-
-
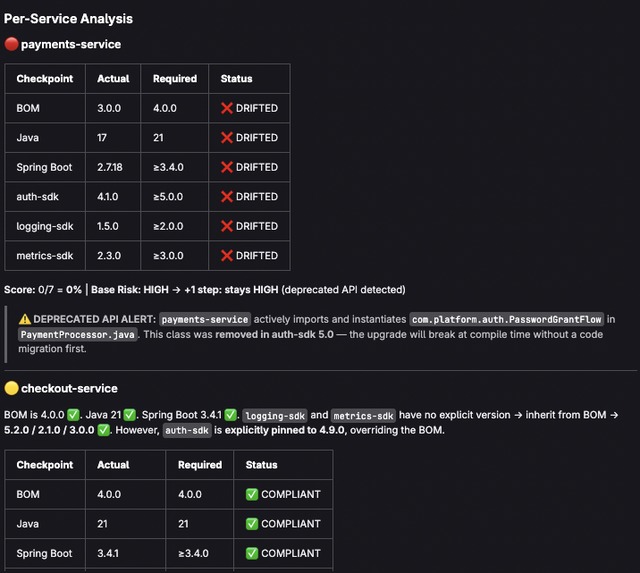
Service Drift summary
-
Indexed info
-
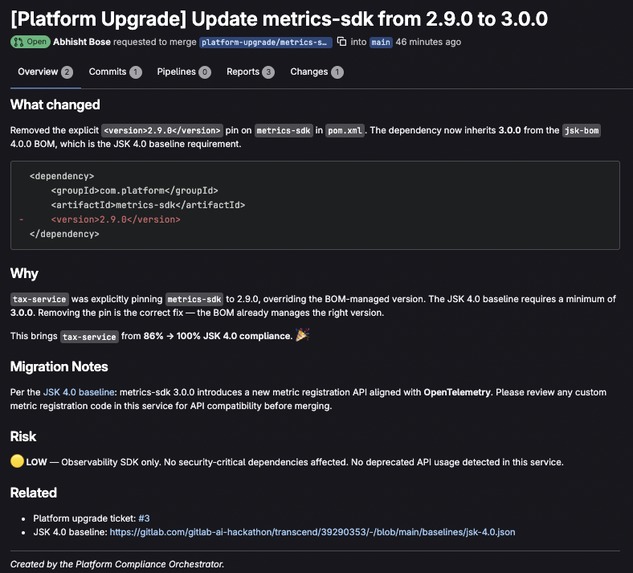
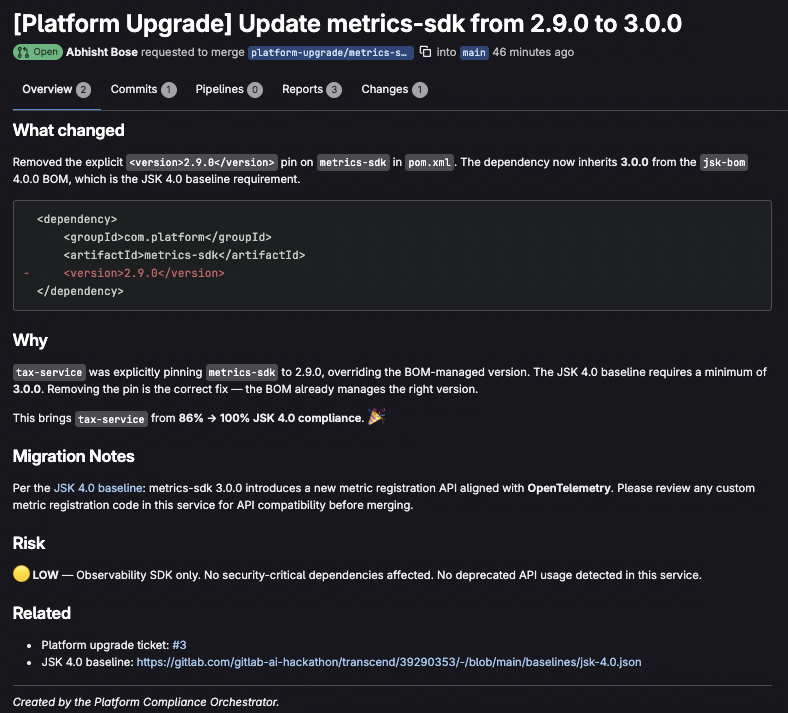
MR raised for remediation by Agent
-
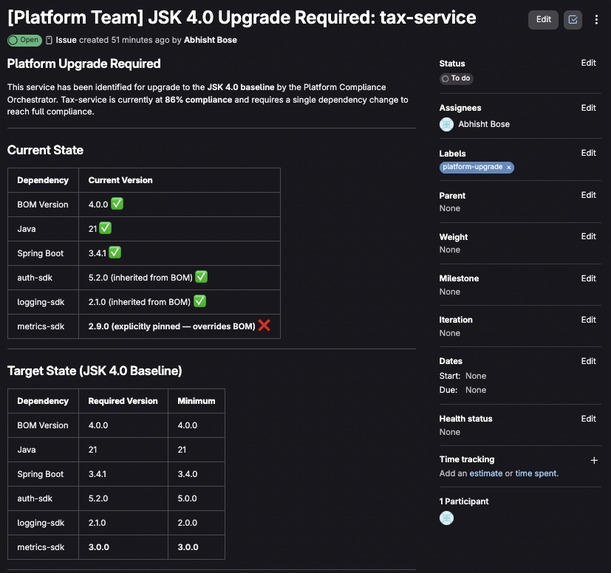
