-
-
Mock-up in Figma
-

PlotArmor Logo
-
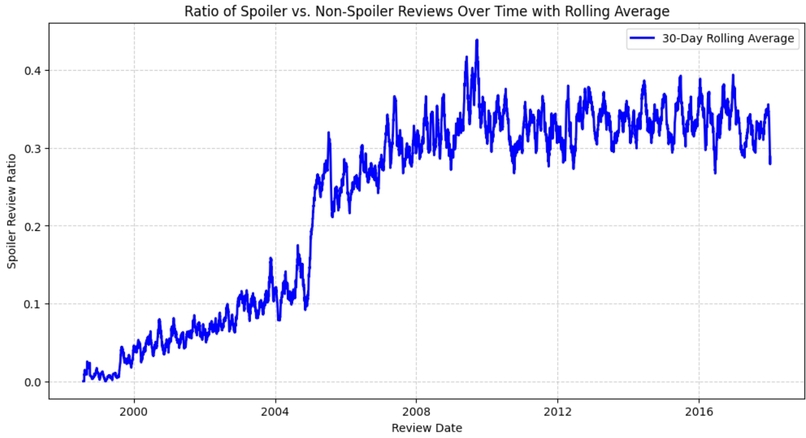
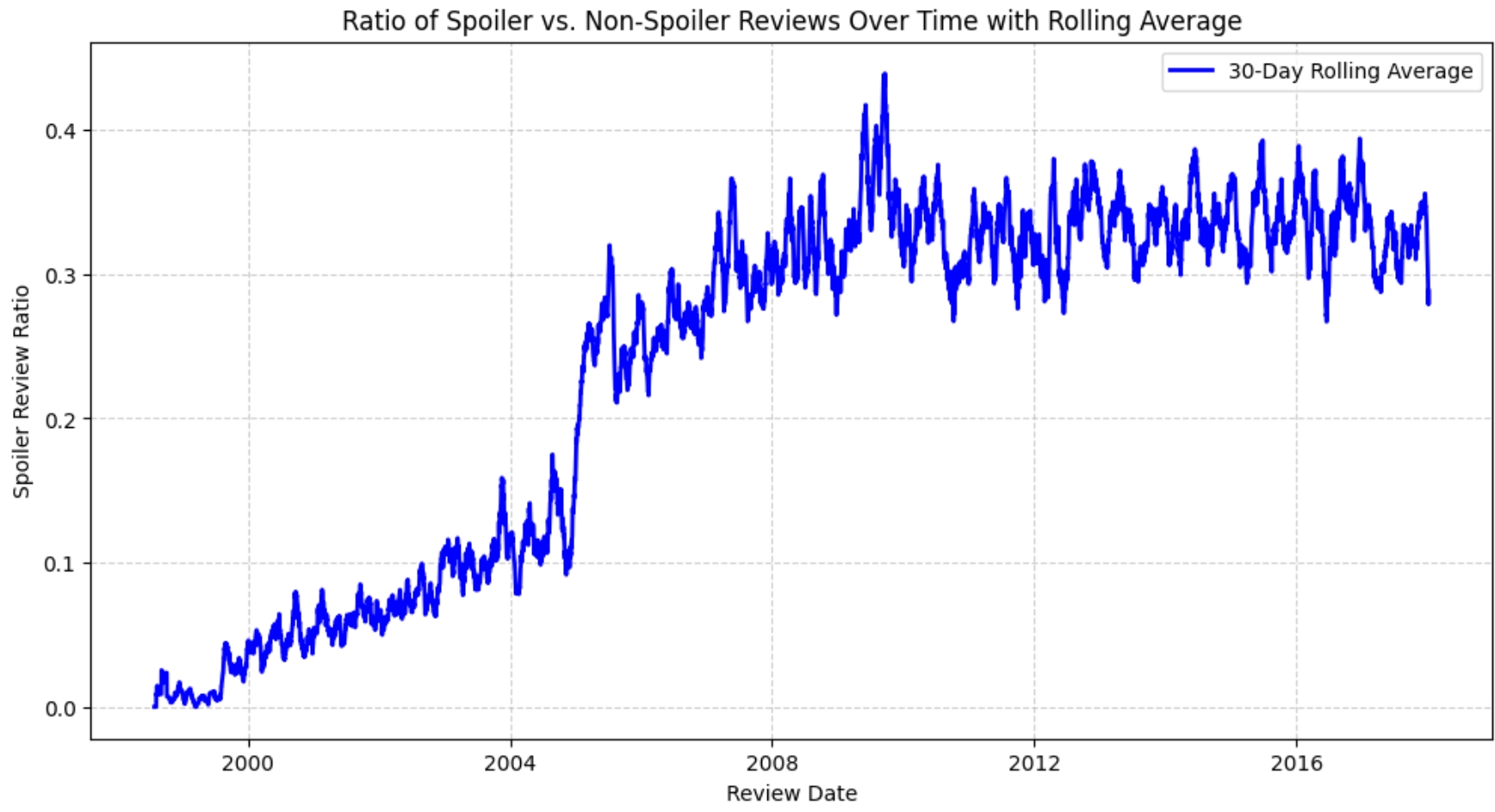
Ratio of Spoilers to Non-spoilers over time
-
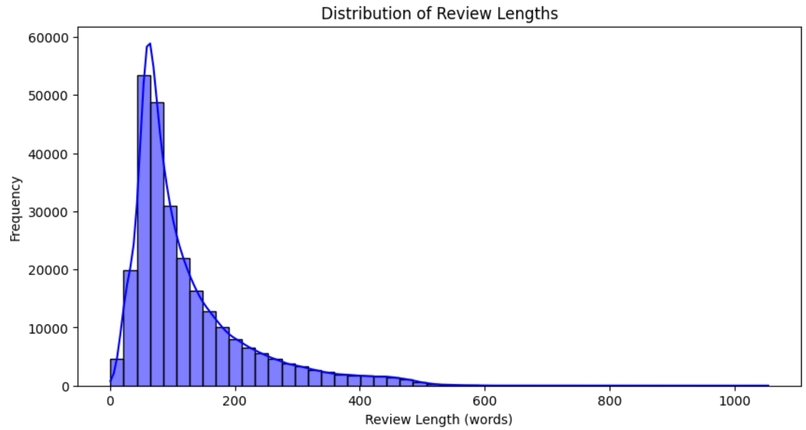
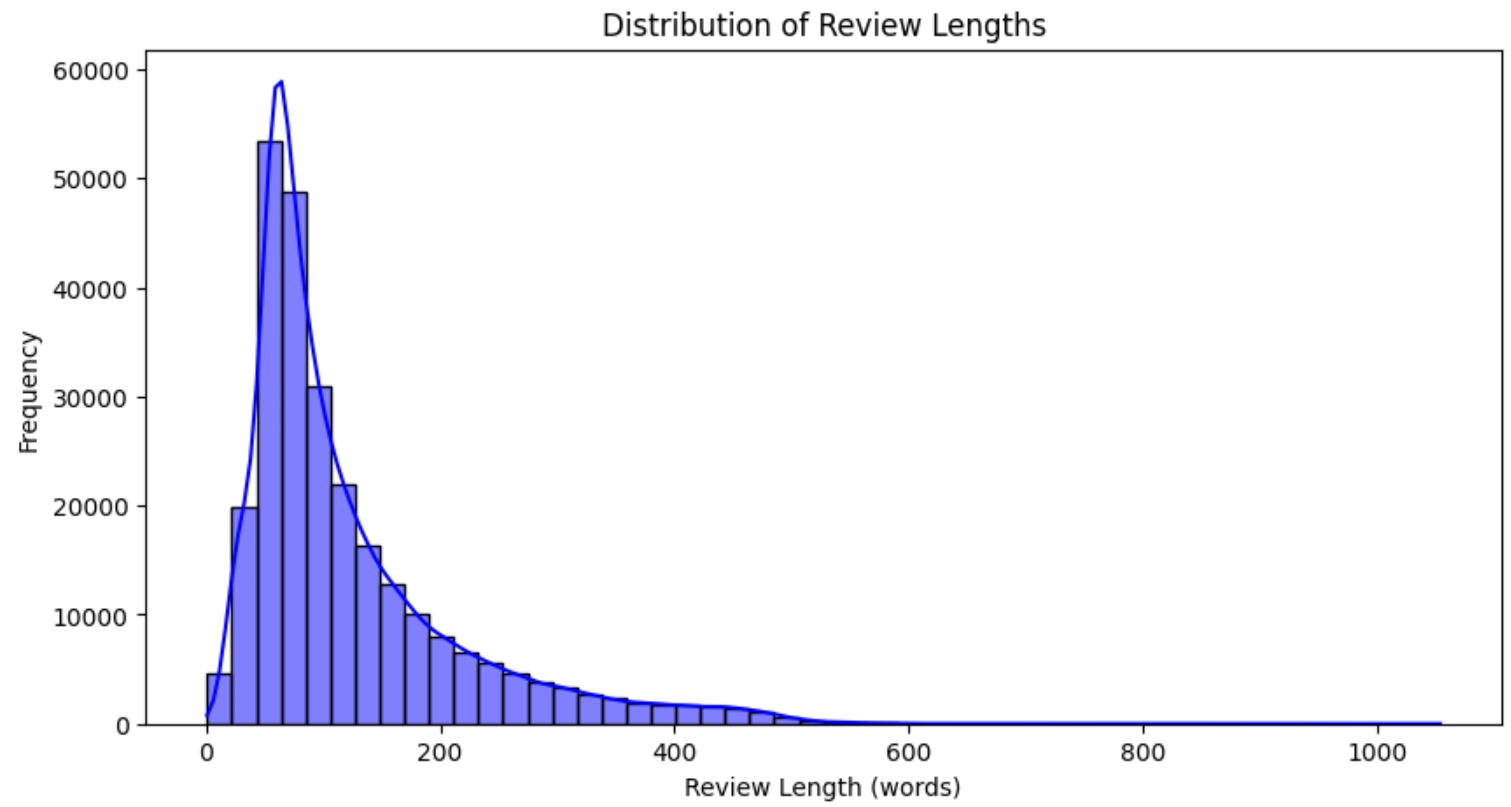
