-
-

End of Journey has a mini game from your own stats
-
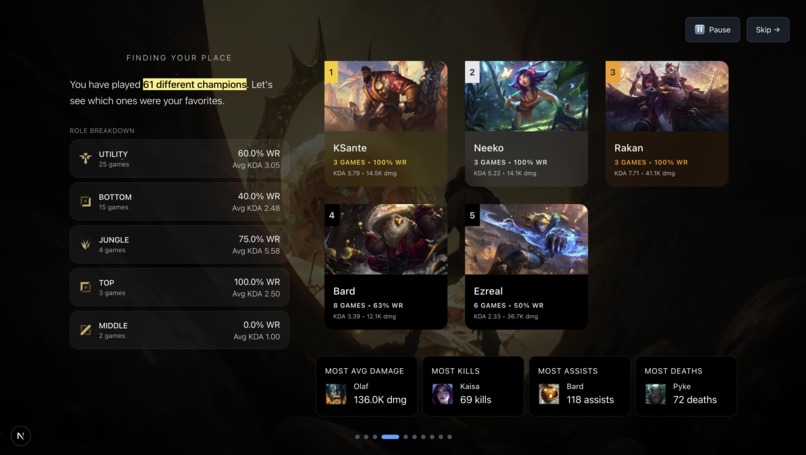
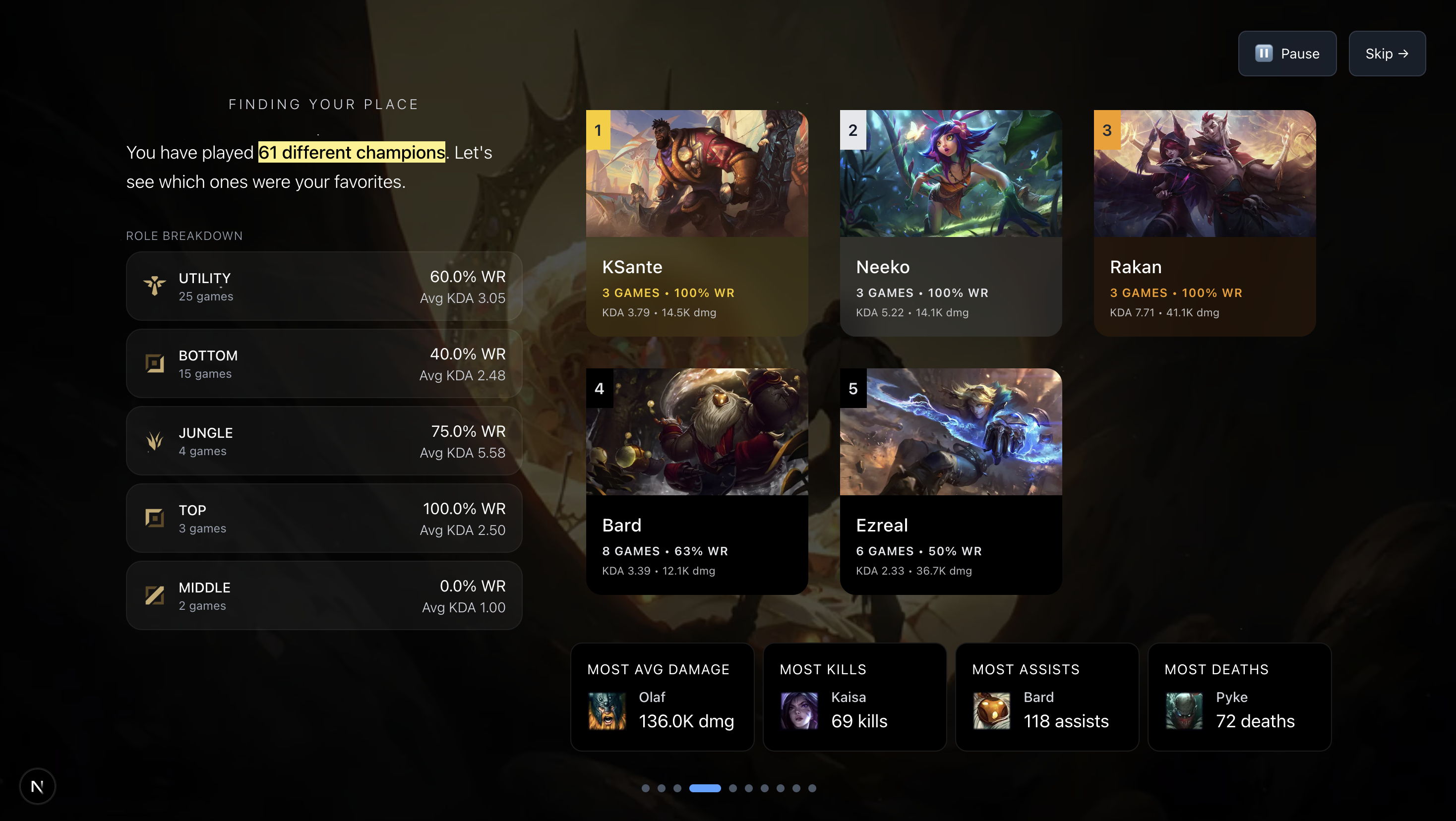
Champion and role breakdown.
