-
-
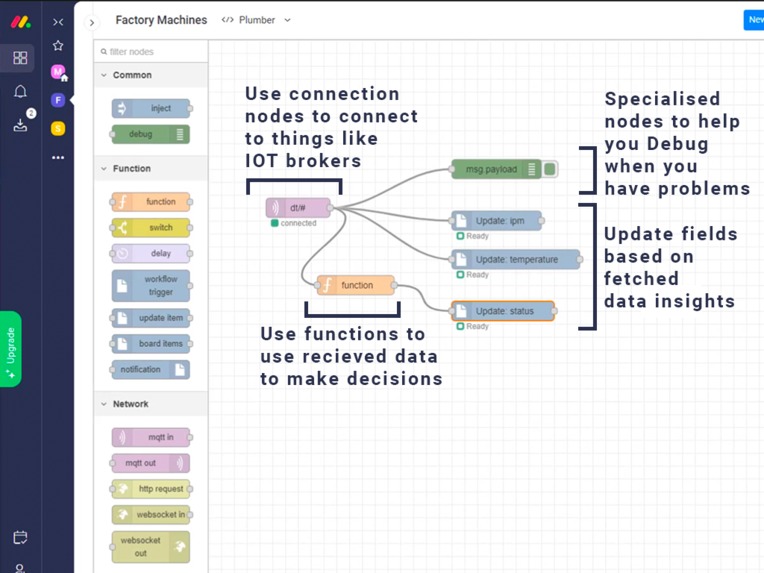
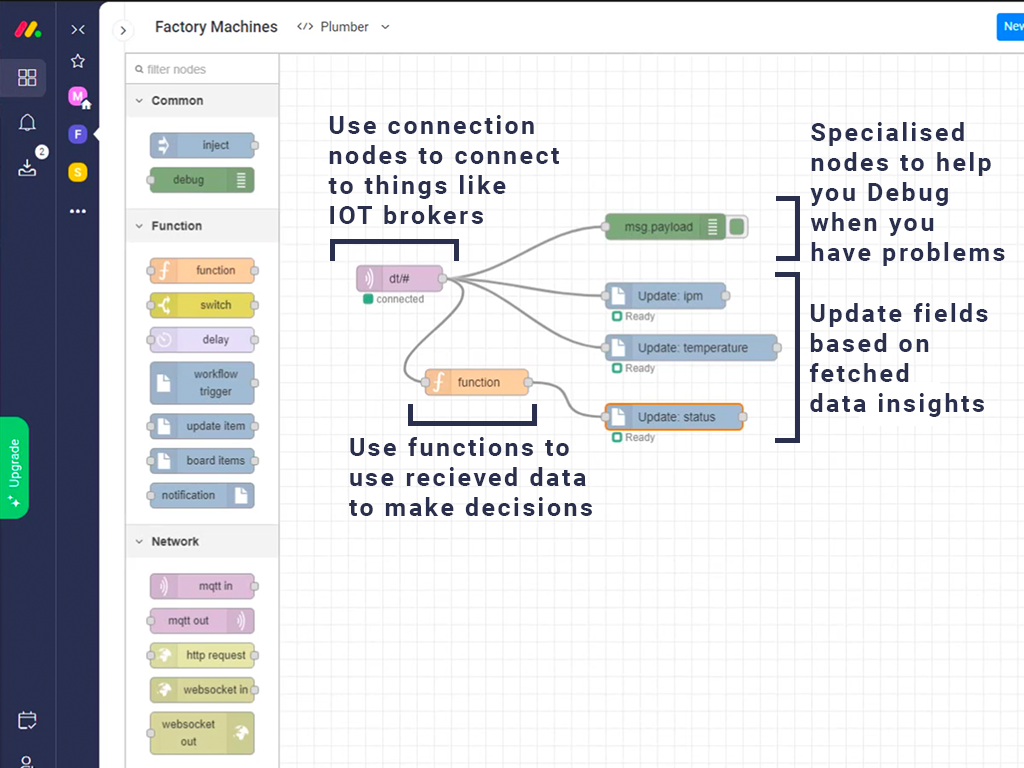
Complex pipeline connecting to an iot broker, defining a rule and updating items
-
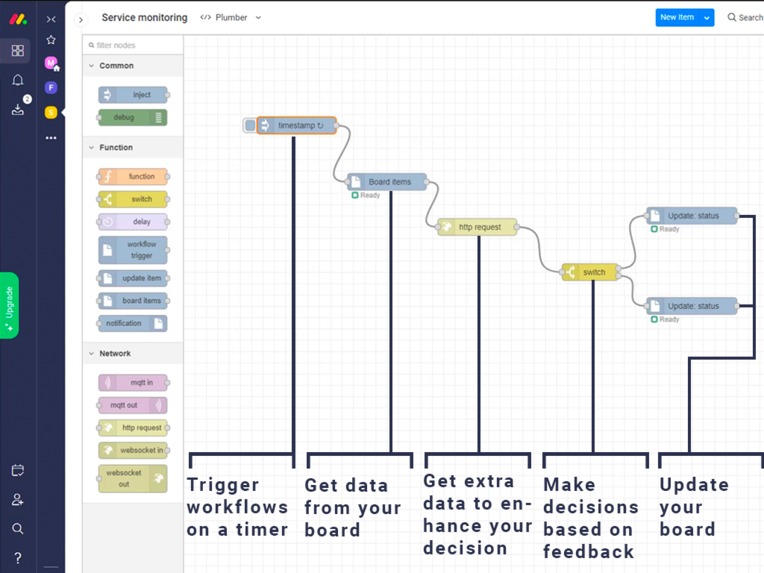
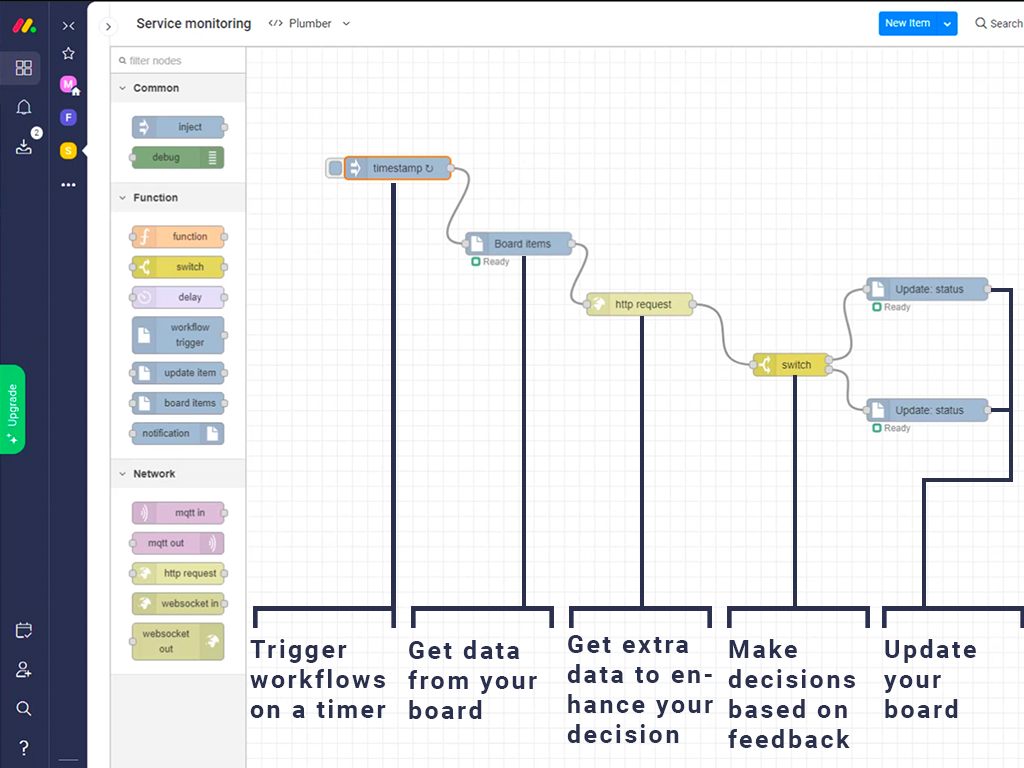
Simple pipeline updating status based on http errors
Inspiration
In recent years I have worked across many data intensive applications, in all of these projects one of our key challenges was trying to utilise this data to drive positive change for our customers. However in our experience developers often start writing this logic in code which limits customers making easy no-code adaptations later on. Our aim is to enable non-technical users to be able to create advanced data pipelines not currently possible in Monday.com and without the need for a developer. We believe, if you can define the logic, you should be able to automate it on Monday.com.
