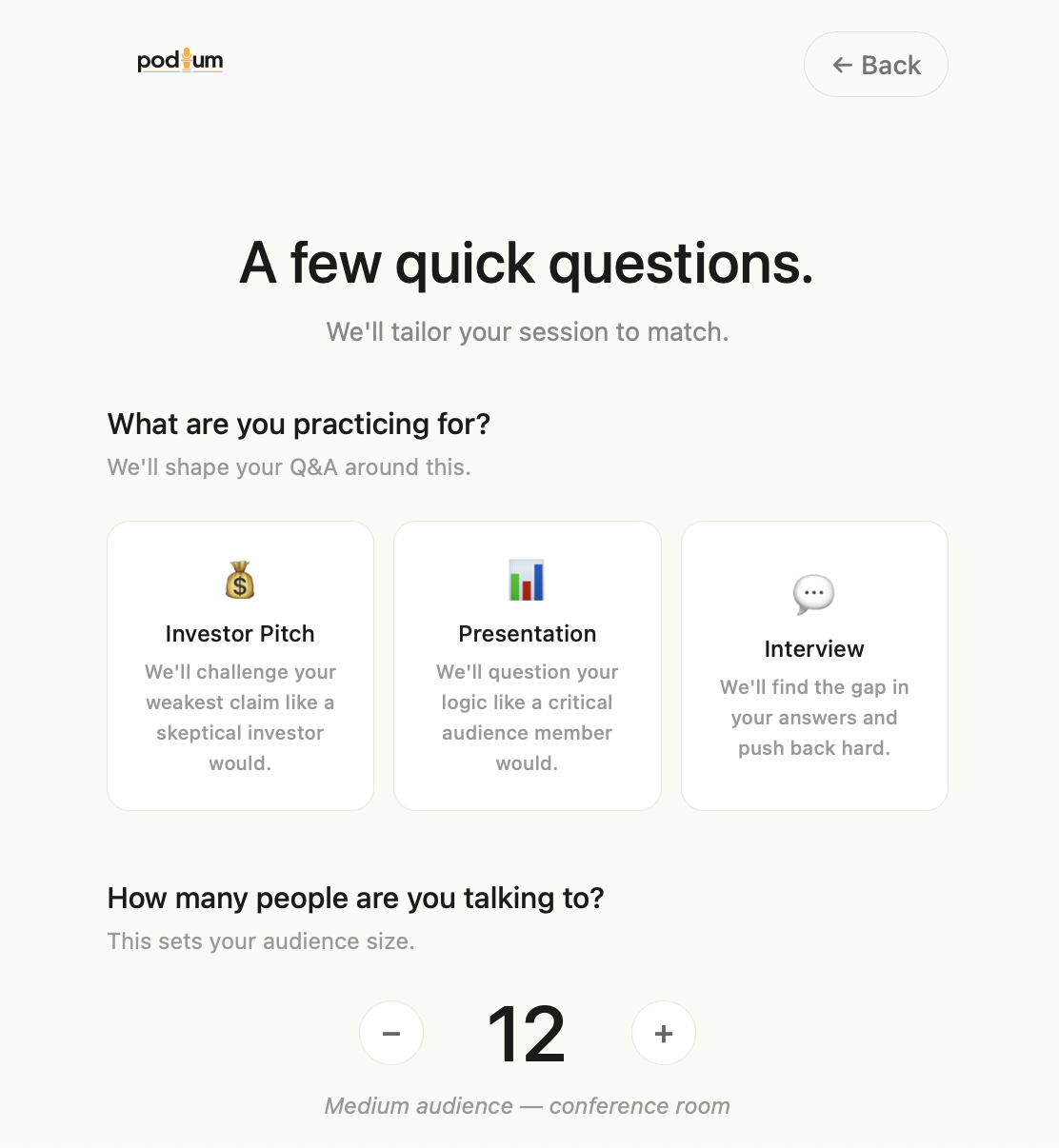
Pre-Session UI
-
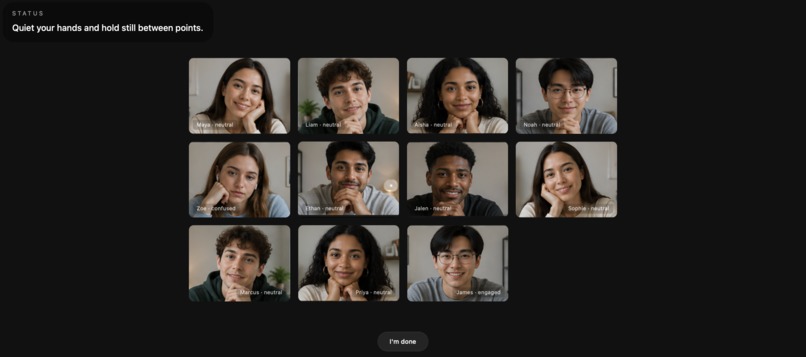
Live Session with Reactive AI-Powered Audience


Inspiration
Public speaking is the most common fear in the world — and one of the most consequential skills you can develop. The problem isn't that people don't want to practice. It's that there's nothing real to practice against. Mirrors don't react. AI script tools give generic feedback. Nothing puts you in front of a crowd that actually responds to how you're performing.