-
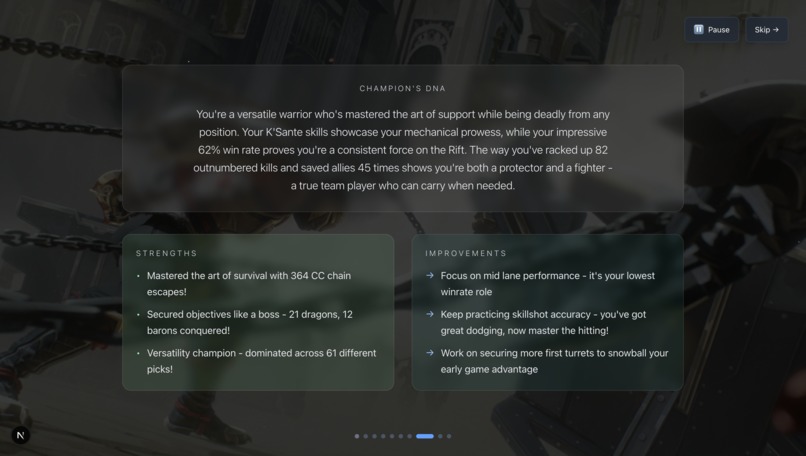
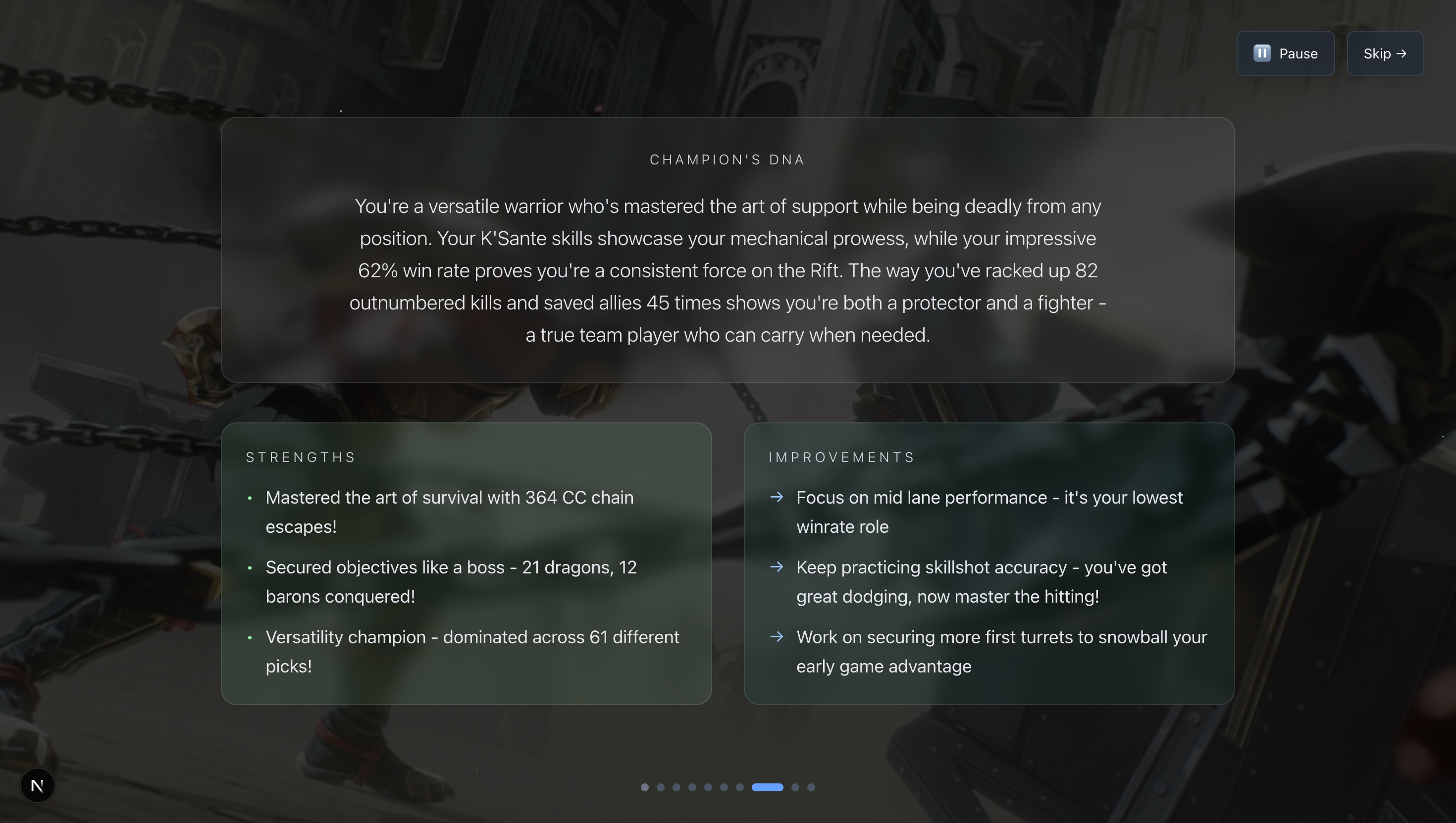
AI insights on play style, what you are doing good, and how you can improve.
-

