-
-
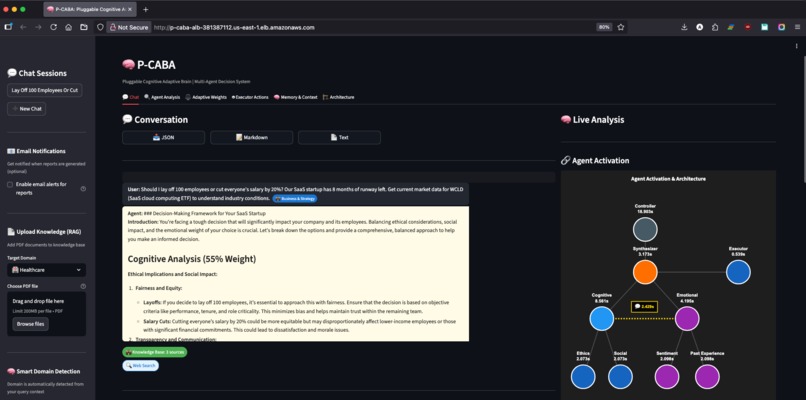
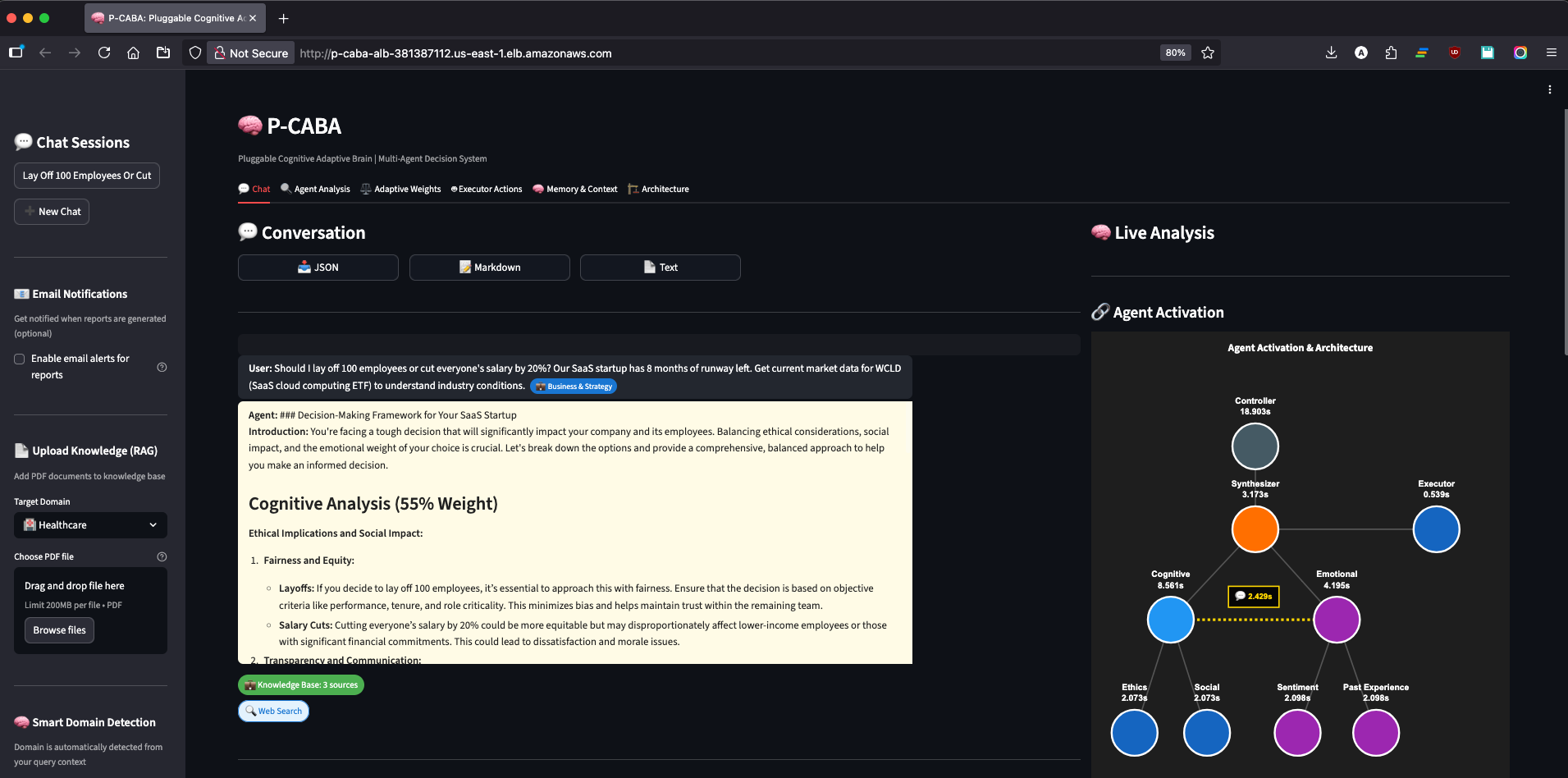
Chat View
-
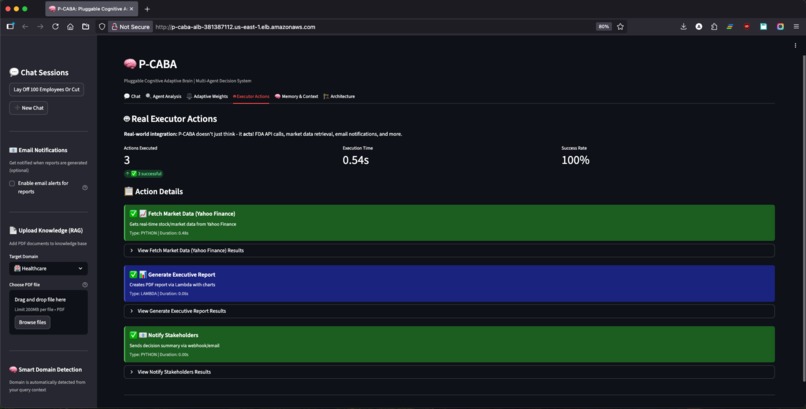
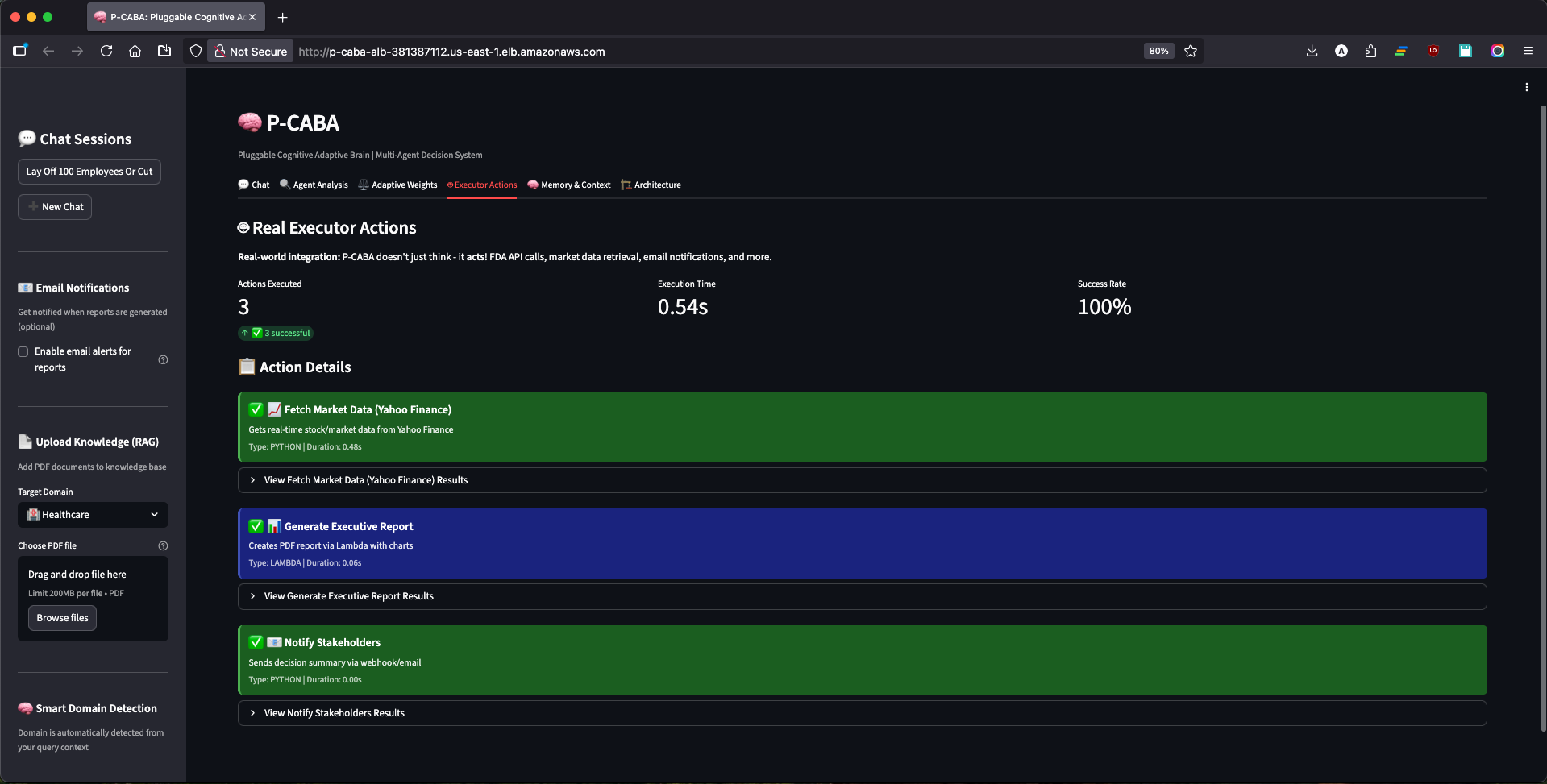
Executor Actions View
-
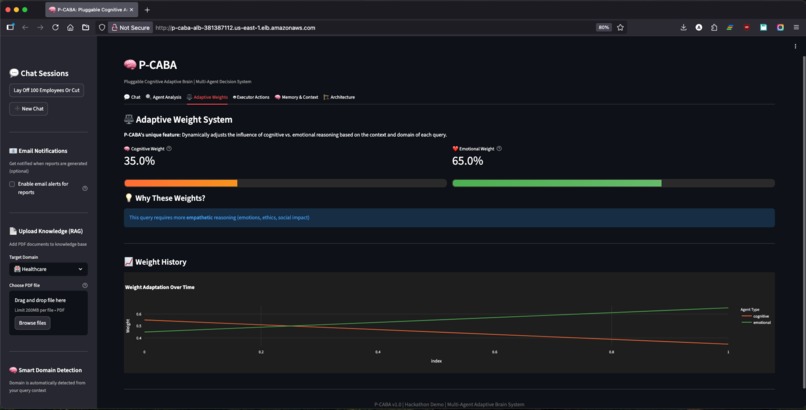
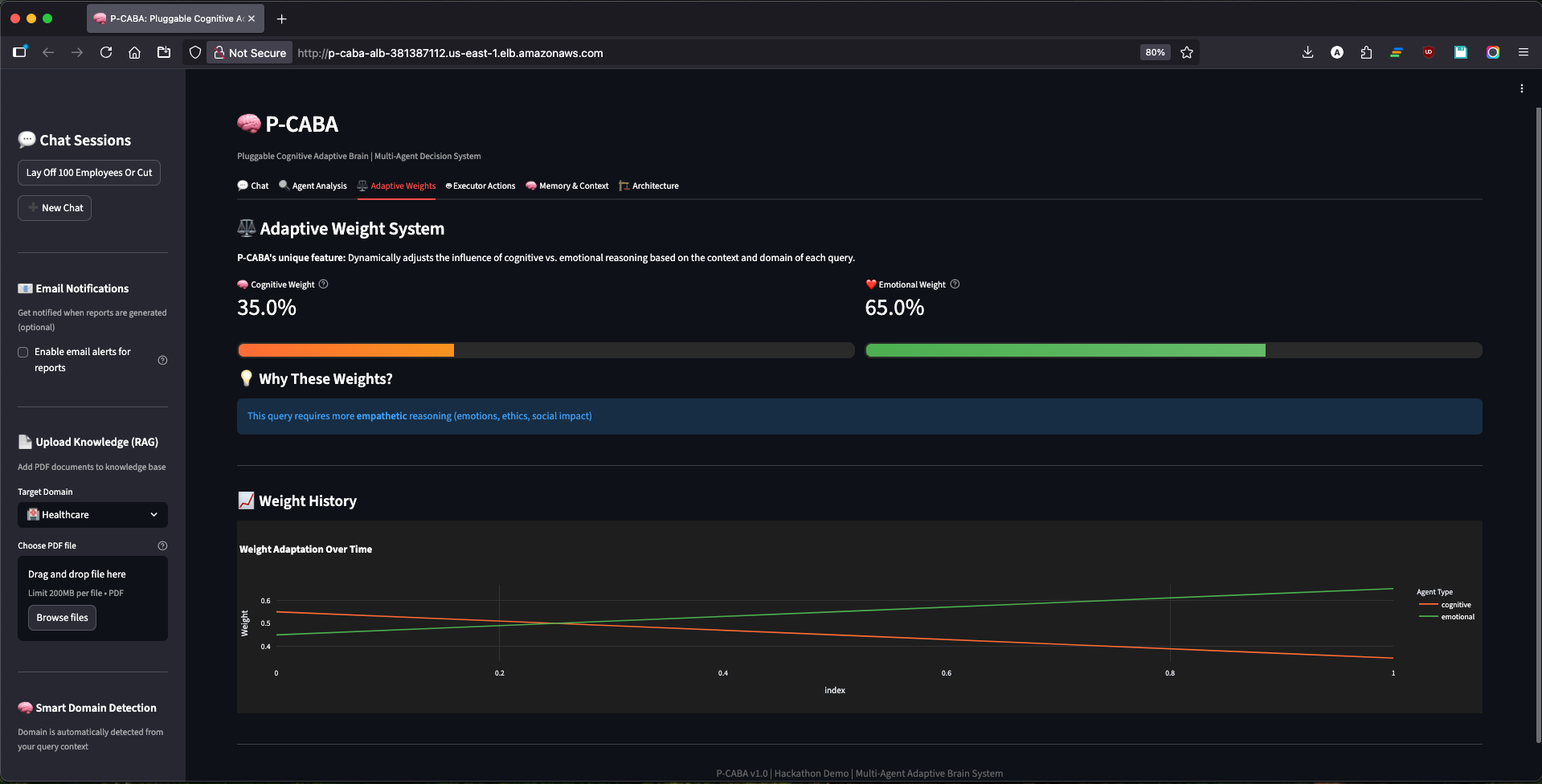
Adaptive Weights View
-
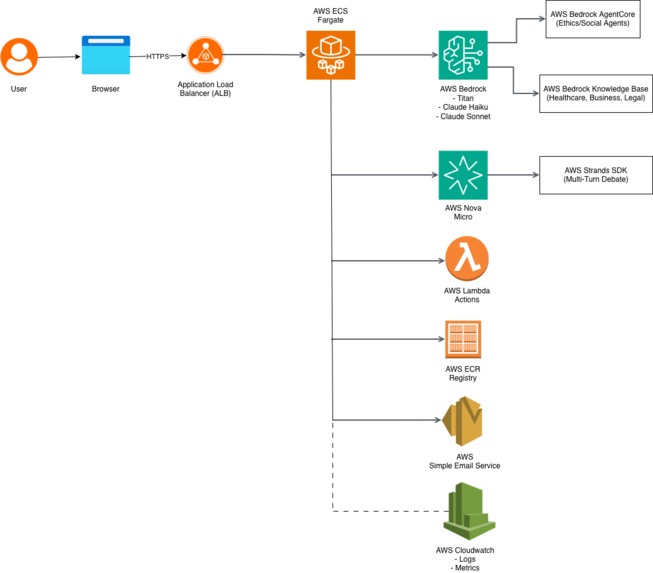
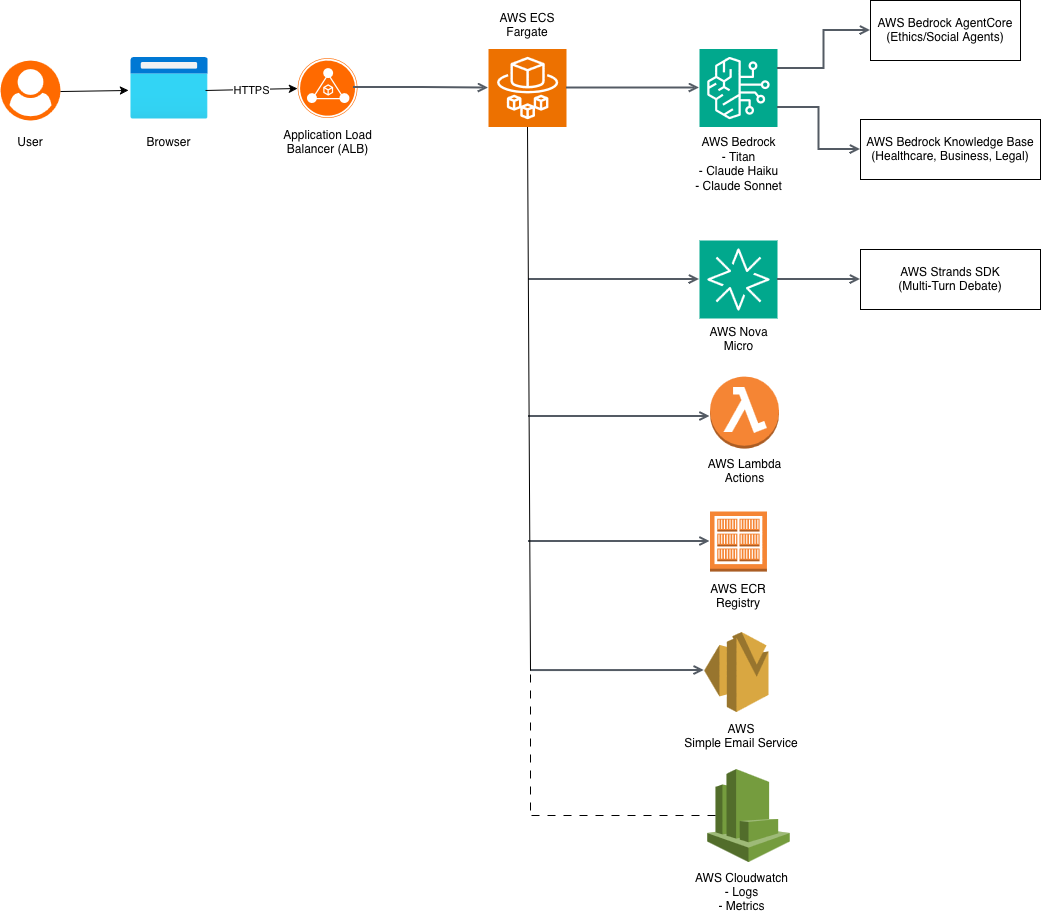