Distribution of Review Lengths
-
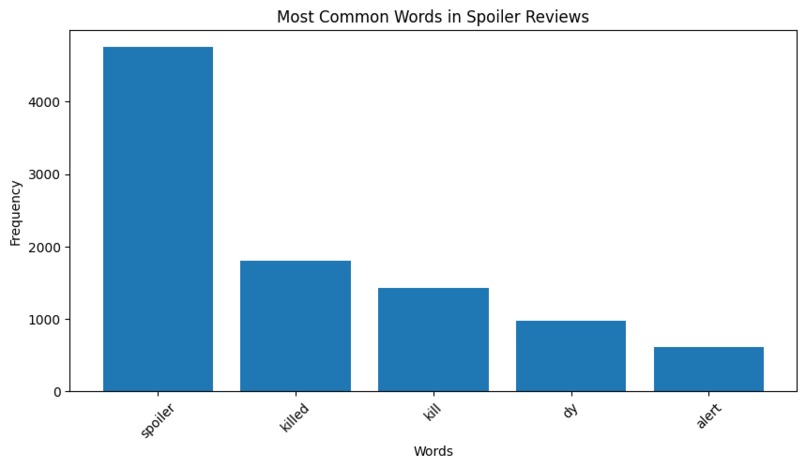
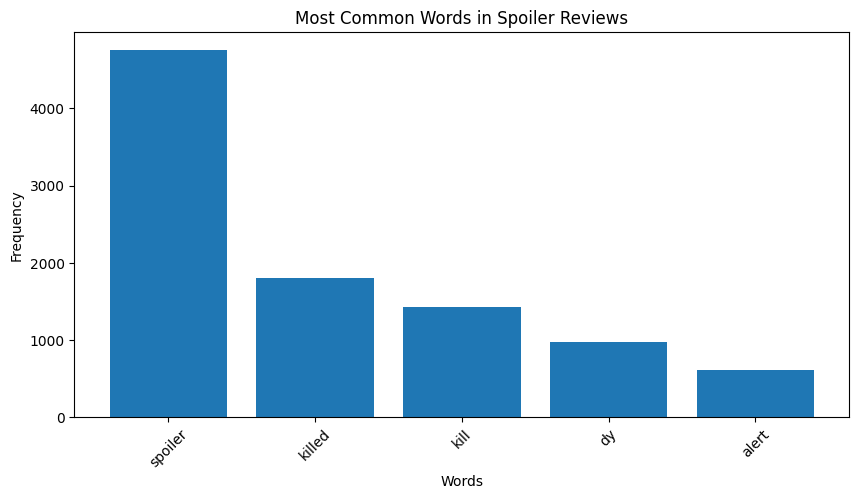
Common Words in Spoilers
-
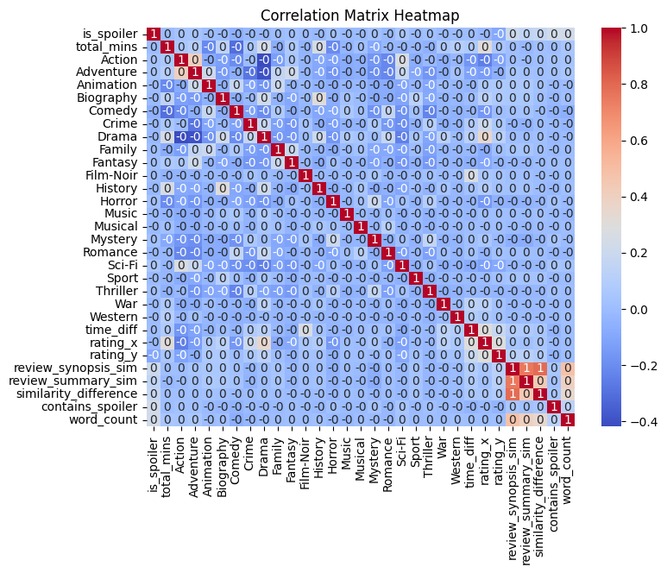
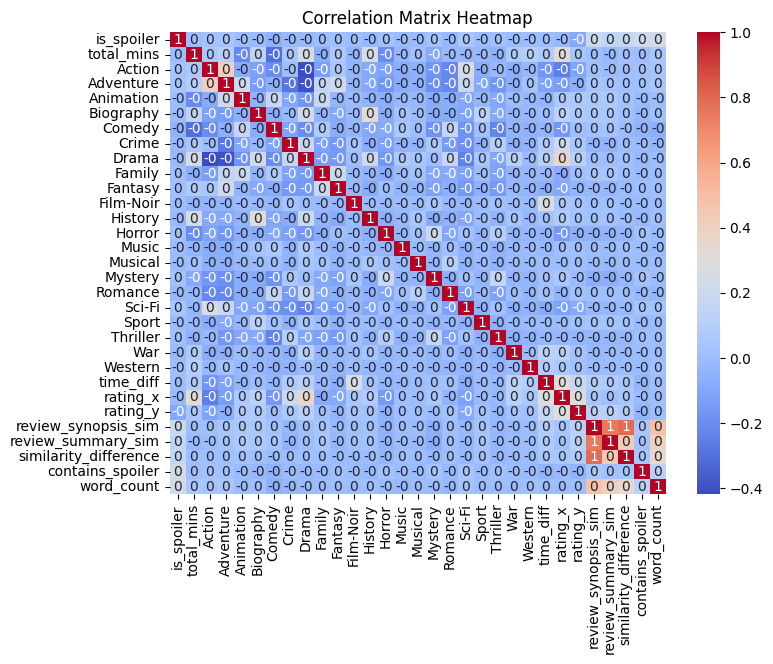
Heatmap

Love movies, hate spoilers.
Let’s face it. Many of us decide what movies to watch by reading the reviews. However, far too often movie reviews contain unwanted spoilers that ruin the viewing experience. Therefore, we asked: Is it possible to determine with reasonable certainty, before reading a review, whether it contains spoilers? Our goal is to protect ourselves and others from today’s spoiler-riddled internet landscape and preserve the enjoyment of countless first-time watchers.