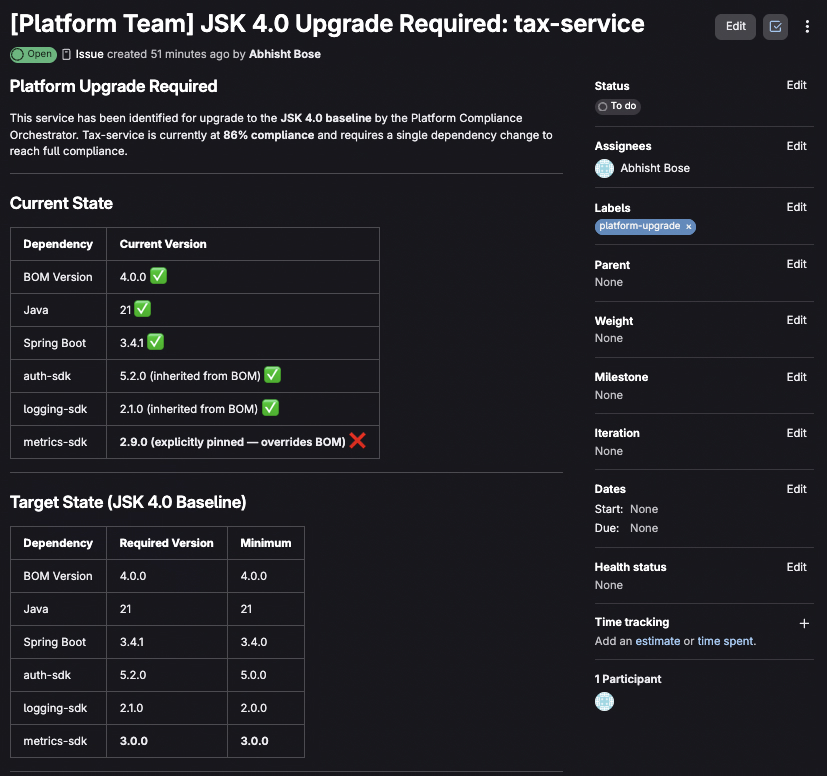
Issue Created by Agent
-
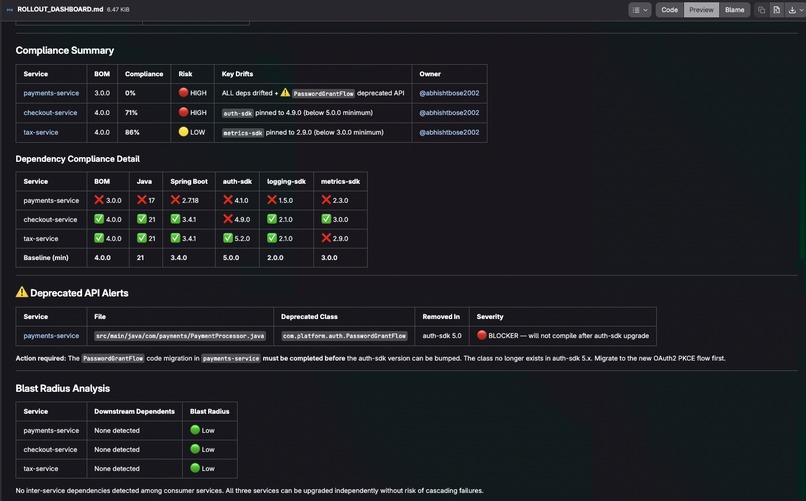
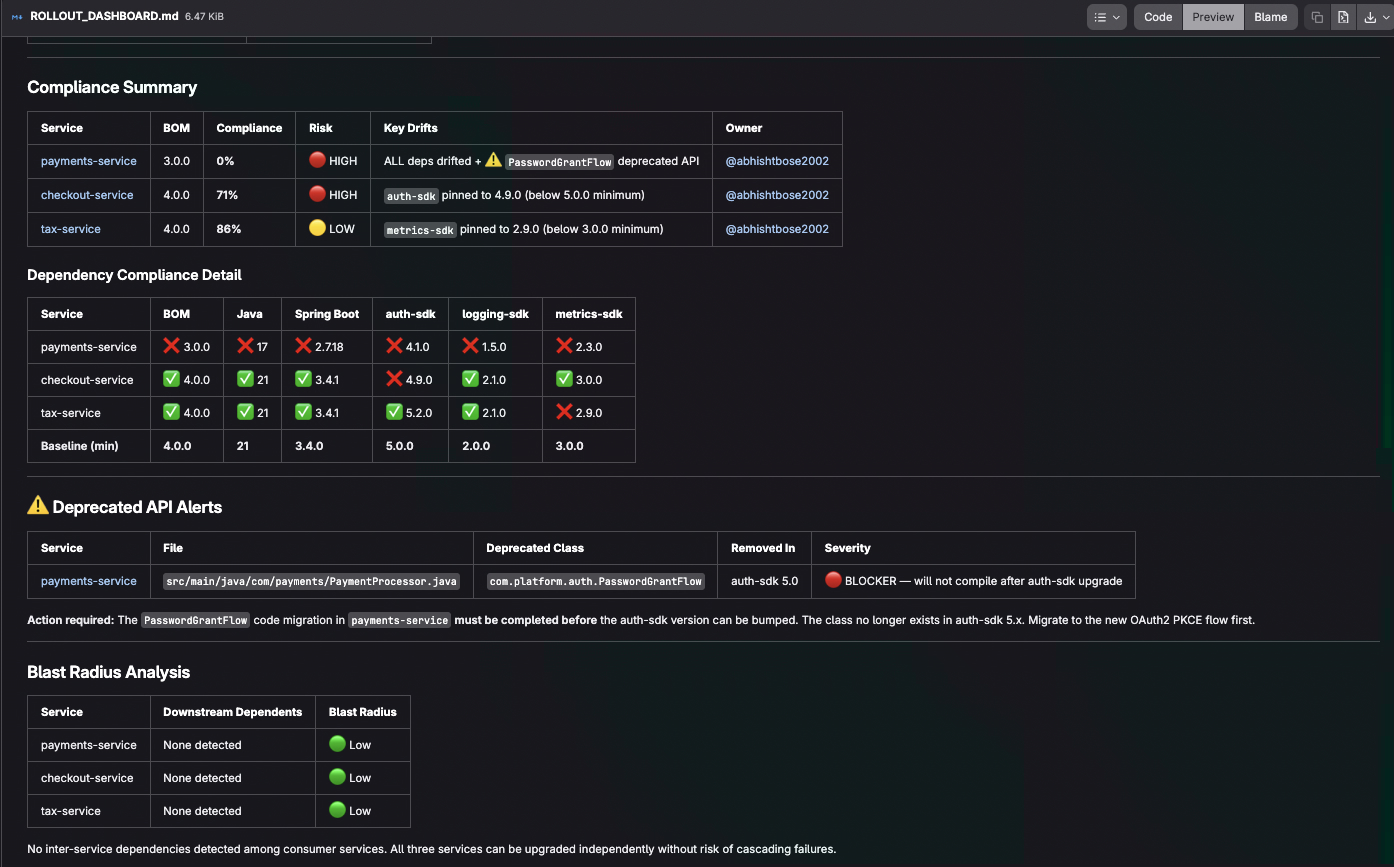
Summary Created for platform engineer
-
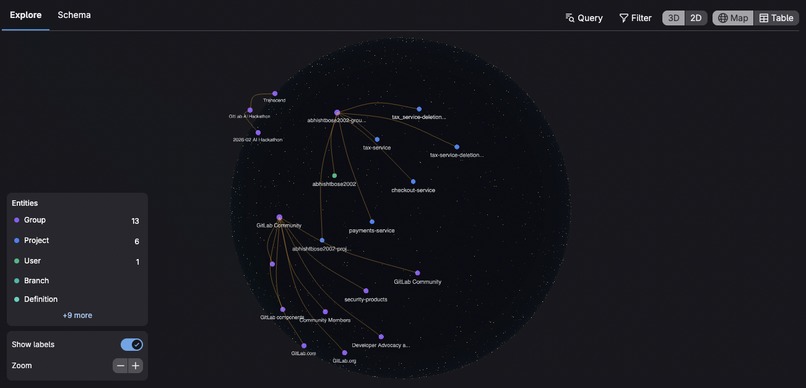
