-
-

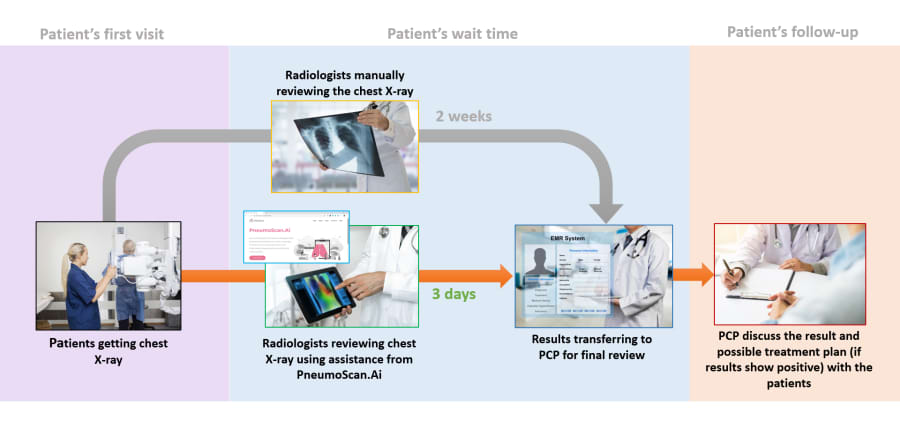
Fig. 1: Current chest X-ray diagnosis vs. novel process with CovidScan.ai.
-
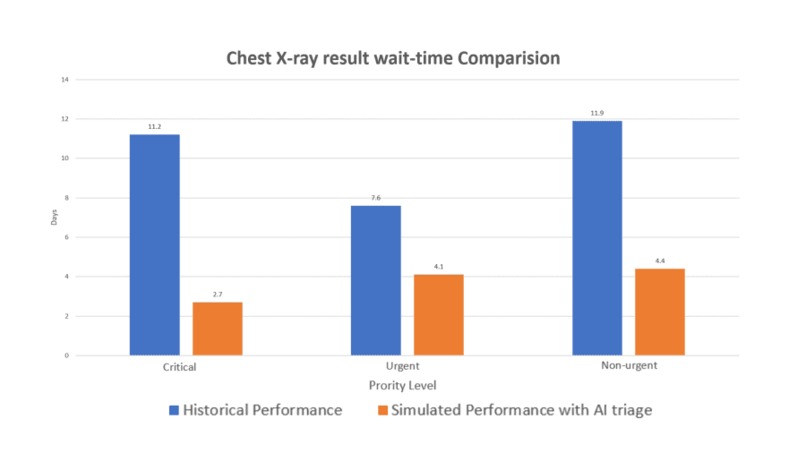
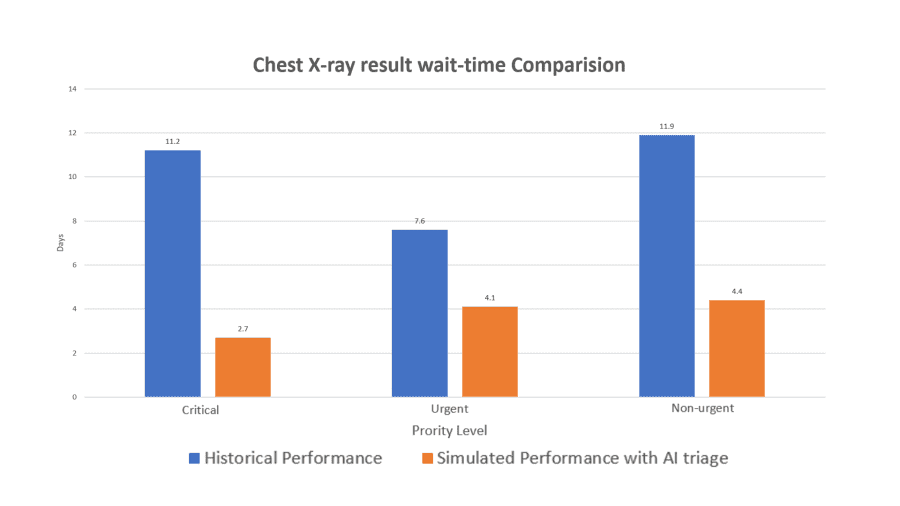
Fig. 2: Chart of wait-time reduction of AI radiology tool (data from a simulation stud reported in Mauro et al., 2019).