Journey walks through your last 100 league games and provides mix of raw metrics and complex insights.
-

Story generator that uses the events of your league of legends game to write a heroic story
-
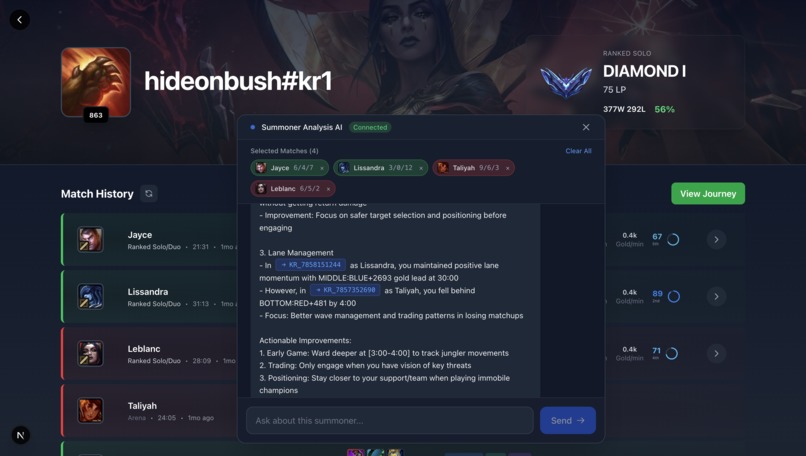
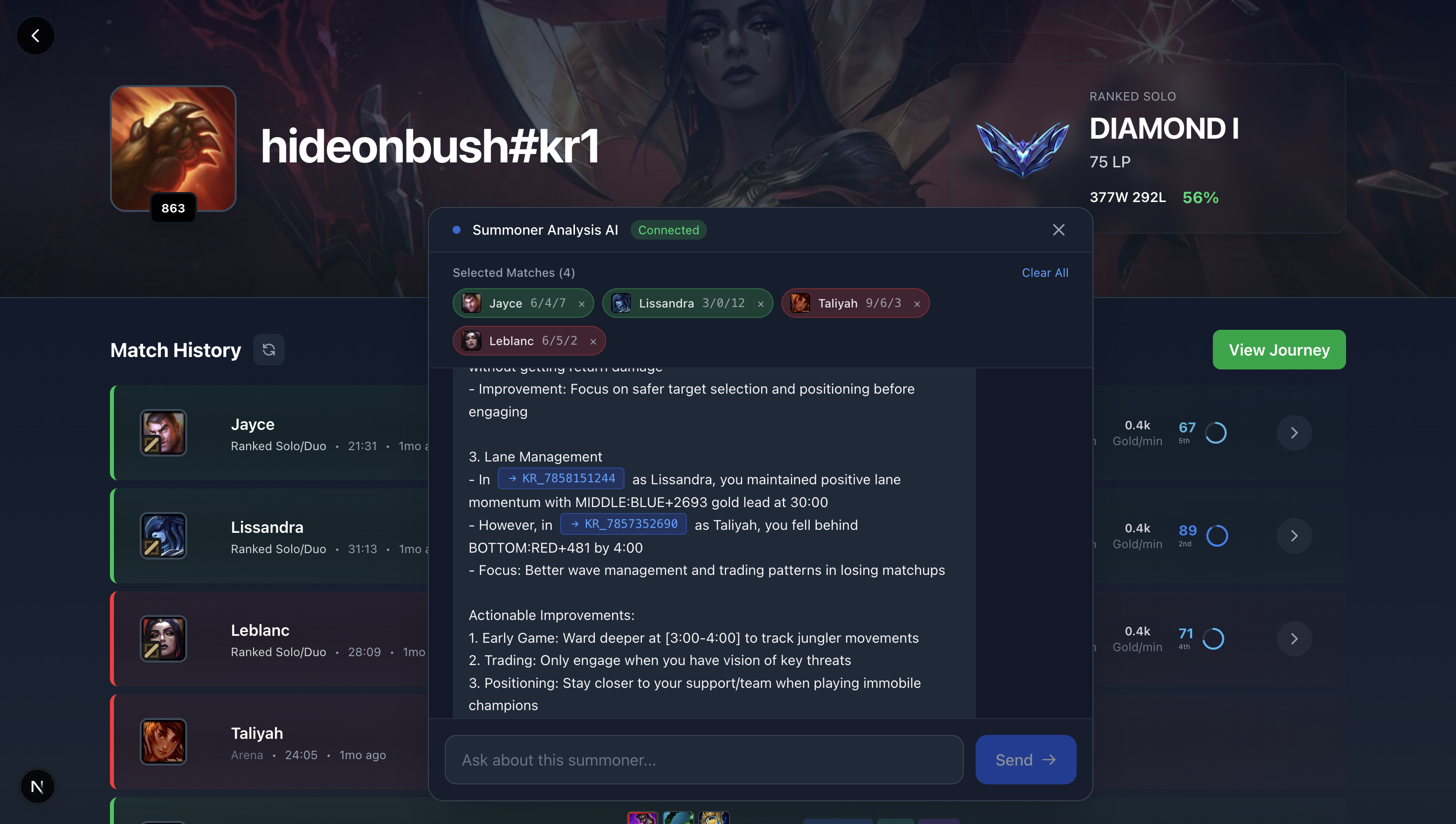
Homepage with chatbot that lets you use your matches as context with simple drag and drop
