-
-

CPG of a basic program from the demo
-

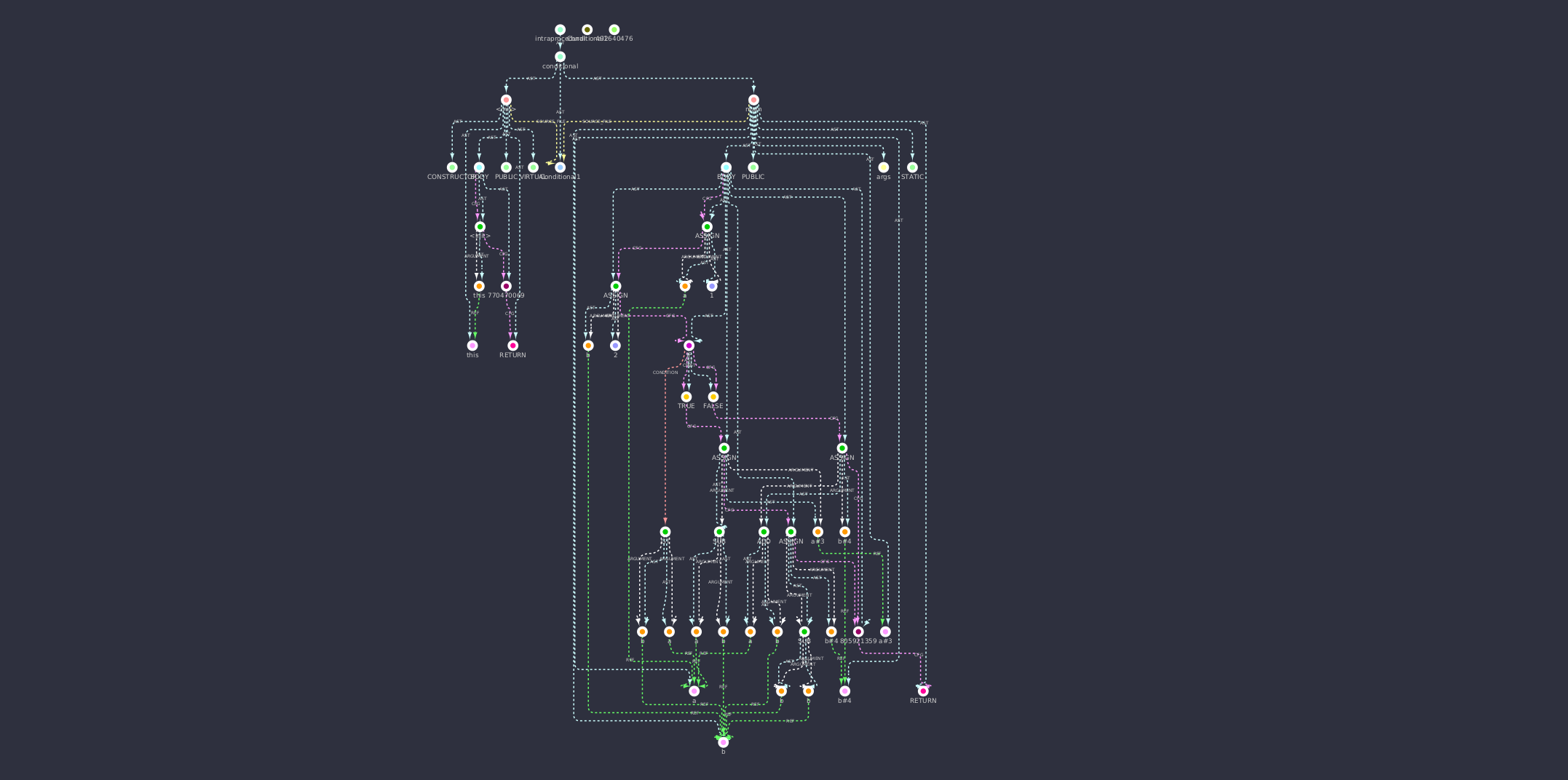
CPG of an if statement from the demo
-

CPG of a while loop from the demo
-

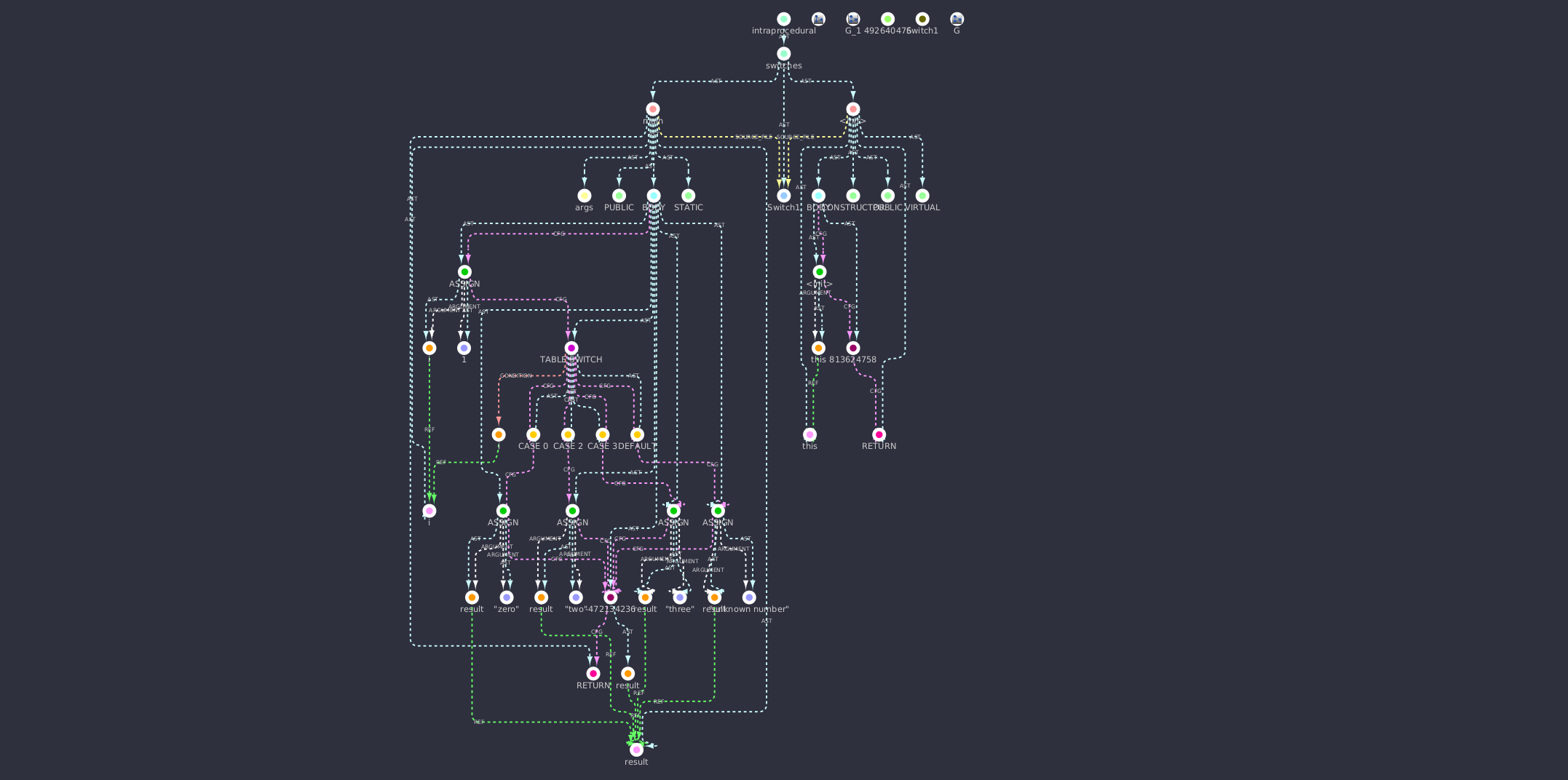
CPG of a switch statement from the demo


Inspiration
Plume is the library built as part of my post-graduate research inspired by the work done by Fabian Yamaguchi, Eric Bodden, Johannes Spath, and Karim Ali commercialized by ShiftLeft. Modelling static analysis problems as graph reachability problems has been done since the 90s but using graph databases to large programs and deep analytics are relatively new.
What it does
Plume allows one to extract a code property graph (a combination of a program's abstract syntax tree, control flow graph, and program dependence graph) from JVM bytecode and store it in a graph database. The storage backend (graph database) is pluggable and Plume currently supports TinkerGraph, JanusGraph, and TigerGraph. Plume has yet to complete a full interprocedural CPG extraction and thereafter will support program analysis.
The end goal is to perform an array of static analysis on a given program such as dataflow analysis and typestate analysis.
How I built it
Plume is built as a three-part library (only two available until the analysis component is added) comprised of the driver, extractor, and analysis respectively. The libraries are written in Kotlin using Gradle as the build tool and TravisCI + Codecov to run testing and measure code coverage.
The driver exposes a generic interface and domain to enforce the use of the CPG schema and implementing classes will communicate and configure to their assigned graph database appropriately. Soot is used to read and analyse the bytecode, extract the control-flow graph, and call graphs.
