-
The main search page with the Plamp search bar. Not sure why image quality is so bad.
-
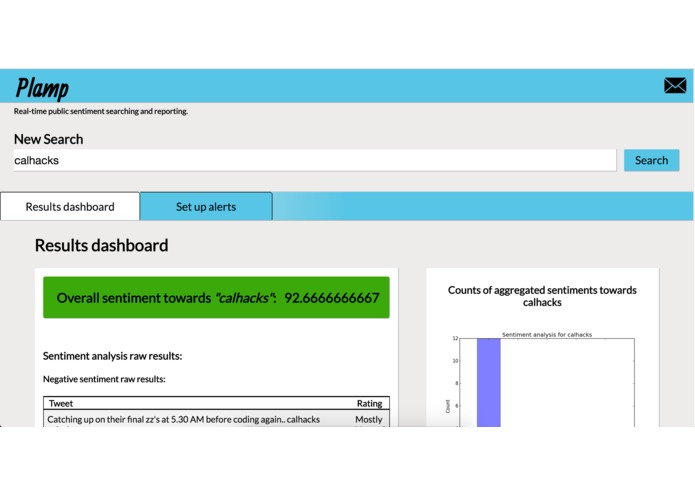
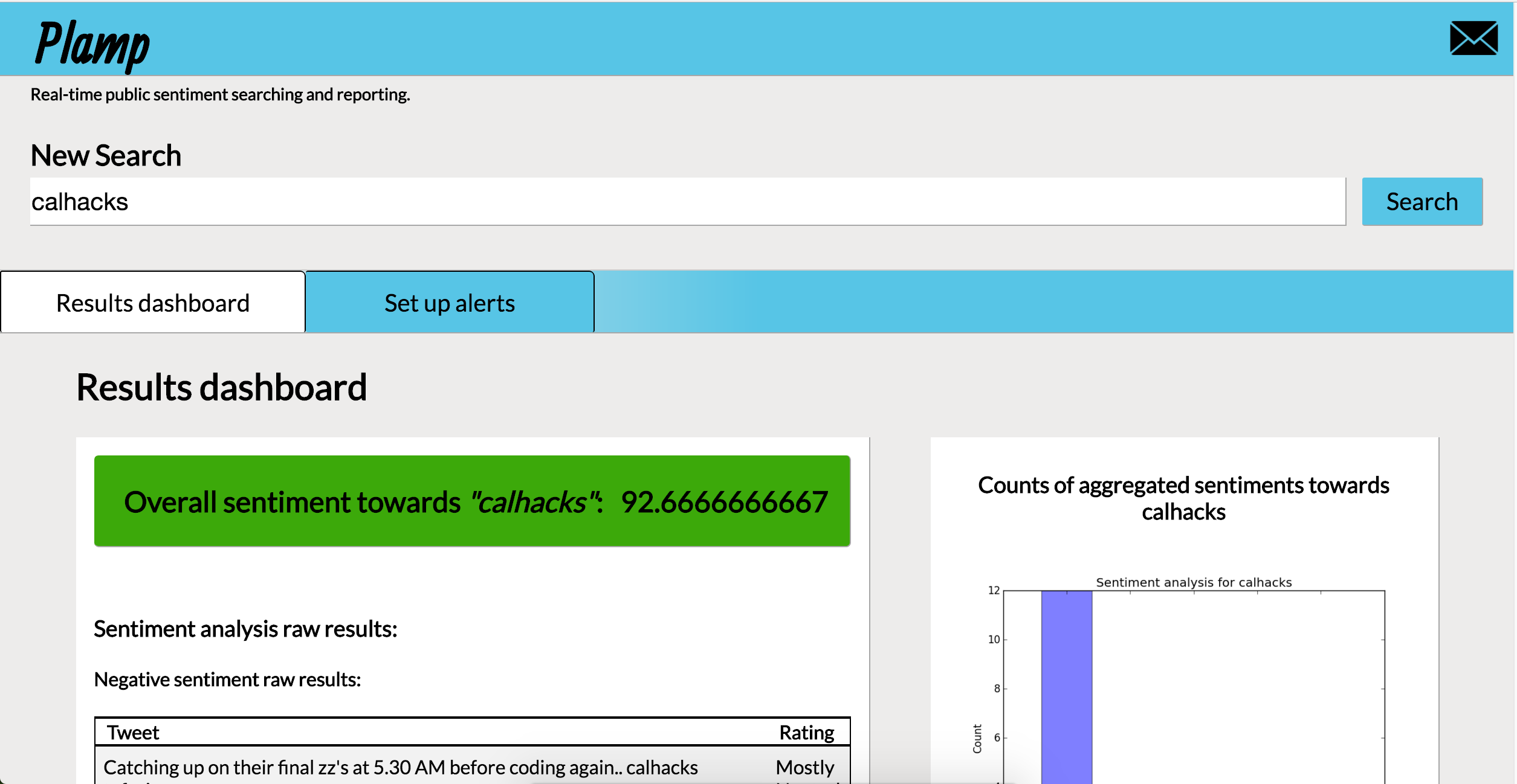
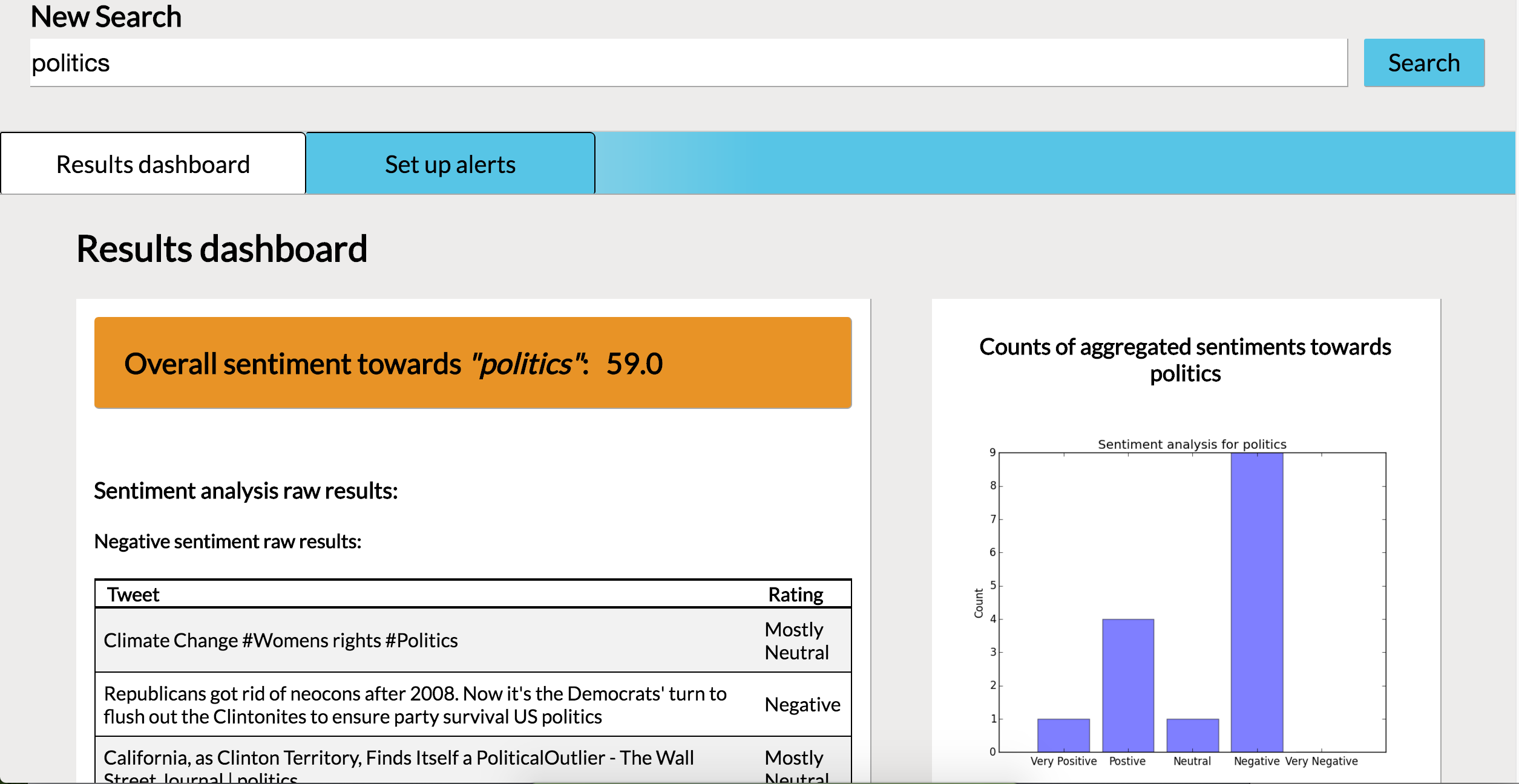
Search result report page part 1
-
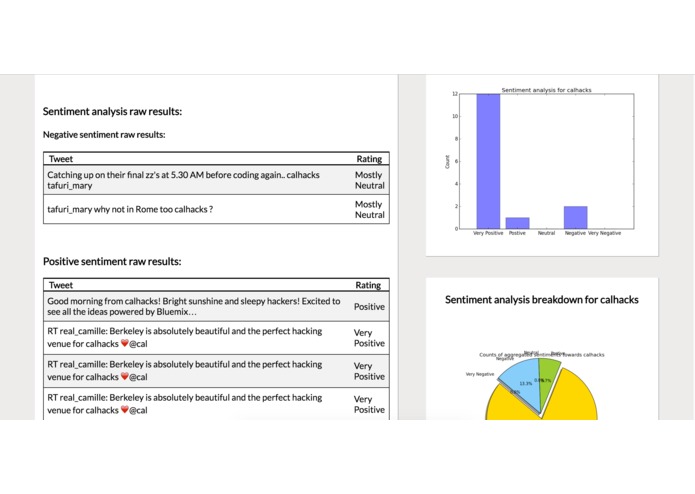
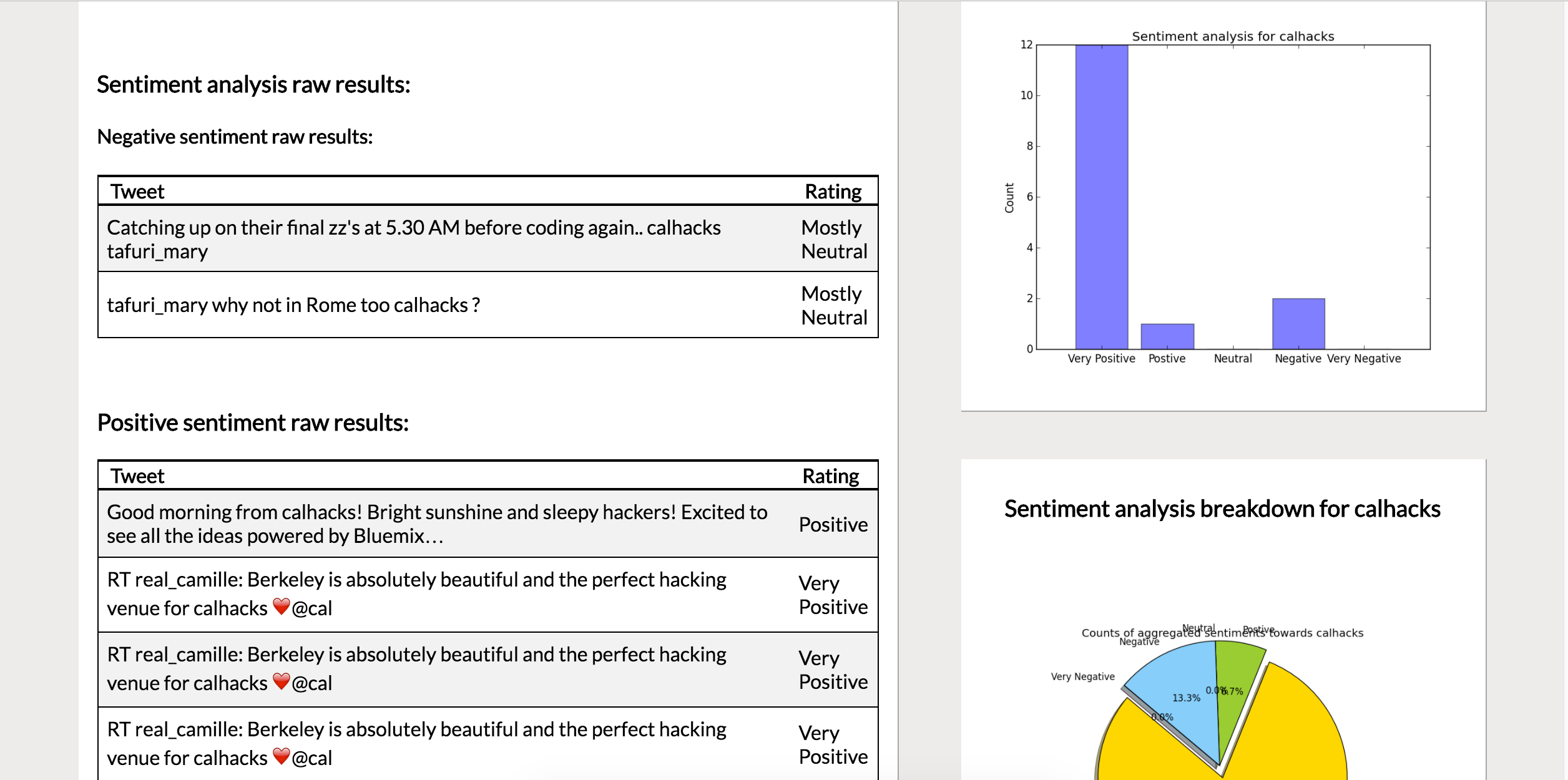
Search result report page part 2
-
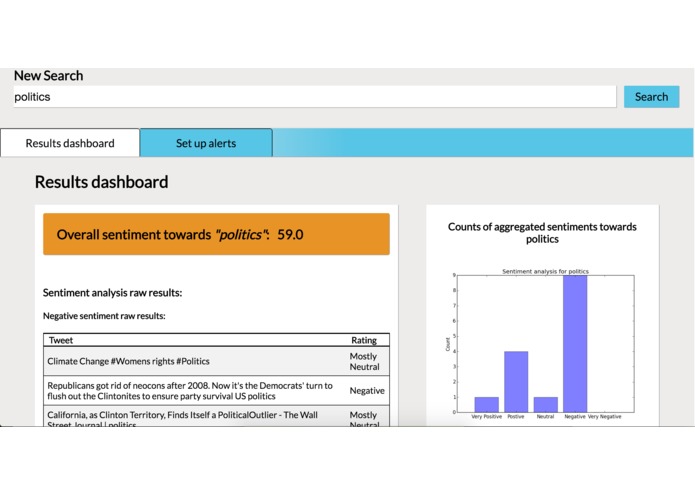
A lower sentiment query report
-
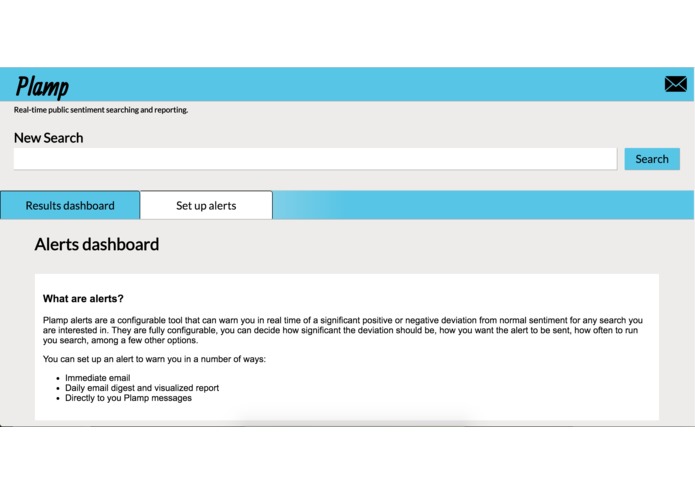
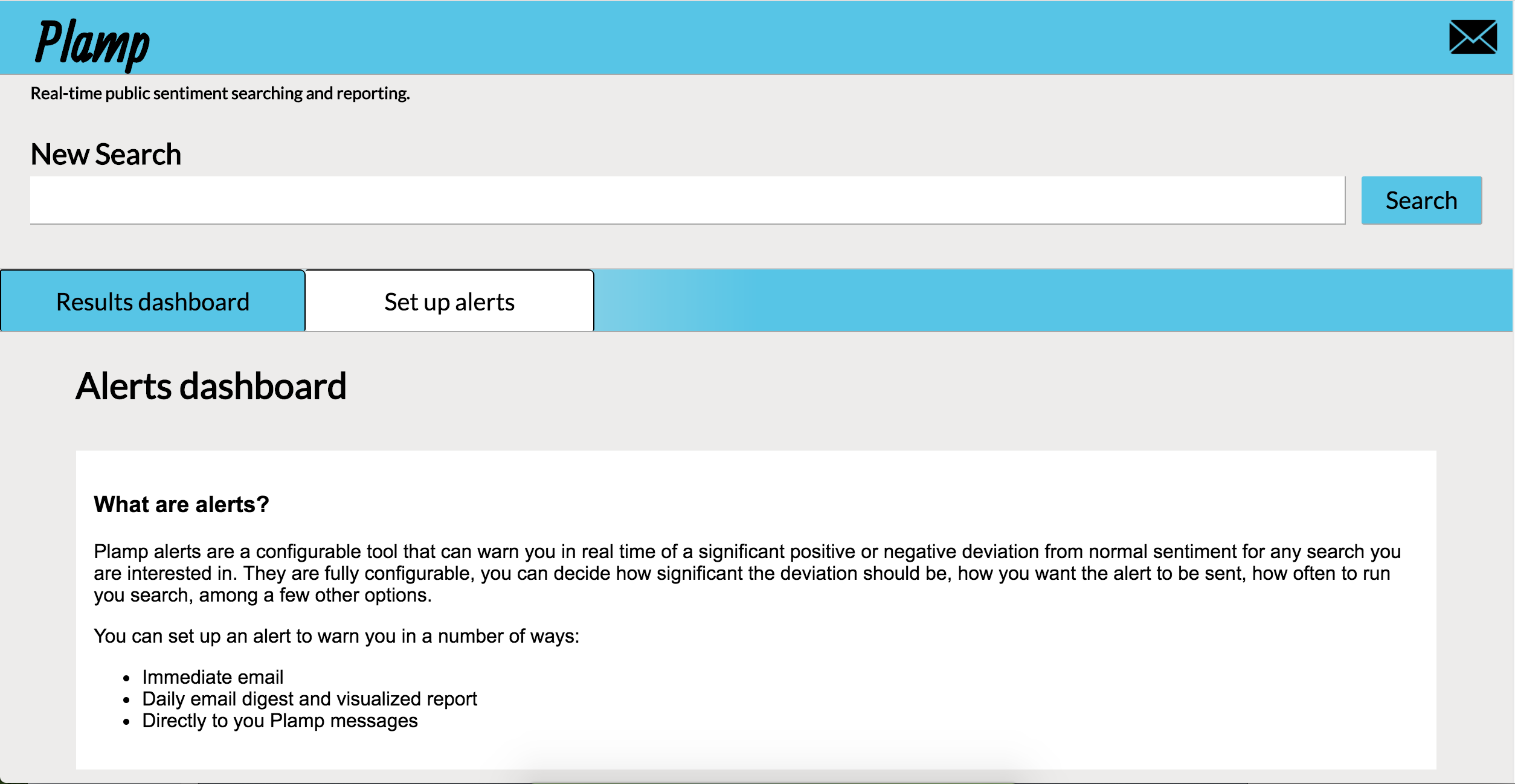
The alerts description/setup page part 1
-
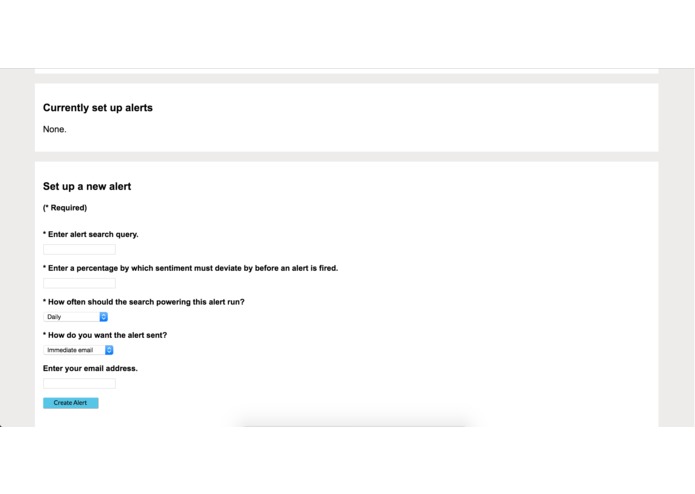