We've all felt this firsthand — across pitches, presentations, and interviews. So we built Podium.
What it does
Podium drops you in front of a live, reactive AI audience and coaches you on exactly what you did.
You choose your mode — Pitch, Interview, or Presentation — set your audience size and time limit, then start speaking. Your audience reacts in real time. Lose the room and faces shift from engaged to bored. Recover your delivery and watch them come back.
When you finish, Podium triggers a Q&A — pushing back on your weakest claim just like a real audience would.
After the session you get a full results dashboard:
- Your session recording synced to a timestamped feedback timeline
- Engagement score, filler word count, and eye contact analysis
- High and low moments identified by the AI
- Strengths and improvements distilled from your full session
How we built it
Podium is a real-time multi-agent system built on a WebSocket backbone connecting a React frontend to a Python backend.
Five specialized agents run simultaneously during every session:
- SpeechAgent — transcribes audio via ElevenLabs STT, analyzes pacing, filler words, and WPM
- VisionAgent — runs computer vision on the camera feed, tracking eye contact and presence
- ArgumentAgent — evaluates claim strength and identifies the logical gap a skeptical audience would challenge
- AudienceAgent — scores engagement per audience member, driving the reactive face animations
- FusionAgent — synthesizes signals from all four agents into a unified session model
At session end, the CoachAgent processes the fused output to generate the full breakdown. The multi-agent architecture is registered and coordinated via Fetch.ai's Agentverse, with each agent running as an autonomous uAgent communicating over Fetch.ai's messaging protocol.
Stack: React + Vite · FastAPI · Python WebSockets · ElevenLabs STT + TTS · MediaRecorder API · MediaPipe · MongoDB · Fetch.ai uAgents · Groq LLaMA
Challenges we ran into
Real-time multi-agent coordination — Fusing signals with different latencies (vision is fast, argument analysis is slower) without introducing lag in the audience animation loop required careful async design.
Video recording lifecycle across React screens — The MediaRecorder blob URL is created inside the live session component. When React unmounts the component on navigation, cleanup fires and revokes the URL before the results screen can load it. We solved this by transferring blob ownership to the parent before cleanup ran.
Audience engagement that feels real — Tuning the engagement scoring so the audience reacts believably took significant iteration. Too reactive and it feels gameable. Too slow and the feedback loop is useless.
Accomplishments we're proud of
- A fully working end-to-end session loop — setup, calibration, live audience, real-time analysis, recording, and post-session results
- Genuine audience reactivity that makes the stakes feel real the moment faces start looking away
- Multi-modal analysis — speech, vision, and argument — running in parallel and fused into one coherent breakdown
What we learned
Building Podium taught us what it actually means to design for real time. It's not just making things fast — it's deciding what to process synchronously, what can lag slightly, and how to keep the user experience coherent across signals arriving at different speeds.
We also learned how much agent boundary design matters. Early versions had agents doing too much. Splitting responsibilities cleanly — and letting FusionAgent handle synthesis at session end rather than mid-session — was the architectural shift that made the whole pipeline stable.
What's next
- Voice-driven Q&A — audience members ask questions aloud via TTS
- Longitudinal tracking — see your engagement score and filler count improve across sessions
- Shareable PDF reports — export a breakdown to share with a coach or mentor
- Mobile — practice anywhere, not just at a desk
Built With
- elevenlabs-speech-to-text/text-to-speech-apis
- fastapi
- groq
- html/css
- mediarecorder-api
- mongodb
- python
- react
- typescript
- vite
- web-audio-api
- websockets

Log in or sign up for Devpost to join the conversation.