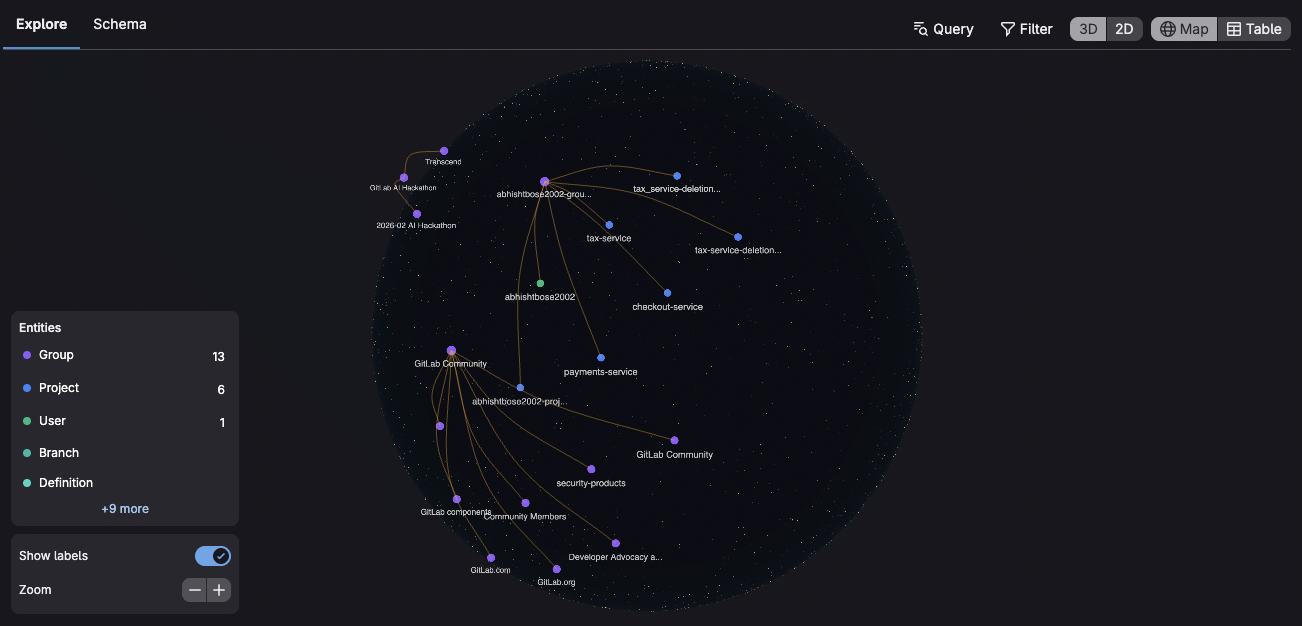
Orbit Knowledge Graph
Inspiration
In large organizations, platform teams maintain shared libraries, SDKs, and frameworks — packaged as a "starter kit" or BOM (Bill of Materials). When the platform team releases a new baseline, dozens of consumer services need to adopt it. But the platform team has no automated way to answer basic questions: Who's behind? How risky is the drift? Who owns the service? Is someone already working on upgrading?