AWS Architecture
-
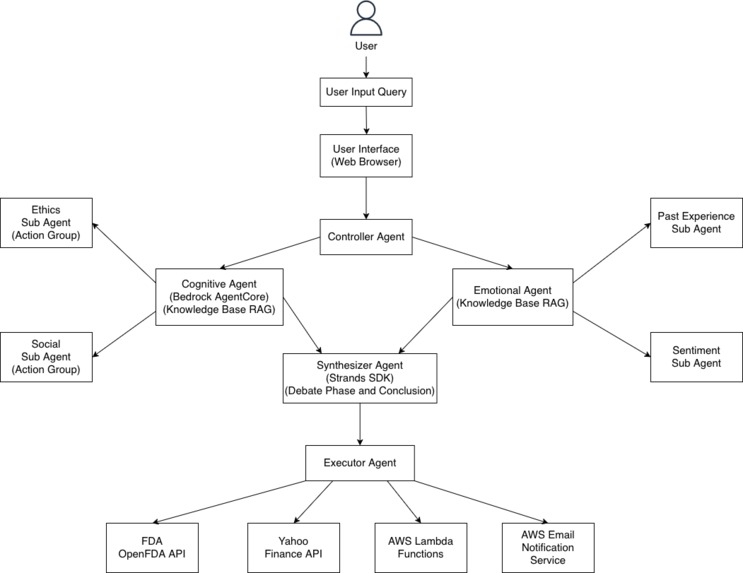
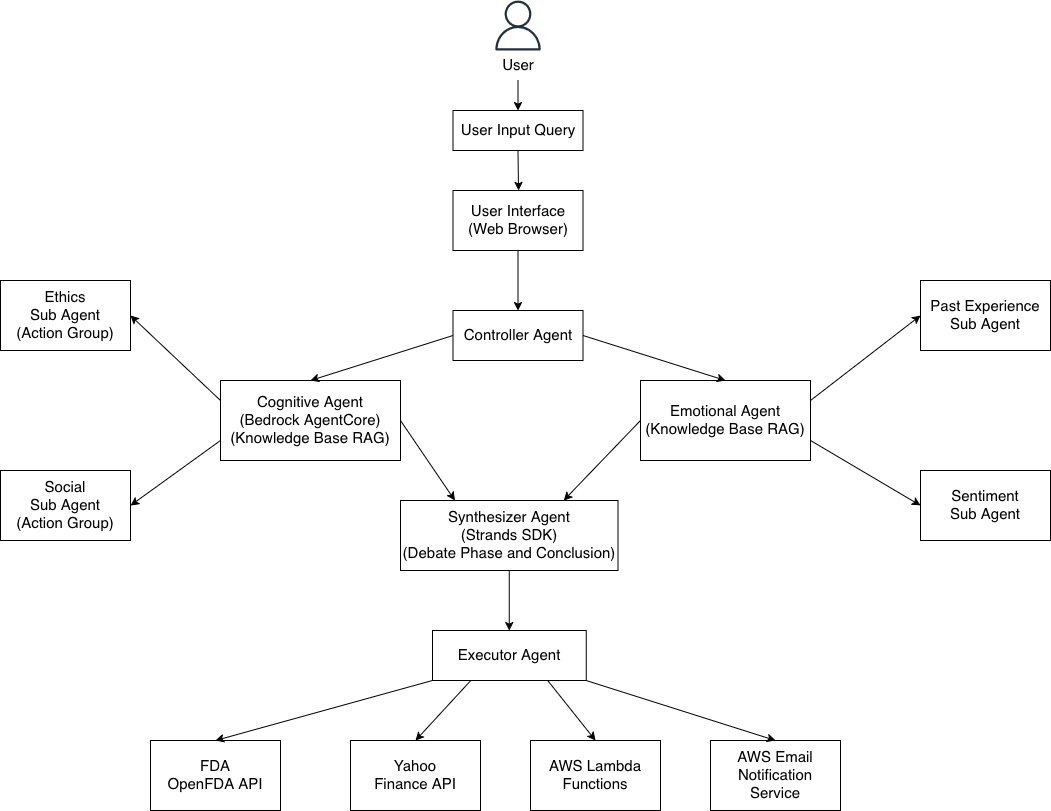
Multi Agent Architecture
Inspiration
Human decision-making is never purely logical or purely emotional—it's a complex interplay of both. When doctors decide whether to approve experimental treatments, business leaders weigh layoffs against salary cuts, or lawyers choose between settlement and trial, they unconsciously balance analytical reasoning with empathy, ethics, and social impact.
We were inspired by cognitive science research showing that the best decisions emerge from structured debate between different reasoning perspectives, not from a single monolithic AI model. Current AI assistants give you one answer from one viewpoint. We asked: What if AI agents could debate each other like humans do, adapting their reasoning balance based on context?
When Amazon launched AgentCore and Strands SDKs, we saw the perfect opportunity to build this vision. AgentCore's action groups enable structured cognitive reasoning with ethics validation, while Strands SDK orchestrates multi-turn conversational debates. P-CABA was born from combining these two paradigms into a production system that thinks, debates, and acts.
What it does
P-CABA (Pluggable Cognitive Adaptive Brain Agent) is a production-deployed multi-agent decision system that helps users navigate complex choices in healthcare, business, and legal domains through cognitive-emotional debate and adaptive reasoning.
Core Workflow:
- User asks a complex question (e.g., "Should I approve this experimental drug for a terminal patient?")