-
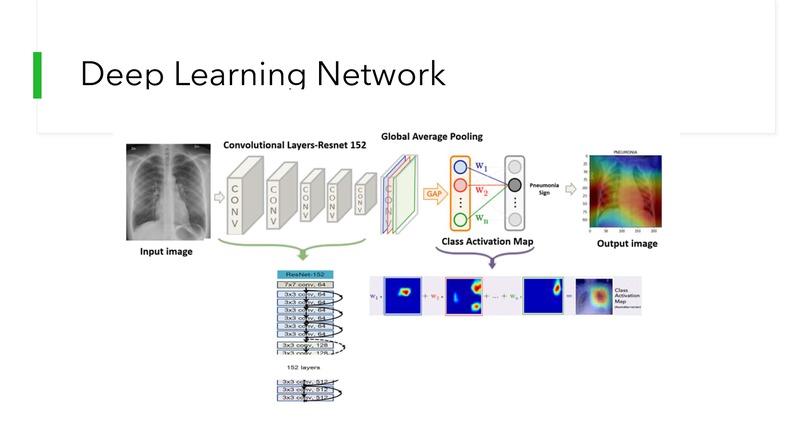
Fig 3: Deep neural network architecture. Our model includes Resnet, Global Max Pooling and Activation Map.

Building an AI COVID-19 Product Using Transfer Learning in Pytorch (Implementation Time: Under 2 hours)
![]()
This project won 2nd place at FB AI Hackathon
Background:
In screening for COVID-19, patients can first be screened for flu-like symptoms using a nasal swap to confirm their status. After 14 days of quarantine for confirmed cases, the hospital draws the patient’s blood and takes the patient’s chest X-ray. Chest X-ray is a golden standard for physicians and radiologists to check for the infection caused by the virus. An x-ray imaging will allow your doctor to see your lungs, heart, and blood vessels to help determine if you have Pneumonia. When interpreting the x-ray, the radiologist will look for white spots in the lungs (called infiltrates) that identify an infection. This exam, together with other vital signs such as temperature, or flu-like symptoms, will also help doctors determine whether a patient is infected with Pneumonia or other Pneumonia-related diseases. The standard procedure of Pneumonia diagnosis involves a radiologist reviewing chest x-ray images and send the result report to a patient’s primary care physician (PCP), who then will discuss the results with the patient.

Fig 1: Current chest X-ray diagnosis vs. novel process with PneumoScan.ai.
A survey by the University of Michigan shows that patients usually expect the result came back after 2-3 days a chest X-ray test for Pneumonia. (Crist, 2017) However, the average wait time for the patients is 11 days (2 weeks). This long delay happens because radiologists usually need at least 20 minutes to review the X-ray while the number of images keeps stacking up after each operation day of the clinic. New research has found that an artificial intelligence (AI) radiology platform such as our CovidScan.ai can dramatically reduce the patient’s wait time significantly, cutting the average delay from 11 days to less than 3 days for abnormal radiographs with critical findings. (Mauro et al., 2019) With this wait-time reduction, patients I critical cases will receive their results faster and receive appropriate care sooner.

Fig 2: Chart of wait-time reduction of AI radiology tool (data from a simulation stud reported in Mauro et al., 2019).
In this tutorial, we’ll show you how to use Pytorch to build a machine learning web application to classify whether a patient has Pneumonia-related disease (including COVID-19) or no sign of any infection (normal) from chest x-ray images. We will focus on the Pytorch component of the AI application. We combine COVID-19 images with Pneumonia since not a big amound of COVID image made publicly avaible for open-source. That will create a huge problem with imbalance class. Therefore, to make our tutorial more disgetible and accessible for beginners, we only use a binary classification (Pneumonia or Normal) in this tutorial. At the end of this tutorial, we will discuss other additional resources for the multi-classification of different diseases on chest X-ray (including COVID-19) in the section of additional resources.