Today this is handled with spreadsheets, Slack messages, and manually chasing teams — a process that stretches weeks or months for a single baseline rollout.
At its core, platform compliance is a graph problem: who depends on what, who owns what, what work already exists. That's exactly what Orbit's knowledge graph represents. We used it not just for code intelligence within a single project, but for cross-organization adoption tracking — discovering which services consume platform libraries, what versions they're actually running, and where upgrade work is already in progress. We built an agent that replaces weeks of manual coordination with a single conversation.
What it does
The Platform Compliance Orchestrator is a custom AI agent that gives platform engineers a conversational interface to manage baseline adoption across consumer services.
A platform engineer enables the agent from the AI Catalog, opens VS Code with the GitLab extension, selects Platform Compliance Orchestrator from the Duo Agent panel, and asks it to scan consumers against the baseline. Two SKILL.md files load automatically from the project root — no additional configuration needed.
From there, the agent can:
- Discover which services use platform libraries across projects —
using Orbit's
query_graphto traceImportedSymboledges matchingcom.platform.jsk.*across every repo in the org. No hardcoded list, no config file, pure graph discovery. - Analyze each service's actual dependency versions against the
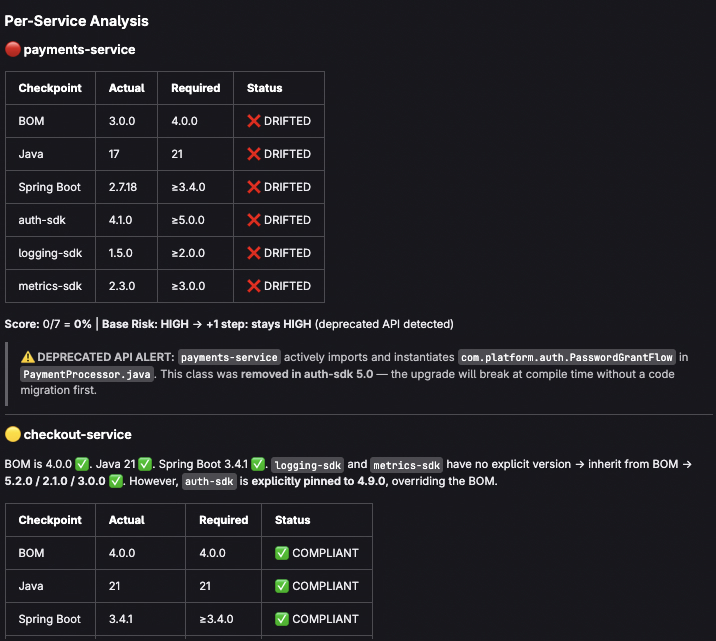
platform baseline, catching hidden drift — for example, a service can
import BOM 4.0.0 but override
auth-sdkto an older version. The agent checks each dependency individually, distinguishing inherited versions from explicit overrides. - Score compliance with weighted risk assessment — security-critical
dependencies like
auth-sdkcarry higher weight than observability SDKs. - Detect deprecated API usage that means upgrades need code changes, not just version bumps.
- Prioritize rollout using four factors: quick wins, existing momentum, blast radius, and team load.