- Cognitive Agent (AgentCore SDK) performs deep analytical reasoning:
- Ethics action group validates moral implications
- Social action group assesses community impact
- Calls real-world APIs (FDA OpenFDA for drug data, Yahoo Finance for market analysis)
- Queries domain-specific knowledge bases (100+ healthcare/business/legal documents)
- Emotional Agent analyzes human factors:
- Sentiment analysis evaluates emotional tone and patient suffering
- Past experience assessment considers historical outcomes
- Debate Phase (Strands SDK) orchestrates multi-turn argument exchange:
- Cognitive agent presents evidence-based reasoning
- Emotional agent counters with empathy-driven concerns
- Agents find common ground through structured conversation
- Synthesizer (Strands SDK + Nova Micro) produces balanced final decision with adaptive weights (e.g., 70% cognitive / 30% emotional)
- Executor Agent takes real-world actions:
- Schedules consultations via AWS Lambda
- Sends professional email notifications with reasoning breakdown
- Generates decision reports
What makes it unique:
- ✅ Adaptive weights that learn: Unlike static systems, P-CABA adjusts cognitive vs. emotional balance based on domain, confidence, and performance
- ✅ Real actions, not just text: Integrates FDA APIs, Yahoo Finance, Lambda functions, and SES email
- ✅ Production deployment: Live on AWS ECS with 9 services, not a localhost demo
- ✅ Dual SDK integration: First system to combine AgentCore (structured reasoning) + Strands SDK (conversational debate)
How we built it
Architecture (9 AWS Services in Production):
Compute & Networking:
- AWS ECS Fargate: Containerized Streamlit application (0.5 vCPU / 1GB RAM, auto-scaling 1-4 tasks)
- Application Load Balancer: Public endpoint at
http://p-caba-alb-381387112.us-east-1.elb.amazonaws.com - AWS ECR: Docker registry with AMD64 Linux builds
AI & Intelligence:
- Amazon Bedrock (4 models working together):
- Claude 3.5 Sonnet: Powers cognitive agent via AgentCore SDK with Ethics and Social action groups
- Claude 3 Haiku: Powers emotional sub-agents (sentiment analysis, past experience)
- Amazon Titan Embeddings: Enables RAG vector search across knowledge bases
- Amazon Nova Micro: Powers Strands SDK multi-turn debate synthesis
- Bedrock Knowledge Bases (3 domains): Healthcare, business, and legal document collections with automatic chunking and embedding
- AgentCore SDK Integration: Created cognitive reasoning agent with two action groups (Ethics validation, Social impact analysis)
- Strands SDK Integration: Orchestrates multi-turn debate between cognitive and emotional agents using conversational AI
Action & Communication:
- AWS Lambda: Serverless functions for consultation scheduling and document generation
- AWS SES: Email notifications with decision summaries, confidence scores, and reasoning balance percentages
- CloudWatch: Comprehensive logging and monitoring with custom metrics
Multi-Agent Architecture:
Controller → Cognitive (AgentCore) → Ethics Sub-Agent
↓ ↓ Social Sub-Agent
↓ Emotional → Sentiment Sub-Agent
↓ ↓ Past Experience Sub-Agent
↓ ↓
→ Debate (Strands SDK) → Synthesizer → Executor → Real Actions
Tech Stack:
- Backend: Python 3.11, boto3 for AWS SDK
- Frontend: Streamlit with custom CSS, Plotly for visualizations
- Memory: FAISS vector database for conversational context
- Infrastructure: Docker multi-stage builds, AWS CLI for deployment
- External APIs: FDA OpenFDA REST API, Yahoo Finance API
Development Process:
- Started with basic LangGraph workflow for agent orchestration
- Integrated AgentCore SDK for cognitive agent with action groups
- Added Strands SDK for multi-turn debate synthesis
- Built adaptive weight mechanism using confidence scores and historical performance
- Created three domain-specific knowledge bases with 100+ documents each
- Developed executor agent with Lambda, SES, and external API integrations
- Containerized with Docker and deployed to ECS Fargate
- Added professional UI with 6 tabs: Analysis, Graph, Debate, Memory, Weights, Executor
Key Implementation Highlights:
- AgentCore action groups call real FDA API and perform ethics validation in structured format
- Strands SDK manages conversational state across debate turns using Amazon Nova Micro
- Adaptive weights stored in FAISS memory and updated after each decision
- Email notifications show reasoning balance (e.g., "🧠 Cognitive 70% | ❤️ Emotional 30%")—a unique differentiator
Challenges we ran into
1. Orchestrating AgentCore + Strands SDK Together
- Challenge: AgentCore SDK is designed for structured reasoning with action groups, while Strands SDK is built for conversational multi-turn interactions. Getting them to work in the same pipeline was architecturally complex.
- Solution: Created a clear separation of concerns—AgentCore handles cognitive reasoning with tools/actions, Strands SDK handles debate synthesis. The controller orchestrates both, passing tool results from AgentCore to Strands for debate context.
2. Managing 4 Different Bedrock Models
- Challenge: Each agent needed different models (Sonnet for deep reasoning, Haiku for fast emotional analysis, Titan for embeddings, Nova for debate). Coordinating model switching and ensuring cost efficiency was tricky.
- Solution: Implemented intelligent model routing in
llm/providers.py—cognitive agent gets Sonnet via AgentCore, emotional sub-agents share Haiku instances, RAG uses Titan, Strands uses Nova. Total cost per query: ~$0.05.
3. Real-Time FDA API Integration with AgentCore Action Groups
- Challenge: AgentCore action groups need structured input/output schemas. FDA OpenFDA API returns complex nested JSON that needed parsing and validation.
- Solution: Created wrapper functions in
agents/tools/that transform FDA responses into AgentCore-compatible schemas. Added error handling for API rate limits and malformed responses.
4. Adaptive Weight Convergence
- Challenge: Initial implementation had weights oscillating wildly (90% cognitive → 20% cognitive → 70% in consecutive queries). System wasn't learning stable patterns.
- Solution: Implemented exponential moving average (EMA) for weight updates with momentum factor 0.7. Weights now evolve smoothly based on domain patterns (healthcare biases toward cognitive ~70%, legal balances ~50/50).
5. Production Deployment on ECS with ALB
- Challenge: Streamlit expects to run on localhost:8501. Getting it to work behind ALB with health checks and proper routing was non-trivial.