Below are the outline of steps we’ll go over in this tutorial (We also attach the approximate time that you should spend on reading and implementing the code of each section to understand it thoroughly):
1. Collecting Dataset (2 minutes)
2. Getting Started & Preprocessing the Data (10 minutes)
3. Building the Model (45 minutes)
a) Basics of Transfer Learning
b) Architecture of Resnet 152 with Global Average Pooling layer
4. Developing the Web-app (30 minutes)
5. Summary & Additional Resources (5 minutes)
1. Collecting the Data (2 minutes):
To build the chest X-ray detection models, we used combined 2 sources of the dataset:
- The first source is the RSNA Pneumonia Detection Challenge dataset available on Kaggle contains several deidentified CXRs with 2 class labels of Pneumonia and normal.
- The COVID-19 image data collection repository on GitHub is a growing collection of deidentified CXRs from COVID-19 cases internationally. The data is collected by Joseph Paul Cohen and his fellow collaborators at the University of Montreal
Eventually, we combine the Pneumonia case and COVID case into the Pneumonia-related disease category and the rest in the normal category. our dataset consists of 2624 training data points, 228 validation data points, and 228 test data points (80-10-10 ratio). You can download our prepared data here.
For deidentified image for blind test later, you can download this data.
2. Getting Started and Preprocessing the Data (10 minutes):
Since the training process on imaging data of over 2300+ images will be intensive for our local computer, it is a good idea to leverage the free GPU provided by Google Colab. Colab is a good tool for beginners to use since many people may not have access to advanced computing power in hands. More details on how to set up Google Colab notebook can be found here.
To install the required packages, simply run this one line of code:
!pip install torch==1.0.1 torchvision==0.2.2 PIL scipy time copy
After setting up the Colab notebook on Google free GPU, now we can get started with our project. First, we import all the required package:
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt #To visualize the data
import copy
import time #To track the running time of our model
import PIL # To load image data to Python
import scipy.ndimage as nd #To perform preprosssing on image data
The more data, the better the model will learn. Hence, apply some data augmentation to generate different variations of the original data to increase the sample size for training, validation and testing process. This augmentation can be performed by defining a set of transforming functions in the torchvision module. The detailed codes are as following:
transformers = {'train_transforms' : transforms.Compose([
transforms.Resize((224,224)),
#transforms.CenterCrop(224),
transforms.RandomRotation(20),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
'test_transforms' : transforms.Compose([
transforms.Resize((224,224)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
'valid_transforms' : transforms.Compose([
transforms.Resize((224,224)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])}
trans = ['train_transforms','valid_transforms','test_transforms']
path = "./data/"
categories = ['train','val','test']
After defining the transformers, now we can use torchvision.datasets.ImageFolder module we load images from our dataset directory and apply the predefined transformers on them as following:
dset = {x : torchvision.datasets.ImageFolder(path+x, transform=transformers[y]) for x,y in zip(categories, trans)}
dataset_sizes = {x : len(dset[x]) for x in ["train","test"]}
num_threads = 4
# The DataLoader module generates images in batches.
dataloaders = {x : torch.utils.data.DataLoader(dset[x], batch_size=256, shuffle=True, num_workers=num_threads)
for x in categories}
To make sure we are loading the data correctly and the augmentation is performed, let’s check some generated data using matplotlib and numpy using this block of code:
def imshow(inp, title=None):
inp = inp.numpy().transpose((1,2,0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std*inp + mean
inp = np.clip(inp,0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
inputs,classes = next(iter(dataloaders["train"]))
out = torchvision.utils.make_grid(inputs)
class_names = dataset["train"].classes
imshow(out, title = [class_names[x] for x in classes])

From the plot of a batch of sample images, we can see the data is loaded properly and augmented in different variations. Then, we can start our model building process.
