-
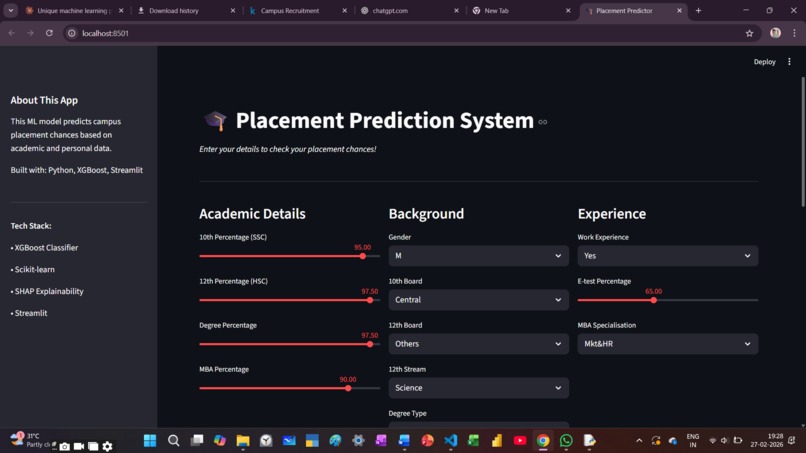
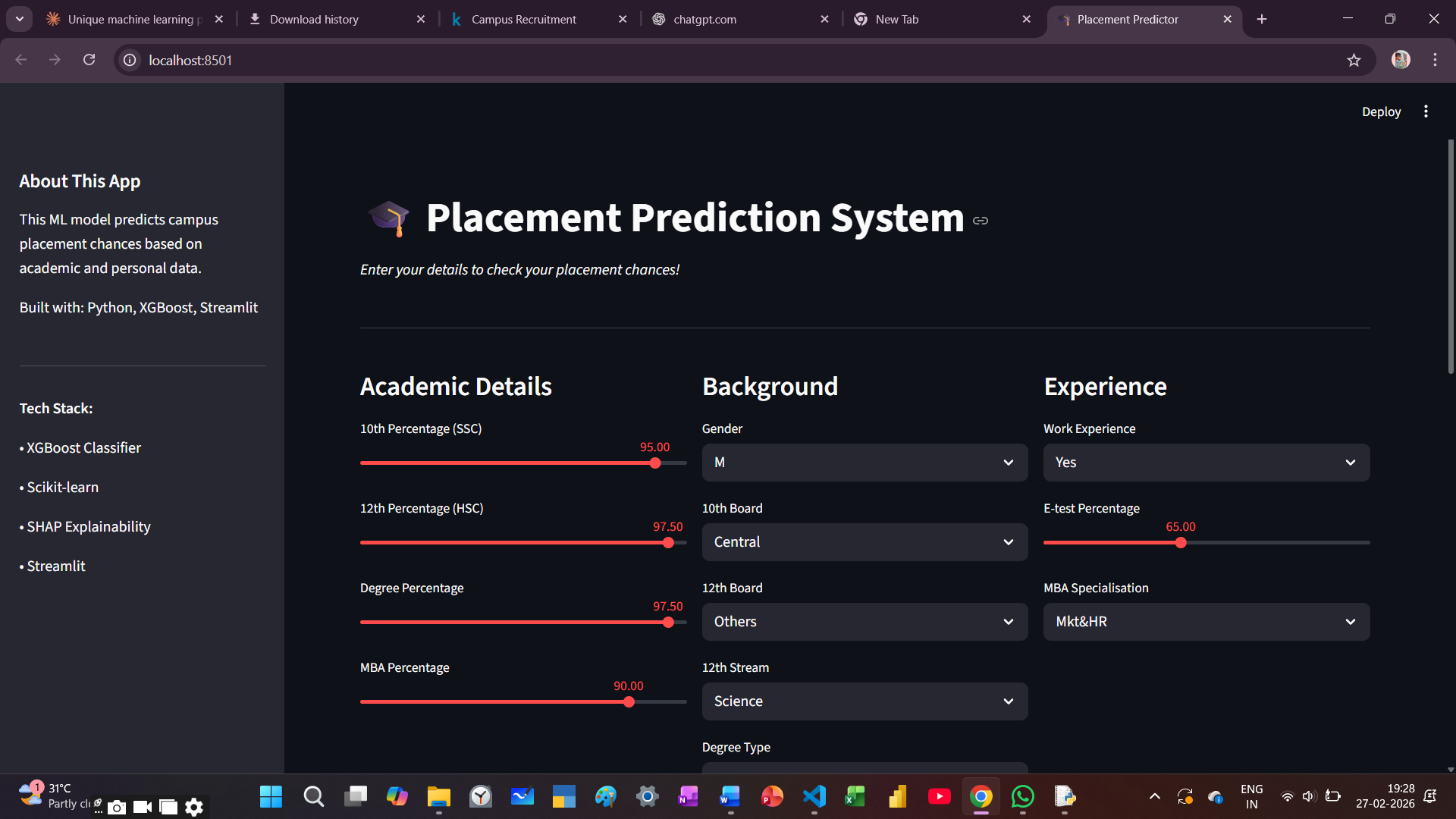
Predicted campus placement chances with 88% accuracy using 4 ML algorithms on 215 student records.
Inspiration
Campus placements are one of the most high-stakes moments in a student's academic journey — yet most students enter the process with little clarity on where they actually stand or what's holding them back. I wanted to build something that didn't just predict an outcome, but gave students actionable, personalized insight into their placement readiness. The idea was simple: turn raw academic and skill data into a transparent, explainable decision — the kind a placement advisor would give, backed by machine learning.
How I Built It
The pipeline was built end-to-end in Python, starting with a dataset of 215 student records covering academic scores, skills, internship experience, and placement outcomes.
Data & Modeling
- Preprocessed and feature-engineered the dataset using
pandasandscikit-learn(encoding, scaling, train-test split). - Trained and benchmarked 4 ML algorithms: Logistic Regression, Decision Tree, SVM, and XGBoost.
- XGBoost achieved the highest accuracy at 88%, and was selected as the production model.
Explainability
- Integrated SHAP (SHapley Additive exPlanations) to generate feature importance scores per prediction.
- This allowed the app to surface why a student was predicted placed or not — e.g., "Your CGPA and communication skill score are the strongest positive factors."
Deployment
- Built an interactive frontend using Streamlit, enabling real-time predictions from user inputs.
- Deployed the live dashboard on Streamlit Cloud, accessible without any local setup.
Challenges I Faced
1. Making explainability work in real-time
SHAP computations can be expensive. Integrating SHAP waterfall plots into a live Streamlit UI without significant lag required careful management of model artifacts and caching (@st.cache_resource).
2. Class imbalance in the dataset The dataset had a skewed placement ratio. Naive accuracy metrics were misleading — I had to evaluate models using precision, recall, and F1-score to ensure the model wasn't just predicting the majority class.
3. Choosing the right model for interpretability vs. accuracy SVM performed competitively, but SHAP support is natively richer for tree-based models. Choosing XGBoost was a deliberate trade-off to preserve both performance and explainability.
What I Learned
- How to move beyond black-box ML and build transparent, user-facing AI using SHAP.
- The practical gap between notebook accuracy and a production-ready deployed app — especially around serialization, UI state, and caching.
- That explainability is a feature, not an afterthought — users trust and engage far more with a system that shows its reasoning.
- End-to-end ownership of an ML project: data → model → deployment → user feedback loop.
Built With
- numpy
- pandas
- python
- scikit-learn
- shap
- streamlit
- xgboost


Log in or sign up for Devpost to join the conversation.