-
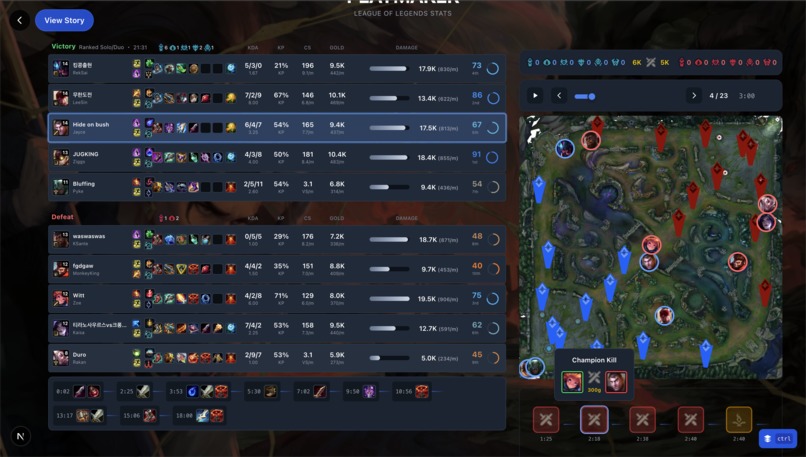
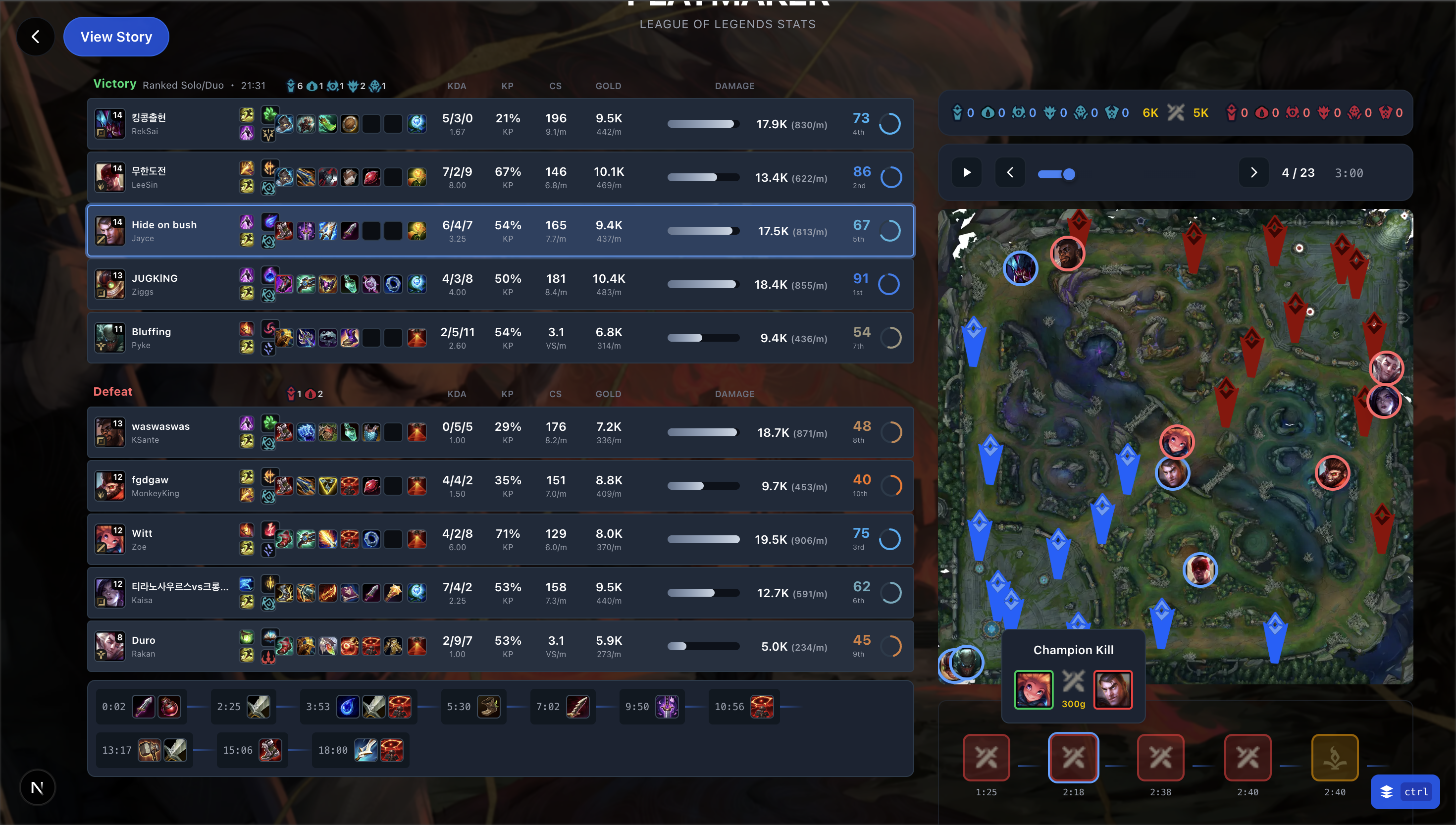
Match review page with minimap that replays the entire game.