3. Building the Model (45 minutes):
a) Basics of Transfer Learning:
In order to predict well the classes of an image, the neural network needs to be super efficient in extracting the features from the input images. Hence, the model first needs to be trained on a huge dataset to get really good at feature-extraction. However, not everyone, especially beginners in ML, accesses to powerful GPU or the in-depth knowledge to train on such big data. That is why we leverage transfer learning in our model building process, which saves us a lot of time and trouble in building a state-of-art model from scratch. Luckily for us, the torchvision module already includes several state of the art models trained on the huge dataset of Imagenet (more than 14 millions of 20,000 categories). Hence, these pretrained model is crazily good at feature extraction of thousand type of objects.
You can read more about transfer learning in imaging in this Pytorch document.
b) Architecture of Resnet 152 with Global Average Pooling layer:
For the project, we use the pretrained ResNet 152 provided in Pytorch libary. ResNet models is arranged in a series of convolutional layers in very deep network architecture. The layers are in form of residual blocks, which allow gradient flow in very deep networks using skip connections as shown in fig. These connections help preventing the problem of vanishing gradients which are very pervasive in very deep convolutional networks. In the last layer of the Resnet, we use the Global Average Pooling layer instead of fully connected layers to reduce the number of parameters created by fully-connected layers to zero. Hence, we can avoid over-fitting (which is a common problem of deep network architecture as Resnet). More details on Resnet models here and Global Max Pooling here. At the end of the network, we will leverage the Global Max Pooling to visualize the class activation map, which we will discuss in section 2.e. The whole architecture can be found in the figure below:

c) Retraining Resnet 152 Model in Pytorch:
Before we get into the actual model building process, you can refresh your memory on the basics of deep learning using this recommended tutorial from Pytorch.
After refreshing your memory on the basics, we can start with this project using the COVID-19 & Pneumonia chest X-ray data. First, we need to initialize our model class by calling the nn.Module, which create a graph-like structure of our network. In particularly, as we mentioned earlier, the pretrained model of Resnet152 was used in our training process. This transfer learning give us a big advantage in retraining on Hence, we need to define our ResNet-152 in the init of nn.Module for transfer learning. Then after define the init function, we need to create a forward function as part of the requirement for Pytorch.
##Build model
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = torchvision.models.resnet152(pretrained=True)
self.classifier = nn.Sequential(
nn.Linear(self.model.fc.in_features,2),
nn.LogSoftmax(dim=1)
)
for params in self.model.parameters():
params.requires_grad = False
self.model.fc = self.classifier
def forward(self, x):
return self.model(x)
Then, we define the fit function within this class. We will actually use the fit function to retrain the Resnet 152 on our data:
def fit(self, dataloaders, num_epochs):
train_on_gpu = torch.cuda.is_available()
optimizer = optim.Adam(self.model.fc.parameters())
scheduler = optim.lr_scheduler.StepLR(optimizer, 4)
criterion = nn.NLLLoss()
since = time.time()
best_model_wts = copy.deepcopy(self.model.state_dict())
best_acc =0.0
if train_on_gpu:
self.model = self.model.cuda()
for epoch in range(1, num_epochs+1):
print("epoch {}/{}".format(epoch, num_epochs))
print("-" * 10)
for phase in ['train','test']:
if phase == 'train':
scheduler.step()
self.model.train()
else:
self.model.eval()
running_loss = 0.0
running_corrects = 0.0
for inputs, labels in dataloaders[phase]:
if train_on_gpu:
inputs = inputs.cuda()
labels = labels.cuda()
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = self.model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print("{} loss: {:.4f} acc: {:.4f}".format(phase, epoch_loss, epoch_acc))
if phase == 'test' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(self.model.state_dict())
time_elapsed = time.time() - since
print('time completed: {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 600))
print("best val acc: {:.4f}".format(best_acc))
self.model.load_state_dict(best_model_wts)
return self.model
After building the Model module with the pretrained Resnet 152, we can now use this model to retrain on our training using the fit function. This function also takes care of cross-validation using our validating data. To make sure the model has enough time to learn the features in our chest X-ray data, we will set the epoch to 100.
