-
-

workflow-and-mapping
-

how-the-jam-is-controlled
-

cardboard speaker


Inspiration
Voice is so powerful. Games are fun. Let's make something about it! Started as a python prototype, where one would use the voice loudness to control an avatar in a standard 2D obstacle game. Let's add pitch control! This would be way more fun if it was embedded (Bela!) with an LED display. Damn! no LED display.. wait a minute, let's do it web based! Oh, so playing alone is not that great...so what if we got another person in to create the obstacles? And what if this obstacles were also creating the game soundtrack? This could be amazing! And so it is :)
What it does
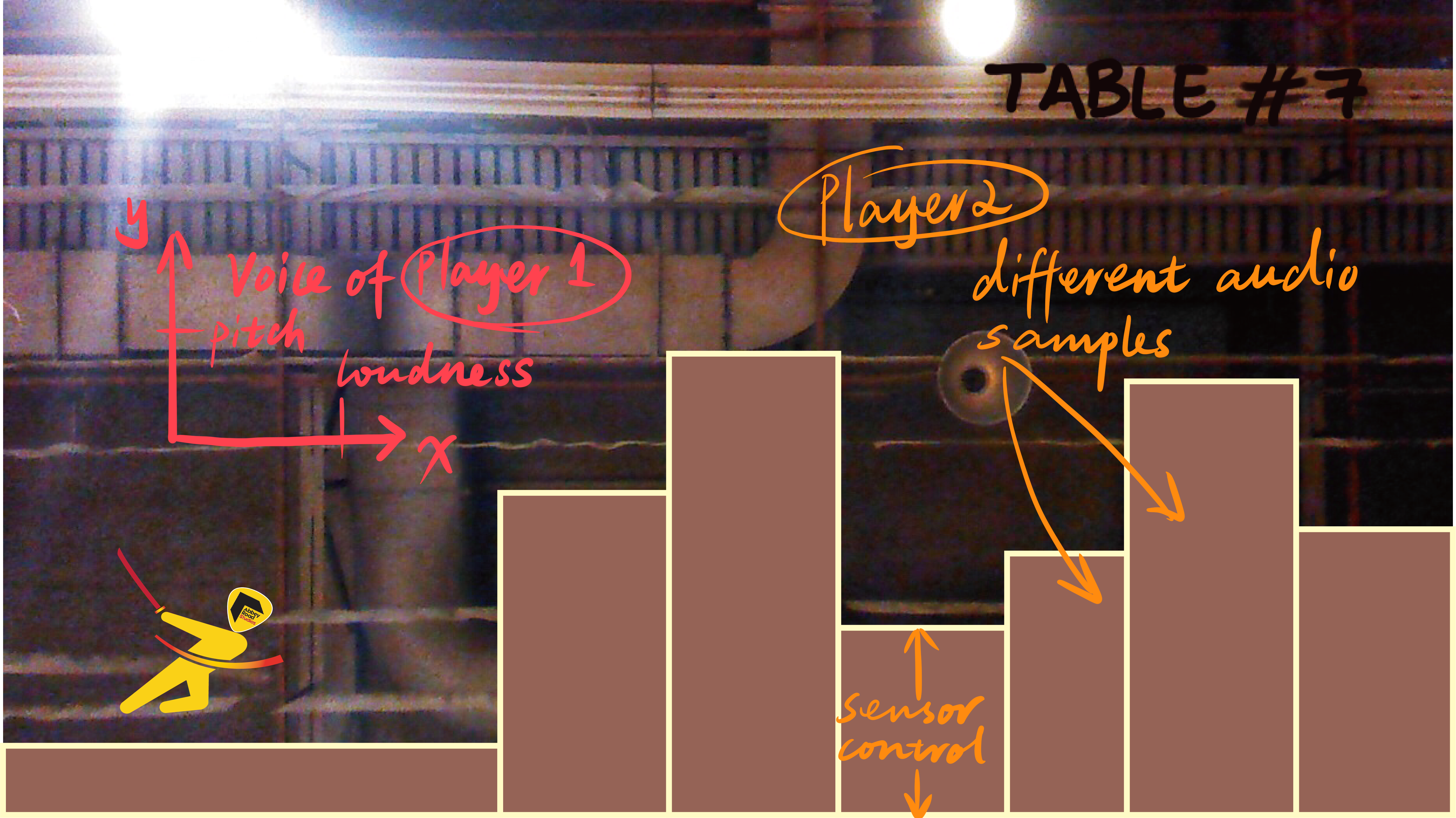
"Play the singer" is a two player obstacle game. Player #1 controls the avatar with the voice: pitch for 'up/down' and loudness for the speed of moving forward. Her/his goal is to overcome the obstacles that may appear. Player #2 creates the obstacles with a MIDI controller, that will at the same time induce the soundtrack. Her/his goal is to discover Player #1 's vocal range, in other words, give them a little bit of a hard time :) The generative soundtrack creating the ambience is based on some samples that the user can choose using a query to Freesound from Audio Commons. You just need to type some keywords and the system will do the rest!
The whole point is about controlling with voice with low latency, interactive responsiveness. No time for calling API server in the USA. Here and now, responsive voice controls. Intuitive and immediate.
How we built it
We decided to go embedded, and use Bela to do this. Bela runs aubio, which supports MIR algorithms for real time implementation. We take pitch and amplitude from live signal and these parameters are sent through websocket and OSC to a web page running a visualisation of the game. The web page is a temporary solution, as the game could be rendered on any portable screen.
First part was to get pitch detection running and working with our microphones. Luckily we brought two, so we could take advantage for denoising. Then we had to make our MIDI controller talk to Bela and decide what was going to control what. In the mean time, the interface for the game was being created web based, so the next step was to learn how to send over the controller info to the client. In parallel the soundtrack was being created taking into account the different inputs that will control different parameters of the music. This is sample based, so we decided to let the user choose which samples using keywords (i.e. a query to Freesound script ).
Technology
Using innovative "patent-pending" noise-subtracting technique using multi-channel microphone capsules to reject ambient noise and allow you to play also in noisy environment. Using low-latency, embedded pitch and amplitude tracking of the voice for immediate responsiveness and increased engagement. Local WebSocket and OSC are used to communicate to the GUI. 3D-printed microphone headset and clips. DIY lo-fi cardboard speaker to pretend we are actually lo-tech (typical East-London hipster).
Challenges we ran into
A lot! Controlling with voice with low latency, interactive responsiveness is not an easy task! Did we mention web GUIs in a language none of us ever used before?
Accomplishments that we're proud of
It's genuinely fun. It's accessible and it's a proof that intuitive, rich interaction has many pros, even in a word where Artificial Intelligence, MIR, Machine Learning, Deep Learning, Neural Networks are so in hype.
What we learned
This hack required a lot of different skills and noone of it could have happened going solo; so other than a big bunch of tech stuff we have definitely learned (succeded) how to communicate with each other (and other machines) in various different languages!
What's next for play the singer
Jamming with a machine. Let's say you want to sing along a generative song the machine is composing real time using real time. Where do you get the queues from? How do you adapt to what's happening next? If there was some sort of visual interface that was being created at the same time the singer could see where the song is going and adjust. Moreover, this can go both ways! Here, you can't look back at the 'drummer' and give it the 'fill' eyes. So what if your vocals changed the AI composition? What if you can physically induce queues with some sort of gestural interface?
Built With
- aubio
- audiocommons
- bela
- p5.js
- puredata



Log in or sign up for Devpost to join the conversation.