Inspiration
There are many sites like OP.GG and DPM.GG that lets gamers view numerous stats, but actual insights on how to get better is missing. It's easy to look and be happy at KDA or sad over 20 deaths, but receiving actionable insights and answers is the key to improve, and a much harder task. We set out to do just that.
Theres always more to the story than the numbers. Avid League players have been frustrated looking at things like their OPGG score, feeling as though it doesn't tell the full story of the game. We set ought to be able to truly look at the full story of the game, and beyond that, give advice and answer questions about that game. All to answer the age old question: was everything truly your jungler's fault?
What it does
Playmaker is a League of Legends match analysis tool utilizing AI. It allows users to use their games as context, and talk back and forth with a chatbot over the immense data collected from the Riot Timeline Api. Based on the selected games, it answers questions you have, from what you could to better and where the game went wrong to contrasting your approaches in different games.
In addition, it comes with a detailed review of the game with an events timeline and map recreation. Users can look through minute-by-minute the state of the game, hovering over champions to see their items, health, and held at that point to truly understand the state of the game. An events timeline contains clickable events that show all the important things that happened that game, automatically placing the map at that moment for added visual clarity.
For all of your games, you can generate a epic story that describes what happened to you that game. From heartbreaking tragedies to inspirational triumphs, the prose describes a dramatic and exciting story from the perspective of the game Referencing key events that occurred in game like the grand duels and desperate battles which any true League player knows they are.
You can also get an in-depth recap of your last 100 games, complete with an AI-generated analysis of your playstyle. You can also compare yourself to your friends, and get AI-comparisons of your different personalities and, most importantly, answer the real question: who's the better player?
How we built it
Whenever you load a players match history, it sends a POST request to the fetch-timeline endpoint lambda function that analyzes and parses timeline data for that player. It reads through the timeline data from the RIOT API, and converts to a highly readable format that can easily be used to determine game states and changes over time. Factors like objective differential and changes in gold, as well as lane specific stats are all recorded explicitly.
This parsed file is then stored in an S3 bucket. Another lambda function is set to trigger whenever this bucket is populated. This bucket forces a sync of the knowledge base that contains all of the parsed endpoints, as well as metadata to determine which match it originated from.
A third endpoint is used to determine when the knowledge base is done with the sync, and it is possible to query the chatbot.
Whenever you drag a game into the chatbot, it adds the match_id to a list. It also adds the PUUID of the player of the current game, and sends this all to the analyze-match websocket, which is connected to on reaching the landing page. It then uses the knowledge base and filter on just the match_ids you sent, using a length query to provide a very structured and detailed response use a Bedrock agent performing RAG.