model = Model()
model.fit(dataloaders, 100)
We then save the best weights from this model to so we can load to predict on testing data using torch.save:
torch.save(model.state_dict(), "./Best_weights/best_covid_model.pth")
When we want to load this trained weights back to the model for prediction on new data, we just need to follow these lines of code:
state_dict = torch.load("./Best_weights/best_covid_model.pth")
model.load_state_dict(state_dict, strict=False)
model_ft = model.model
model_ft = model_ft.eval()
d) Model Evaluation:
After training on the data, we can now test the performance of our model using the accuracy metrics. Let's see what is the accuracy of our model on the training set:
def check_accuracy(loader, model):
num_correct = 0
num_samples = 0
model.eval()
with torch.no_grad():
for x, y in loader:
scores = model(x)
_, predictions = scores.max(1)
num_correct += (predictions == y).sum()
num_samples += predictions.size(0)
print(f'Got {num_correct} / {num_samples} with accuracy {float(num_correct)/float(num_samples)*100:.2f}')
model.train()
check_accuracy(dataloaders['train'], model)
Got 2594 / 2624 with accuracy 98.86
Let's see what is the accuracy of our model on the testing set:
check_accuracy(dataloaders['train'], model)
Got 188 / 228 with accuracy 82.46
The model seems to perform well on both the training and testing set. However, we still see some slight overfitting since the training accuracy is higher than the testing accuracy (Read more about over-fitting here. We can still improve this model. However, since handling overfitting is not a focus of this tutorial, we will not go details into it. You can read about a different way to handle overfitting here
e) Building the Activation Map For Visualization:
We learned earlier that the last layer of our network is the Global Average Pooling layer. This last layer is useful for reducing the tensor of trained weights from h x w x d to 1 x 1 x d. Then, we calculated the weighted sum from this 1 x 1 x d dimensional tensor and then fed into a softmax function to find the probabilities of the predicted class (Pneumonia or Normal). After getting the confirmed class from the model, we can map back this class to the weighted sum tensor to plot the class activation map for visualization. You can read more about class activation map here
In PyTorch, we can use the register_forward_hook module to obtain activation of the last convolutional layer as described above. Hooks are specific functions, which can be attached to every layer and called each time the layer is used. Hence, they allow you to freeze the execution of the forward or backward pass at a specific module and process its inputs and outputs. This proves to be useful in the task of getting the weights of specific layers for debugging. You can read more about hooks here.
The code for register_forward_hook() is as following:
class LayerActivations():
features=[]
def __init__(self,model):
self.hooks = []
#model.layer4 is the last layer of our network before the Global Average Pooling layer(last convolutional layer).