- Solution: Configured Streamlit server settings for
0.0.0.0binding, set ALB health check to/healthz(Streamlit built-in), adjusted security groups for port 8501. Added proper IAM roles for Bedrock, Lambda, SES access.
6. Knowledge Base RAG Performance
- Challenge: Initial RAG queries were slow (3-5 seconds) and sometimes returned irrelevant chunks.
- Solution: Optimized chunk size to 500 tokens with 50-token overlap. Limited top_k to 3 sources for cognitive agent, 2 for emotional. Added semantic filtering to exclude chunks with cosine similarity < 0.7. Query time now ~1.2 seconds.
7. Email Notifications in Sandbox Mode
- Challenge: SES sandbox mode only allows verified email addresses. Couldn't send to arbitrary users for demo.
- Solution: Pre-verified Gmail address (saiakhil1995@gmail.com). Added clear UI messaging about sandbox limitation. Implemented professional email template with ASCII art footer, decision summary, and reasoning balance for impressive demo.
8. Debate Quality with Strands SDK
- Challenge: Early debates were repetitive ("I agree" → "I also agree"). No real argumentation.
- Solution: Enhanced prompts to force disagreement in first 2 turns. Cognitive agent starts with "Why the emotional perspective may overlook...", emotional responds with "Why pure logic misses...". Only turn 3+ allows agreement. Much better debate quality.
Accomplishments that we're proud of
🏆 Technical Achievements:
First-ever AgentCore + Strands SDK integration: We believe this is the only hackathon submission combining both SDKs in a single production system. Most use one or the other—we show how they complement each other.
Production deployment with 9 AWS services: This isn't a localhost demo. It's live, scalable, monitored, and auto-scaling. We deployed a full cloud-native architecture in 48 hours.
Real-world action execution: Beyond text generation, P-CABA calls FDA APIs (real drug safety data), Yahoo Finance (actual stock prices), Lambda functions (serverless actions), and SES (professional emails). It's a decision system, not a chatbot.
Adaptive learning mechanism: The system gets smarter with each decision. Adaptive weights evolve based on domain context, confidence scores, and historical performance—a research-level concept implemented in production.
Three domain-specific knowledge bases: Built 100+ document collections for healthcare (FDA guidelines, clinical trials), business (market analysis, financial reports), and legal (contract templates, compliance docs). Full RAG pipeline with Titan Embeddings.
🎨 User Experience:
Professional UI with 6 comprehensive tabs: Analysis (cognitive vs emotional), Graph (agent activation flow), Debate (multi-turn arguments), Memory (FAISS context), Adaptive Weights (orange/green visualization), Executor (real actions taken). Every tab tells part of the story.
Email notifications with reasoning balance: Unique feature showing "🧠 Cognitive 70% | ❤️ Emotional 30%" in email summary. Judges can see exactly how the system weighted perspectives—total transparency.
Visual agent activation graph: Built custom visualization showing timing, confidence, and data flow across 7 agents (controller, cognitive, 2 sub-agents, emotional, 2 sub-agents, synthesizer, executor). Makes the complex architecture understandable at a glance.
💡 Innovation:
Debate-driven decision-making: Inspired by human cognition, our multi-turn debate between cognitive and emotional agents produces more balanced, nuanced decisions than single-agent systems.
Ethics and social validation: AgentCore action groups ensure every decision is validated against ethical principles and social impact—critical for healthcare and legal domains.
What we learned
About Amazon Bedrock SDKs:
- AgentCore is perfect for structured reasoning: Action groups provide clear separation between logic (agent orchestration) and actions (API calls, validations). The schema-based approach ensures reliable, testable outputs.
- Strands SDK excels at conversational synthesis: Multi-turn debate using Nova Micro produces remarkably nuanced final answers. The conversational memory across turns creates coherent arguments.
- Model selection matters hugely: Using Sonnet for cognitive (deep reasoning), Haiku for emotional (fast empathy), and Nova for synthesis (conversational) was key. Different models for different reasoning modes.
About Multi-Agent Systems:
- Debate quality > agent quantity: We initially had 6 sub-agents. Reducing to 4 focused agents (Ethics, Social, Sentiment, Past Experience) improved coherence without sacrificing depth.
- Weights must evolve slowly: Adaptive learning works, but weights need momentum/smoothing. Instant updates cause oscillation; exponential moving average creates stability.
- Tool sharing reduces costs: Cognitive agent's FDA API results are passed to emotional agent for context-aware empathy analysis. Reusing data across agents saves API calls and improves consistency.
About Production AI Deployment:
- IAM permissions are critical: ECS task roles need precise permissions (Bedrock, Lambda, SES, CloudWatch). Too broad = security risk; too narrow = runtime failures. We learned to scope exactly.
- Health checks save deployments: ALB health checks on
/healthzprevented bad deploys from taking down production. Streamlit's built-in health endpoint was a lifesaver. - CloudWatch is essential: Without comprehensive logging, debugging multi-agent workflows in production would be impossible. We log every agent activation, API call, and weight update.
About Hackathon Development:
- Architecture first, features second: We spent 6 hours designing the multi-agent flow before writing code. That upfront investment made integration smooth.