What it does
Plumber allows you to bring data from different data sources(IOT, Restful services, event queues) and bring them together to make advanced decisions that enable better automation and workflow.
In our spare time we teach children how to code at Coder dojo, from this experience we know the best way to represent logic to anyone is using visual building blocks with programs like Scratch. We’ve replicated this functionality for Plumber with a visual logic builder where you attach a series of function nodes together to make it easy for our professional users to reason their applications. We’ve also included debug nodes to make it easy for our users to figure out what's going wrong while they are building their data pipelines. It's really quick and easy to plug parts together and get some complicated data driven automation with just a couple of clicks. On average in our testing we have seen users go from a standard board to an enhanced board with their first data driven optimisation in less than 10 minutes.
How I built it
Plumbers backend is built using Nodejs with the next.js framework. It is broken into 2 main parts
- A subscription manager which handles authorisation to monday.com's api.
- A runtime instance which executes and maintains data pipelines. This runtime utilises a flow based methodology to cascade data down a predefined logical tree which can use multiple data sources to make complex decisions. Each node holds its own configuration which can depend on an input message.
These 2 parts come together into an easy to use, comprehensive data driven decision engine that enables users to automate just about any decision that they have data for from IOT to event queues to Restful services.
Challenges I ran into
The problem that we knew we were going to have was balancing having enough features to solve the bulk of automations users would need to do in a data pipeline and the service being simple enough for basic non-technical users to be able to pick it up and use it without help.
We are user centric design specialists where we work so we knew the answer was always going to be to test with users regularly and iterate with lessons learned.
We defined a baseline test of a process flow that we asked all users to attempt in our user testing. We continued to iterate and user test until we observed users consistently being able to achieve the task. This is how we knew that the service was sufficiently well balanced.
Accomplishments that I'm proud of
When I started this project, I cared heavily about enabling people without a lot of resources to make advanced workflows that most people think are only possible for big companies with big dev teams.
We have tested the system with 8 professional users from different industries and we have seen non-technical users pick up the product and use it to transform their own workflows in under an hour. We have democratised many powerful advanced features for the common man enabling workflows that would never have been possible otherwise and saving as much as up 70% decrease in time to manage their workflow.
What I learned
While user testing the main issue was the we overestimated how much complexity we could include and still have a good usability score with users. After years of working in user centric design you’d think you’d have learned that but it reminded me to watch my biases, you often think things are a lot simpler than they are because you know them.
Furthermore, we also learned a lot about mental modelling, again as logical thinkers, our bias told us that everything thought about things in terms of logic but we worked with many different users who fundamentally did not think based on logic. We managed to bridge the basic gap with these users in our MVP but these users are just as important as logical thinkers and we need to do a lot more testing and enhancement to try and communicate how they can use the system in a language that they can understand and that can help them achieve their goals. No user will be left behind
In design we often talk about this concept of when some users hit a problem, rather than trying they will just quit. Developers are used to debugging problems, its second nature, but we need to enhance our service to emphasise forgiveness in design, we want to hold our users hands and help them fix problems and prevent them from quitting. We made great strides during the development but we want to enhance this through more iteration and user research.
From a technical perspective we learned a lot about managing dynamic flow based programming, the concept has been around for a long time but we tried to design the system to be as forgiving as possible so users can build confidence as they learn. Our debug nodes were a particularly useful iteration we made that really helped our users figure out problems without much guidance.
What's next for Plumber
We’ve mentioned a lot of our future plans throughout our question responses. We think based on what we learned from user research that data pipelines have never become very mainstream because of what we observed which was users really struggling with engineering concepts. Effectively developer tools being designed by developers who think like developers, with this project we have taken a user centric design approach to this problem and have started to work on better bringing users along with us to helping them reach their goals. The answer needs to be good design that helps users.
We also want to expand support and integrations for other data pipes easier, we dont want people to have to know anything about Restful services or messaging queues to be able to integrate with them so we want to create integration layers that will extrapolate that complexity out to a black box and we only surface what we need to users. Again all with a focus of speaking the language of non-technical users.
Finally the best design is no design so we’d like to begin implementation of an insight based machine learning algorithm that would suggest ways that people can use their current data pipelines to further enhance their workflows and use AI workflows (TensorFlow) in ways they had not considered. We will continue to work to bring this best in class data pipeline experience to Monday.com.
Built With
- hasura
- next.js
- node.js
- postgresql
- react

Log in or sign up for Devpost to join the conversation.