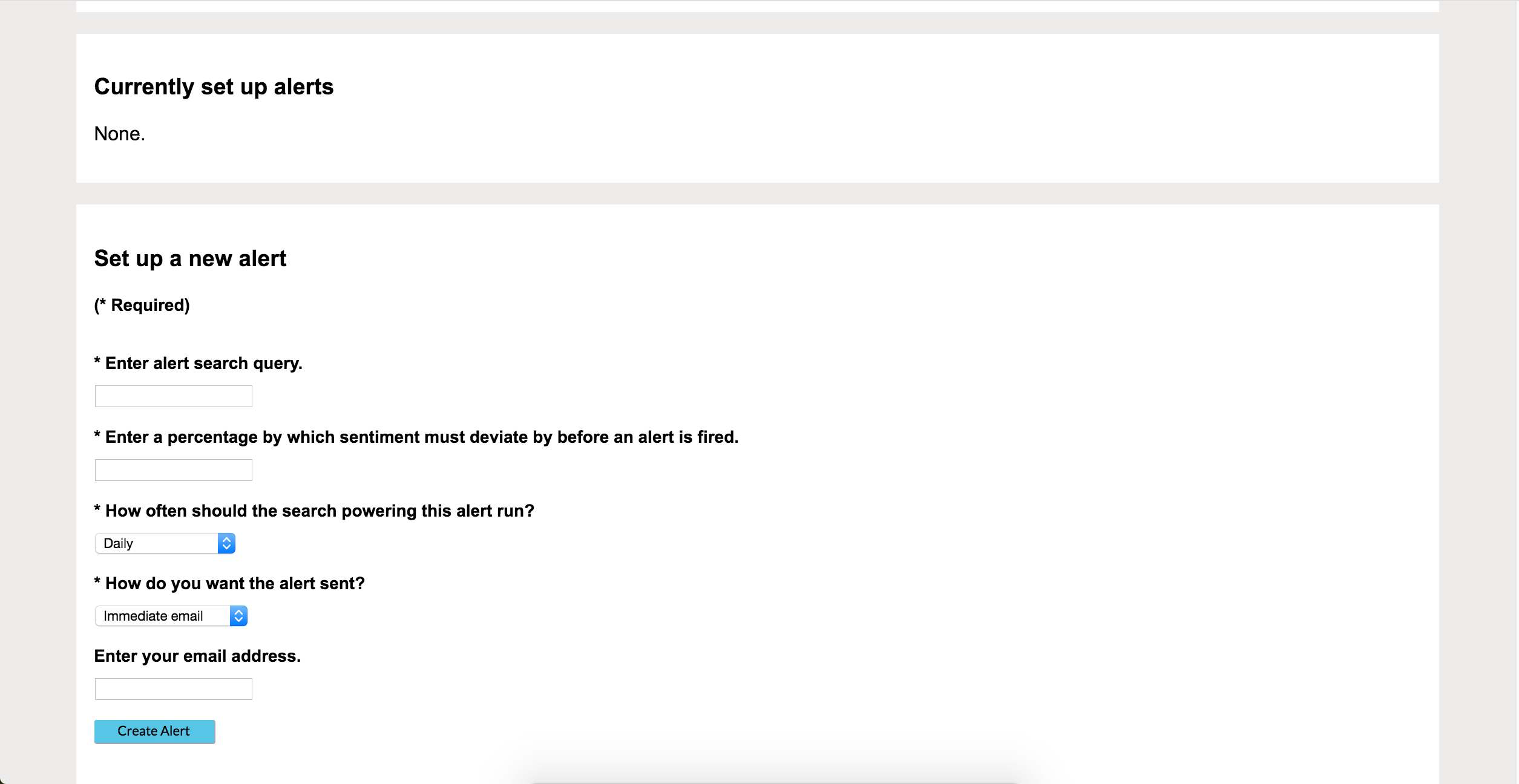
The alerts description/setup page part 2
Inspiration
I wanted to build a wordcloud type visualization for tweets that could be clickable to generate more wordclouds based on those clicks. I decided this would be too much javascript and thought a better way then clicking around would be search bar.
What it does
Plamp is a search bar for real-time public sentiment analysis. You enter in a query consisting of a word or phrase which you would like to how people are reacting to, as well as a number of (optional) variables (users involved, geolocation, time-based, popularity