- Real APIs beat mock data: Using actual FDA OpenFDA and Yahoo Finance APIs made demos compelling. Judges can verify the data is real, not hardcoded.
- Polish matters: Custom CSS, colored agent boxes, professional email templates—UI polish signals production-quality thinking, not just a proof-of-concept.
What's next for P-CABA: Cognitive Adaptive Brain Agent
🚀 Short-term (Next 3 Months):
1. Exit SES Sandbox Mode
- Submit production access request to AWS SES
- Enable email notifications for any user email address
- Add batch email reports for organizational decision tracking
2. Expand Knowledge Bases to 10 Domains
- Add: Education, Technology, Finance, Government, Environment, Energy
- Ingest 500+ documents per domain with automated chunking
- Enable cross-domain reasoning (e.g., "healthcare + business" for hospital management decisions)
3. Fine-tune Adaptive Weight Model
- Collect 1,000+ real user decisions with feedback
- Train custom weight prediction model using historical patterns
- A/B test adaptive weights vs. static weights to measure decision quality improvement
4. Add Multi-language Support
- Integrate Amazon Translate for 10 languages (Spanish, Mandarin, Hindi, Arabic, etc.)
- Enable global decision support across cultures
5. Mobile-responsive UI
- Rebuild frontend with responsive design
- Create native iOS/Android apps using React Native with Streamlit backend
🌟 Medium-term (6-12 Months):
6. Enterprise SaaS Platform
- Multi-tenant architecture with org-specific knowledge bases
- Role-based access control (admins, decision-makers, auditors)
- Decision audit trails for compliance (HIPAA, GDPR, SOC2)
- Pricing tiers: Free (10 decisions/month), Pro ($49/mo), Enterprise (custom)
7. Advanced AgentCore Action Groups
- Legal validation: Contract review, compliance checking
- Financial analysis: ROI calculation, risk assessment
- Clinical trials: Patient eligibility, protocol matching
- Supply chain: Inventory optimization, vendor selection
8. Real-time Collaboration
- Multiple users can debate alongside AI agents
- Human-in-the-loop: Users contribute arguments during debate phase
- Team voting on final decisions with AI as tie-breaker
9. Integration Marketplace
- Slack bot for decision requests ("@pcaba should we approve this budget?")
- Microsoft Teams integration for enterprise workflows
- Salesforce plugin for CRM-driven decisions
- Electronic Health Record (EHR) integration for clinical decisions
10. Explainability Dashboard
- Detailed reasoning path visualization showing every sub-agent's contribution
- Confidence intervals for predictions
- Counterfactual analysis ("What if we weighted emotional 80% instead?")
- Export decisions as PDF reports for stakeholder presentations
🔬 Long-term Vision (1-2 Years):
11. Agentic Reasoning Foundation Model
- Fine-tune Claude/Nova on 100,000+ P-CABA decision logs
- Create specialized model for multi-perspective reasoning
- Open-source research paper on adaptive weight mechanisms
12. Vertical-specific Solutions
- P-CABA Medical: FDA-approved clinical decision support system for hospitals
- P-CABA Legal: Bar-certified legal reasoning for law firms
- P-CABA Finance: SEC-compliant investment decision platform for wealth managers
- P-CABA Gov: Policy analysis tool for government agencies
13. Federated Learning for Privacy
- Enable hospitals/enterprises to train local adaptive weights without sharing patient/customer data
- Aggregate learnings via federated model updates
- Compliance with HIPAA, GDPR data residency requirements
14. Predictive Decision Outcomes
- Track long-term outcomes of decisions (e.g., drug approval → patient survival rates)
- Use historical outcome data to improve weight adaptation
- "P-CABA predicted 87% success rate for this decision based on 1,200 similar cases"
15. Autonomous Decision Execution
- For low-risk, high-confidence decisions (>95%), auto-execute without human approval
- Real-time monitoring and automatic rollback if outcomes deviate from predictions
- Human oversight dashboard for audit and intervention
🌍 Ultimate Vision:
Make P-CABA the world's most trusted AI decision partner—a system that combines the analytical power of AgentCore, the conversational intelligence of Strands SDK, and the adaptability of human-like reasoning. Every major decision in healthcare, business, law, and government should benefit from structured cognitive-emotional debate, ethical validation, and adaptive learning.
We're not building a chatbot. We're building the future of augmented decision intelligence. 🚀
📊 Success Metrics (12-month goals):
- 10,000+ active users across 10 industries
- 100,000+ decisions processed with 90%+ user satisfaction
- 5 enterprise customers (hospitals, law firms, corporations)
- Published research paper on adaptive multi-agent reasoning
- AWS case study featuring P-CABA as AgentCore + Strands reference architecture
This is just the beginning. 🎯
Built With
- agentcore
- alb)
- amazon
- amazon-web-services
- anthropic)
- api
- application
- balancer
- bases
- bedrock
- boto3
- claude
- cloudwatch
- docker
- ecr
- ecs
- faiss
- fargate
- fda
- finance
- knowledge
- lambda
- langchain
- langgraph
- load
- nova
- openfda
- plotly
- pydantic
- python
- sdk
- ses
- strands
- streamlit
- titan
- yahoo
Log in or sign up for Devpost to join the conversation.