- Create upgrade tickets in consumer repos with full context.
- Generate upgrade MRs with the actual
pom.xmlchanges. - Commit a rollout dashboard to the platform project tracking the entire campaign.
How we built it
Custom Agent published to the GitLab AI Catalog with a system prompt that orchestrates the full workflow — discovery, analysis, prioritization, and action.
Two SKILL.md files in the platform project teach the agent domain knowledge:
compliance-scanner— how to parsepom.xmlfiles, calculate weighted compliance scores, and assess risk with modifiersrollout-planner— how to weigh prioritization factors, structure rollout waves, and format upgrade tickets
GitLab Orbit powers cross-project discovery and context:
- Queries
ImportedSymbolrelationships viaquery_graphto find every project importing platform libraries — tracing actual Java import statements across the org, not keyword search - Detects deprecated API patterns by querying symbol usage that maps to retired platform interfaces
- Surfaces existing work items and MRs linked to consumer projects to prevent duplicate effort
- Maps project ownership metadata for ticket assignment
GitLab tools — the agent uses 20+ GitLab tools across four categories:
- File access:
get_repository_file,get_repository_tree— to read each consumer'spom.xmland source files - Write actions:
create_issue,create_commit,create_merge_request— to create real tickets, pushpom.xmlchanges, and open upgrade MRs - Discovery:
query_graph,blob_search— Orbit graph queries for consumer discovery, blob search as fallback for cross-group access - Context:
get_issue,list_merge_requests— to check for existing upgrade work before creating duplicates
Challenges we ran into
Orbit cross-group scoping. Our platform project lives in the hackathon namespace while consumer repos are in a personal namespace. Orbit indexes each top-level group independently, so graph queries from the agent couldn't reach consumer repo source code directly. We worked around this by having the agent fall back to GitLab API tools for cross-group file access while using Orbit for discovery from the namespace where consumers are indexed.
Agent tool selection. The LLM behind the agent consistently
preferred blob_search and group_search over Orbit's query_graph
for consumer discovery, despite explicit system prompt instructions. We
learned that LLMs treat tool selection as a probability game — familiar
patterns (search APIs) win over specialized tools (graph queries) unless
the instructions are very forceful and positioned at the top of the
prompt.
BOM ≠ compliance. Early in design, we assumed checking the BOM
version was enough. But a service can use BOM 4.0.0 and still override
auth-sdk to an old version. Recognizing this nuance shaped the entire
compliance-scanner skill — it checks each dependency individually,
distinguishing inherited versions from explicit overrides.
What we learned
- LLMs need steering toward specialized tools. Graph queries are more powerful than search APIs for cross-project discovery, but the agent defaults to familiar patterns. Prompt engineering for tool selection is its own discipline — instruction placement and forcefulness matter more than clarity alone.
- Separating domain knowledge from orchestration pays off. The SKILL.md files are reusable — another team could take the compliance-scanner skill and wire it into a different agent or flow without touching the orchestration logic. Skills are the portable unit, not agents.
- Orbit unlocks use cases beyond single-project code intelligence. We used it for cross-organization adoption tracking — a use case that doesn't exist with standard search APIs. The graph knows which projects import which symbols; that's the foundation for any large-scale migration or compliance campaign.
- The gap between "AI can chat about code" and "AI can take action on code" is where the real value lives. Discovery and analysis are useful, but the agent only becomes transformative when it creates the issues, pushes the commits, and opens the MRs.
What's next
- Multi-ecosystem support — extend beyond Maven/Java to Gradle, npm, pip, and other package managers
- Multiple baselines — support tracking JSK 3.0, 4.0, and 5.0 simultaneously for teams at different adoption stages
- Automated campaign tracking — the dashboard updates automatically as services reach compliance, with notifications to the platform team
- CI/CD integration — run compliance scans as a pipeline stage and block deployments of newly drifted services
- Blast radius via Orbit — use Orbit's cross-service dependency mapping to automatically sequence rollout waves based on service interdependencies


Log in or sign up for Devpost to join the conversation.