based, etc.). In return you get a report that gives you an overall sentiment score, a sampling of the raw tweets broken down into fairly negative and fairly positive tables, and a few graph visualizations to help better understand how the results are distributed.
Plamp also has a built in alert system that can alert a user through a number of channels if sentiment for a query they are interested in deviates from normal ranges. This happens in real time, so a user can be alerted about sentiment issues immediately and act on them.
How I built it
I built this with flask, and python is doing a lot of the heavy lifting for the query parsing, API calls, and overall analysis. The front end is just html/js/css. I'm using the meaningcloud and twitter APIs to get a list of tweets and some sentiment analysis on those and all aggregation of the results into a sentiment classification and score is all done with my own algorithm.
Challenges I ran into
I'm having trouble actually deploying the project. Also, the twitter REST API is very stingy with API calls and only responds with a small sampling of tweets which made this a bit more difficult. I also had to limit myself to one because the free plans for the sentiment analysis tools I was using limit API calls per second, and adding more would have made the query processing time a bit too long.
Accomplishments that I'm proud of
When I first got the "pipeline" from user submitted search query, to query parsing, to using that tweet to get a list of tweets to extract sentiment and metadata from, to then actually displaying a score that made sense on the result page. I was pretty excited.
What I learned
I was careful with documentation and code organization from the beginning and it made a huge difference in my productivity. Although next time I will also split my code up into multiple files because it got a little long for this project.
What's next for Plamp
I want to use some of twitter's other APIs that allow for a larger quantity of tweets to taken in. I also want to improve sentiment analysis by digging farther into the data I am getting back and updating my algorithm (As an example I am not doing anything about irony, which is a metric and that I get back). I also want to integrate a few more sentiment analysis APIs to improve the quality of the results. Lastly, I want the final dashboard to provide some really good insight through some cool visualizations, which will happen once I set up and account system and start storing query results and showing how sentiment is changing over time.
I'm going to build out a few use cases and see which one make the most sense going forward so I can focus on those. I'd like this Plamp become a tool a marketing team could use to gauge their brand and respond to issues in real time. Eventually it would be cool to incorporate some machine learning into this and turn it into a "focus group" simulation, where a user could get an accurate prediction on the sentiment that would follow from a tweet.

Log in or sign up for Devpost to join the conversation.