"Play & Sing with Alan":
Play & Sing with Alan teaches adult beginners to play guitar and sing at the same time — the coordination most learners quit over. The new AI intake mentor talks with each prospective student by voice, in English or Spanish, runs a real ear-and-rhythm assessment, and places them into one of the method's three stages. The student walks away with a tailored plan and a reason to book; Alan walks into the first lesson already knowing exactly who he's teaching.
"Inspiration":
I teach this for a living. Every free trial used to start the same way — twenty minutes spent figuring out where someone actually is before any teaching could happen. I wanted to give that time back to both of us, and to let a nervous beginner discover their starting point in a low-pressure conversation instead of a cold first lesson.
"What it does":
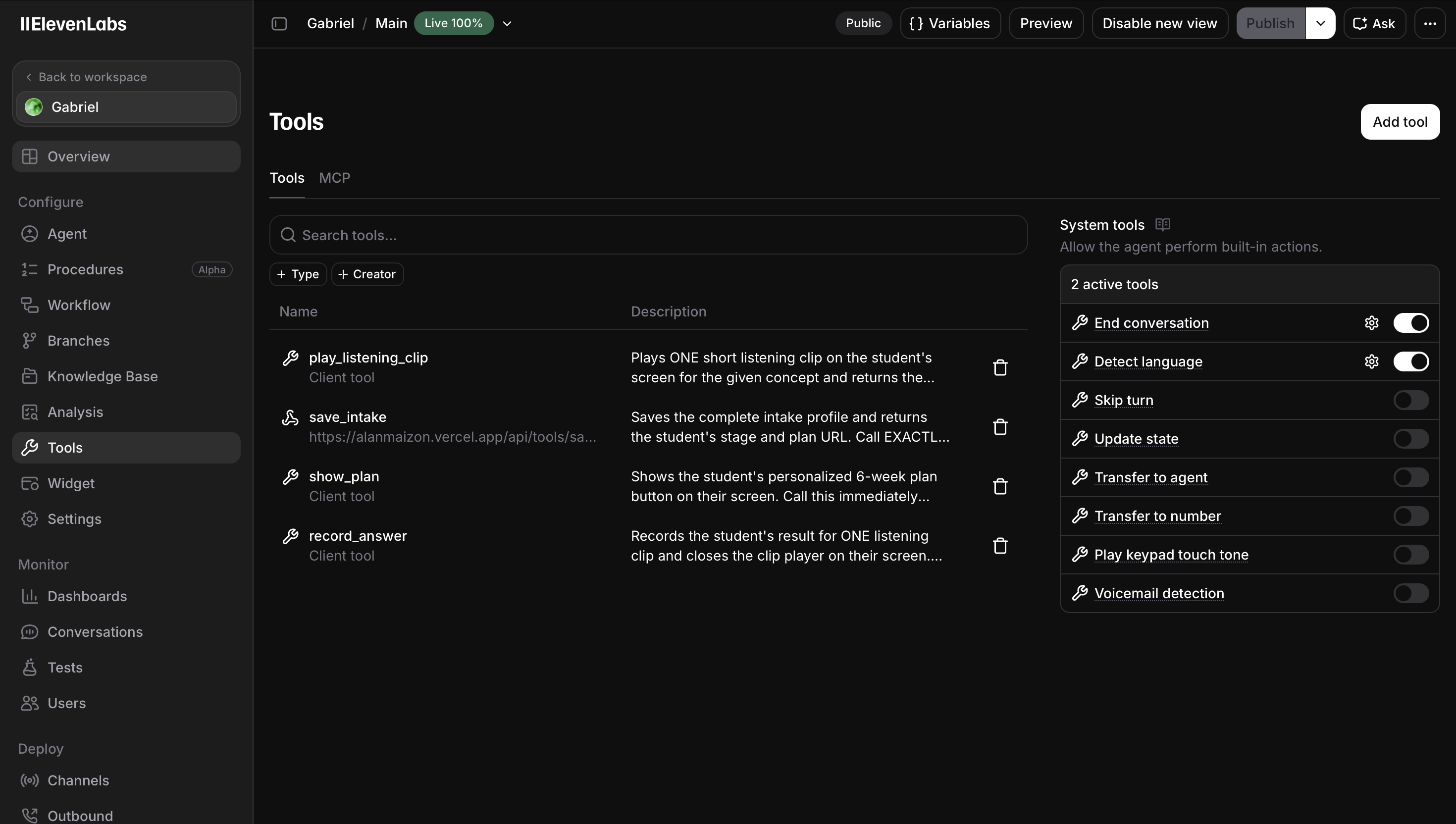
A voice agent runs a ~10-minute intake: background, what the student can do with their hands, what they can do with their voice, and the key question — what happens when they try to combine them. Then it plays short clips and tests the student's ear and sense of timing by voice. A deterministic rule set converts the answers into a stage placement (Separate, Layer, or Perform), generates a personalized 6-week curriculum seeded with the student's own goal songs, and hands me a structured intake report before the lesson.
"How we built it":
Frontend scaffolded with v0 and deployed on Vercel — a bilingual Next.js site with the ElevenLabs voice agent embedded inline via the React SDK. The agent uses webhook tools to write to and read from Amazon DynamoDB, connected through Vercel's OIDC so there are no long-lived AWS credentials anywhere. Each student is a single partition (profile, per-concept ear results, generated plan) designed around the app's real access patterns, with a GSI powering the teacher's intake dashboard. Placement is computed by deterministic code, not the language model — the same answers always produce the same stage, so it's auditable. The assessment clips are generated with ElevenLabs' Music API, but pre-generated and validated offline rather than live: I tested live generation for reliability, found it inconsistent for short assessment clips, and designed around that finding.
"Challenges":
Getting the agent's tool schema accepted, reliable tool-calling mid-conversation, and iOS audio autoplay inside a live voice session were the real fights. The biggest design decision was keeping the language model out of the scoring loop — it conducts the conversation, but code makes every placement decision.
"What's next":
Spanish-first cohorts, a returning-student progress check, and feeding completed-lesson data back into each student's plan.
Built With
- amazon-web-services
- vercel

Log in or sign up for Devpost to join the conversation.