Enter PlotArmor
PlotArmor is a Google Chrome extension that identifies predicted spoilers on a webpage and blurs the offending text to guard the user against unwanted spoilers.
How we built the Model
We began by gathering our dataset. From Kaggle, we obtained datasets with features like plot synopsis, movie summary, user reviews, and many other features scraped from IMDB that would allow us to predict the target value: is_spoiler.
Data Wrangling
To process the data, we first cleaned it by removing rows containing null or NaN values. We then applied Multi-Hot Encoding using a Multi-Label Binarizer to categorize the “genre” data and standardized all time/date values to maintain a uniform format. After these preprocessing steps, we merged the movie_details and review_details datasets to create a consolidated data frame for analysis.
To better understand the data, we parameterized key properties of the textual data, converted all text to lowercase, and removed punctuation for consistency. We then vectorized the processed text using both a Bag-of-Words model and TFIDF model in Python and calculated cosine similarity to quantify the relationships between different pieces of textual data.
To determine which variables were relevant in predicting spoiler content, we created a correlation matrix. Attached is a heatmap of the same correlation matrix.
Findings
The problem of predicting whether a review contains a spoiler is more complex than we initially thought it would be.
We found that word count is one of the most strongly correlated to spoiler status. Further, negative movie reviews are more likely to contain spoilers. Another consideration we had was that reviews with spoilers that didn't exactly match the wording in the movie synopsis would be hard to predict accurately. Additionally, if the synopsis is not comprehensive enough, there may not be enough data to predict accurately for a given review. However, by far the most indicative sign of a review contain spoilers was the review containing the word "spoiler." We found that of every review that contained the word "spoiler", over 72% were spoilers, likely because reviewers are likely careful to include "Spoiler Alerts" when their review discusses key plot points.
With these features and their correlations, we trained, tested, and tuned our predictive model to achieve a balance in detecting both spoiler and non-spoiler reviews at high degrees of accuracy. Ultimately, we achieved a precision score of 86% when a review does not contain spoilers and a recall score of 71% when a review does contain spoilers. This means that when the model predicts a non-spoiler it is correct 86% of the time and when a review contains a spoiler, our model catches it 71% of the time. Overall, we predict spoilers and non-spoilers with an accuracy of 69%.
Making the Chrome Extension
To create the most value from our model, we opted to integrate it with a Google Chrome Extension called PlotArmor, designed to blur out reviews containing spoilers on IMDB. We designed a mock-up in Figma and used Preact to create the front end. On the page load of a movie's review page (a movie contained within our dataset), the extension queries the HTML on the page to gather review data and injects JavaScript to blur the appropriate reviews. If users would still like to view the review, they can click on the headline to view the review unblurred. They can also toggle off/on the extension and view a count of the spoilers they've blocked in the extension pop-up.
Challenges we ran into
One of the major challenges we faced was the limited computing power. With such a large dataset (originally 500k+ reviews), we had to be selective with what we could compute within the time and resource constraints. In particular, we chose to discard half of our dataset due to significantly large processing times. This allowed us to develop and train our model within the allotted time frame.
Another challenge we faced was our low initial accuracy scores. Our first iteration of the model was not very effective at catching reviews containing spoilers due to slight differences between the words in the review and synopsis texts. We realized that this issue might be ameliorated by lemmatizing our data, which converts every word into its un-conjugated form. This allowed our model to better identify the similarities between the reviews and the movie synopsis. We also lowered the threshold at which our model deems a review a spoiler, making our model more sensitive to potential spoilers while maintaining a good overall accuracy.
Accomplishments that we're proud of
Over 70% of spoilers are caught by our current model - a significant improvement from only 20% with the first iteration of our model. Additionally, we successfully created a web extension with the potential for real world application.
What's next for PlotArmor
The next steps would include further developing our model using more complex semantic analysis rather than BOW/Tfidf analysis. Model will also be dynamically updated by user feedback.
Built With
- colab
- kaggle
- machine-learning
- natural-language-processing
- preact
- python

Log in or sign up for Devpost to join the conversation.