self.hooks.append(model.layer4.register_forward_hook(self.hook_fn))
def hook_fn(self,module,input,output):
self.features.append(output)
def remove(self):
for hook in self.hooks:
hook.remove()
After defining the LayerActivation module, we can use this module to visualize the predicted output on testing set. Hence, for convinience, we define a function called predict_img so we can use this predict and automatically visualize the Activation Map on each images later. The function is defined as following:
def predict_img(path, model_ft):
image_path = path
img = image_loader(image_path)
acts = LayerActivations(model_ft)
img = img.cpu()
logps = model_ft(img)
ps = torch.exp(logps)
out_features = acts.features[0]
out_features = torch.squeeze(out_features, dim=0)
out_features = np.transpose(out_features.cpu(),axes=(1,2,0))
W = model_ft.fc[0].weight
top_probs, top_classes = torch.topk(ps, k=2)
pred = np.argmax(ps.detach().cpu())
w = W[pred,:]
cam = np.dot(out_features.cpu(), w.detach().cpu())
class_activation = nd.zoom(cam, zoom=(32,32),order=1)
img = img.cpu()
img = torch.squeeze(img,0)
img = np.transpose(img,(1,2,0))
mean = np.array([0.5,0.5,0.5])
std = np.array([0.5,0.5,0.5])
img = img.numpy()
img = (img + mean) * std
img = np.clip(img, a_max=1, a_min=0)
return img, class_activation, pred
Now, let's load the testing data folder and use this newly defined predict_img function to visualize all the testing images (with both prediction class and Activation map). The snipet of that code is as following:
test_dir='/Test_Set/'
from skimage.io import imread
from PIL import Image
import glob
image_list = []
for filename in glob.glob(test_dir+'/*.jpeg'):
#im=Image.open(filename)
image_list.append(filename)
f, ax = plt.subplots(4,4, figsize=(30,10))
def predict_image(image, model_ft):
img, class_activation, pred = predict_img(image, model_ft)
print(pred.item())
name = image.split("/")
name = name[len(name)-1].split(".")[0]
img = Image.fromarray((img * 255).astype(np.uint8))
plt.ioff()
plt.imshow(class_activation, cmap='jet',alpha=1)
plt.imshow(img, alpha=0.55)
plt.title(dset['test'].classes[pred])
plt.tight_layout()
# plt.show()
predict_image(image_list[12], model_ft)

Let's test another image:
predict_image(image_list[1], model_ft)

4. Developing the Web-app (30 minutes):
As you can see, the final results look really nice. This activation map is super informative for the radiologists to quickly pinpoint the area of infection on chest X-ray. To make our project more user-friendly. the final step is web-app development with an interactive UI. From our training the model, the best model was saved in a .pthf file extension. The trained weights and architecture from this .pth file are then deployed in a form of Django backend web app CovidScan.ai. While the minimal front-end of this web app is done using HTML, CSS, Jquery, Bootstrap. In our latter stage, the web-app will then be deployed and hosted on a Debian server.
The detailed web-development process is not in the scope of this tutorial since we focus more on the Pytorch model to make the beginner user understand how we get to the final visualization output from raw chest X-ray data. If you want to read more on how to implement the web-app, we can read the step-by-step instruction on this gitlab tutorial.
5. Summary & Additional Resources (5 minutes):
If you follow the learning pace listed in this tutorial, in under 2 hours, you already explored a 5-step deep learning model building process using Pytorch. You also went over the concept of transfer learning and the architecture of our Resnet 152 model. Also, you learned to visualize the Activation Map using the last layer of our trained network. Eventually, you took a peek inside how this deep neural network is deployed to a web-app demo.
For this project, we only implement a binary classification of 2 classes (Pneumonia and Normal). For multi-classes, you can also use our this chest X-ray dataset which is split into 4 classes of COVID-19, Bacterial Pneumonia, Viral Pneumonia and normal. However, since COVID-19 image daat is much smaller than other classes, you may need to get some basic on dealing with imbalance data which is somewhat an advanced data preprocessing concept. You can read about dealing with imbalanced classes here. If you want to get more inspiration on building an AI-based product from scratch with multi-class data using Pytorch and FastAi, you can check out this other project created by our team called HemoCount, which is also an award-winning project at TAMU Datathon 2020.
We hope you will have a good start by implementing this award-winning project and be inspired to join other hackathons or datathon competition to build many other awesome AI products from scratch! Lastly, have a good hacking day, fellow hackers!
References:
Crist, C. (2017, November 30). Radiologists want patients to get test results faster. Retrieved from https://www.reuters.com/article/us-radiology-results-timeliness/radiologists-want-patients-to-get-test-results-faster-idUSKBN1DH2R6
Mauro Annarumma, Samuel J. Withey, Robert J. Bakewell, Emanuele Pesce, Vicky Goh, Giovanni Montana. (2019). Automated Triaging of Adult Chest Radiographs with Deep Artificial Neural Networks. Radiology; 180921 DOI: 10.1148/radiol.2018180921


Log in or sign up for Devpost to join the conversation.