-
-
Homepage
-
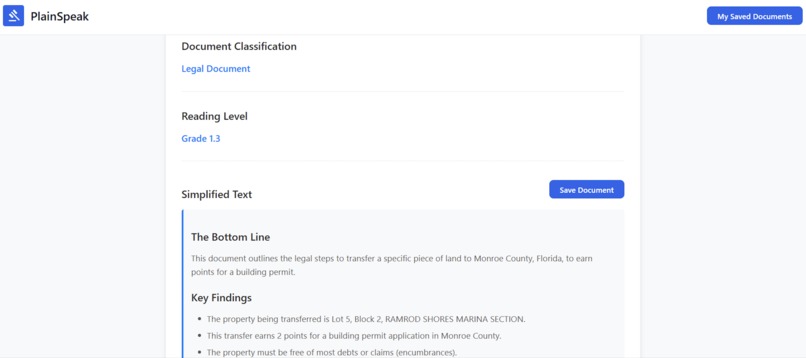
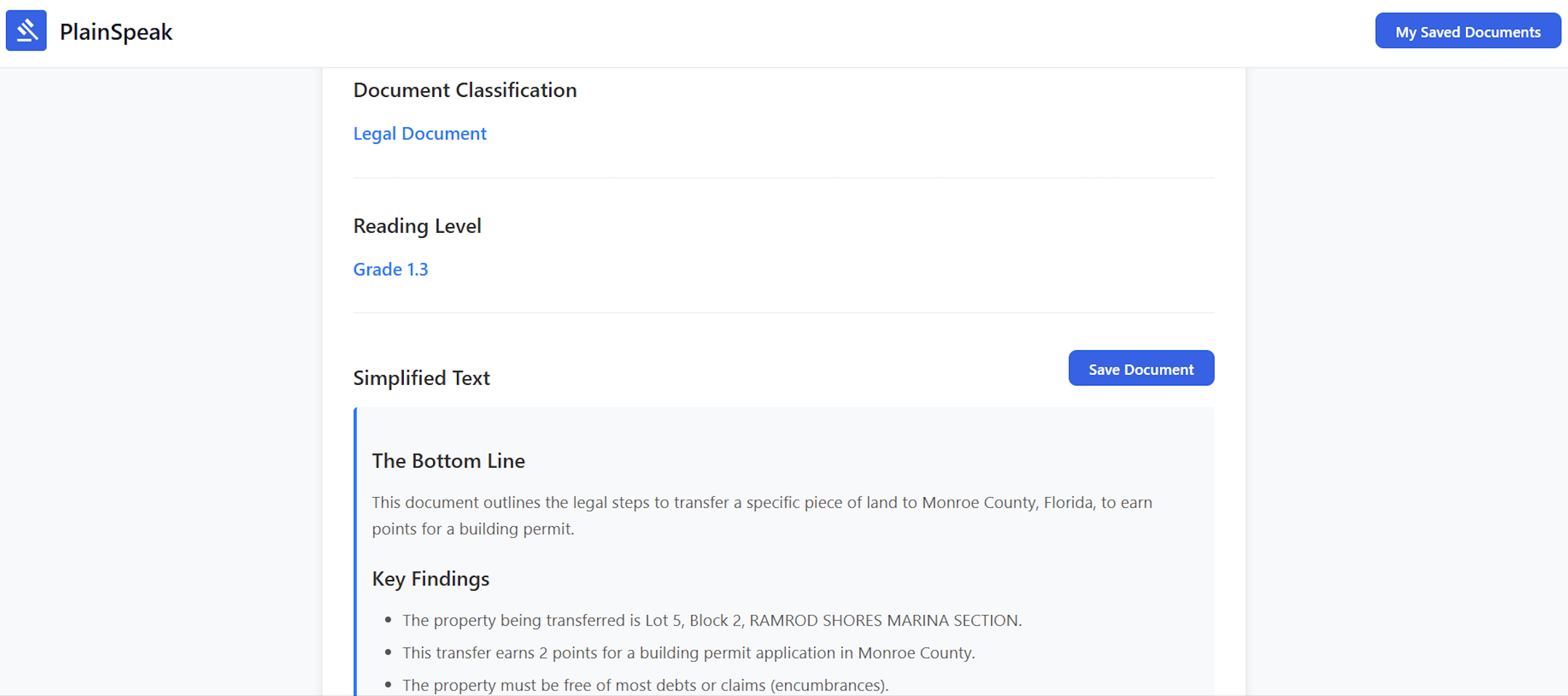
Generating the simple summary
-
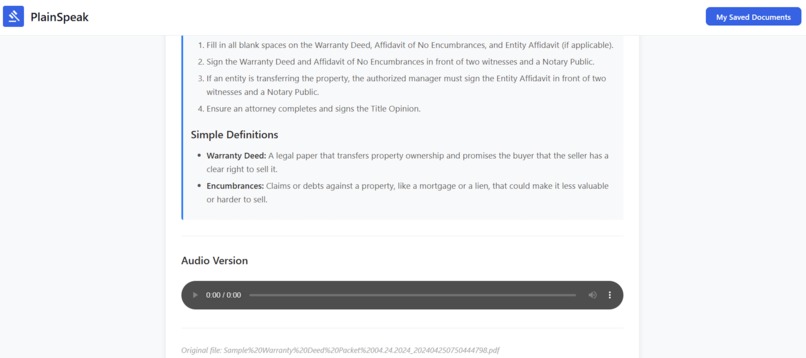
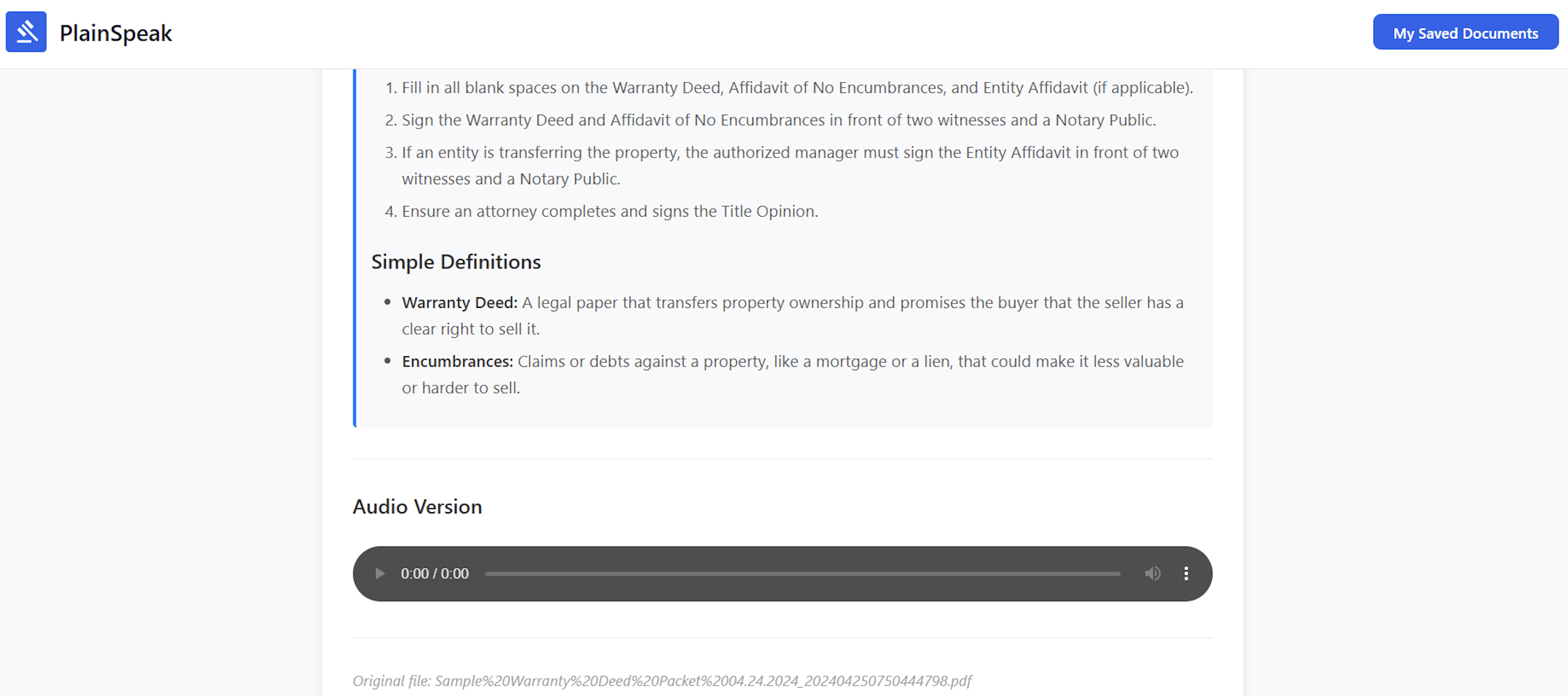
Summary along with audio
-
Saved documents tab
-
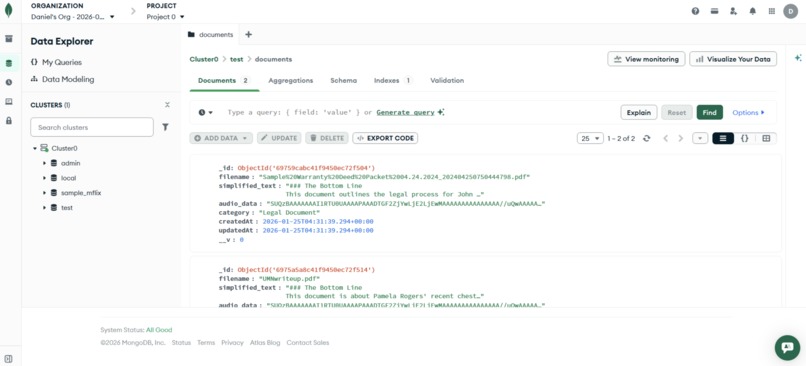
A look into the database
Inspiration
Legal documents, government forms, healthcare paperwork, and technical policies all share the same reputation: they’re difficult to read, intimidating, and easy to misunderstand. We’ve all run into a document that felt deliberately dense - something you have to agree to, sign, or submit, but don’t fully understand. That gap creates real consequences, whether it’s missing benefits, signing away rights, or simply feeling locked out of systems you’re supposed to use. PlainSpeak came from the idea that understanding information shouldn’t require a law degree.
What it does
PlainSpeak takes complex documents and breaks them down into smaller, easier-to-understand pieces while preserving the important details and intent of the original text. Users can upload a document and receive a simplified explanation alongside the original, with a clear what this means for you breakdown. For accessibility, the simplified version can also be read aloud, making the content usable for people with visual impairments or reading difficulties.