The story generator waits for the ingestion to be finished. When a player selects a specific match, it has a Bedrock agent take the parsed timeline data from the s3 bucket and develop a story regarding it. Various other features were implemented by properly extracting the data from the RIOT API endpoints. The score uses various in game factors such as damage and gold, and using different factors for each role, weighs them against your teammates and your lane opponent.
Tags are created by analyzing the match data and seeing what rare feats you were able to pull off that game. These are then displayed for each match.
Similar parsing was done on match data in order to create to create the last 100 games analyses. Bedrock LLMs were used on that parsed data as well to get the recaps.
Challenges we ran into
Many requests, due to nature of being an LLM, took an excessive amount of time to run. Lambda function would often time out, and to remedy this we had to migrate to using websockets since they would resolve this issue.
The LLM initially took around 50 seconds to respond. It attempted an agentic workflow along with rang, where a central agent would call RAG LLMS to analyze specific parts of the data to improve accuracy. Naturally, this had time constraints, and we deemed these to be beyond realistic. To resolve this, we replaced it with a single RAG agent, but this naturally reduced accuracy greatly. The LLM often hallucinated when given multiple match contexts, and gave very few specifics or accurate iterations.
To resolve this, we went through multiple iterations of parsing. The current one is much conciser than others, and only focuses on important events. It also refers to every champion by their Name and PUUID, so the LLM can remember who they need to be focusing on, since it's analyzing multiple games where the player likely played multiple champions. With just one PUUID to Champ Name dictionary, due to chunking, the LLM was prone to much hallucinations.
Additionally, it struggled to understand the flow of the game. A system where key events were focused on, and gold leads were put into perspective through things like differentials and changes over time allowed for much more accurate results with this single agent model
There were also issues with ingestion timings. If the user tried to query the chatbot or generate a story too fast, the data wouldn't be synced. So beyond just a response when the timeline data was parsed, it was important to check the active jobs in the knowledge base to determine when it was actually possible to analyze the data. The client would need to constantly poll this model until it received an affirmative result, at which point it would enable various UI elements that require this data.
Accomplishments that we're proud of
The UI is one major component that we are proud of. Although it is not initially very intuitive, largely due to the uniqueness of this application, dragging and dropping matches that are relevant to analyze is a very convenient and easy way to focus the analysis on games you care about once you use it. The responses of the LLM are also quite solid; it rarely hallucinates and is often able to provide good analysis on areas of improvement.
Other UI aspects like the events timeline is also very enjoyable to use. You can see how the game played out casually in queue without having to watch the entire replay, and clicking on the events shows the approximate game state on the map, highlighting in gold the champions or objectives involved in that event. Rather than just a timeline, the visual aid helps significantly in actually being able to remember what was going on in the game. Hovering over champions to see items and health in that frame was also helpful for this.
The story, although appearing to be quite easy, was difficult to actually make interesting. The first few results were either not specific, abandoned or attached to closely to the idea of League of Legends as a video game, or just were not engaging to read. Through the iteration, we were able to make a story that generally does convey what actually happened in the game, balancing the League of Legends events with creating engaging prose.
What we learned
Coming into this project, we had minimal experience with using AWS for such a complex project. We learned a lot about how to setup an AWS project, and how to manage users, roles, and policies for all of the aspects of your project. This was a significantly more complex task than initially expected, and arguably caused the most difficulties of this entire project.
Additionally, we learned so much about how to properly parse data, as well as how to properly prompt LLMs to read that data. There was an unbelievable difference in how much this changed the performance of the LLM, from almost entirely useless to being a solid aid.
What's next for Playmaker
In the future, we would like to improve the application to handle more users consecutively, as well as larger user base in general. The application would likely suffer currently under heavy lead, since there is only one knowledge base containing all of the parsed timeline data, although it is filtered.
Additionally, a better system than constant polling would be ideal for the KB to reduce the API calls. Latency improvement are. not immediately clear, but that would be an ideal next step as the time it takes for responses may be prohibitive to some users.
Built With
- amazon-web-services
- bedrock
- claude
- lambda
- nextjs
- python
- s3
- typescript



Log in or sign up for Devpost to join the conversation.