Challenges I ran into
For a large part of the year, the construction of the graph was done using ASM to build the graph directly from reading the bytecode which is complex and this took too much time and then rather opted to make use of Soot. The driver also had a few iterations before an appropriately generic set of methods could be agreed upon to unite all the functions necessary for the construction of the graph irrespective of which database was used.
Accomplishments that I'm proud of
The ability to create an intraprocedural code property graph and open-source a fairly polished tool that can be used in the static analysis in a domain where few code property graph tools exist with easy to follow documentation while supporting multiple graph databases.
What I learned
I started learning Kotlin and have begun to master it through the creation of this library. Beforehand I have not used TravisCI and Codecov to the degree that I have in this project. I also had not made use of the TigerGraph built-in endpoints and also created my own TigerGraph image in order to effectively test and load my CPG schema in during the CI/CD pipeline.
What's next for Plume CPG Analysis Library
Right now the library only creates intraprocedural CPGs and the next steps are:
- Create an interprocedural CPG with a sound call graph hierarchy
- Perform dataflow analysis
- Perform alias aware typestate analysis
- Support Neo4j and Amazon Neptune as graph databases
- Benchmark all supported graph databases in extraction and analysis speeds
- Publish my findings in a research paper
Built With
- gradle
- gremlin
- gsql
- janusgraph
- kotlin
- tigergraph
- tinkergraph











Log in or sign up for Devpost to join the conversation.