How we built it
The front end is a web application built with React using Vite, along with standard HTML, CSS, and JavaScript for layout and interaction. When a user uploads a document, it’s stored in MongoDB Atlas for persistence and future reference.
From there, the backend sends the document to Google Gemini for interpretation and simplification. Gemini analyzes the text, classifies it, rewrites it in plain language, and generates contextual explanations. Those results are then stored back in the database and sent to the front end for display. We also integrated ElevenLabs to convert the simplified text into natural-sounding speech, keeping accessibility as a first-class feature rather than an afterthought.
Challenges we ran into
Everything.
More specifically: integrating multiple services under tight time constraints, getting consistent outputs from the AI while preserving meaning, and coordinating data flow between the frontend, backend, database, and AI APIs. We also had to make constant tradeoffs between accuracy, simplicity, and speed. Debugging API responses at 1 a.m. was a recurring theme.
Accomplishments that we’re proud of
We’re proud that we shipped a working, end-to-end product that actually solves a real problem. PlainSpeak doesn’t just summarize text, it explains it in a way that’s useful to non-experts. We also successfully integrated multiple sponsor technologies (Gemini, MongoDB, ElevenLabs) into a cohesive system and built an accessibility-focused experience rather than treating accessibility as an add-on.
What we learned
We learned a lot about AI orchestration - especially how prompt design and structured outputs matter just as much as the model itself. On the engineering side, we gained experience building and wiring together a full-stack system under hackathon pressure. We also learned how quickly complexity grows when you’re dealing with multiple developers, real documents, and usable outcomes.
What’s next for PlainSpeak
Next, we want to expand language support, allow users to choose their preferred reading level, and improve document handling for longer and more complex files. We’d also like to turn PlainSpeak into a browser extension or API so it can be used directly where people encounter confusing documents rather than requiring them to leave their workflow. Long-term, the goal is to make understanding critical information the default, not the exception.
Built With
- css
- elevenlabs
- express.js
- google-gemini
- html
- javascript
- json
- node.js
- python
- react
- vite


Log in or sign up for Devpost to join the conversation.