-
-

Poster
-
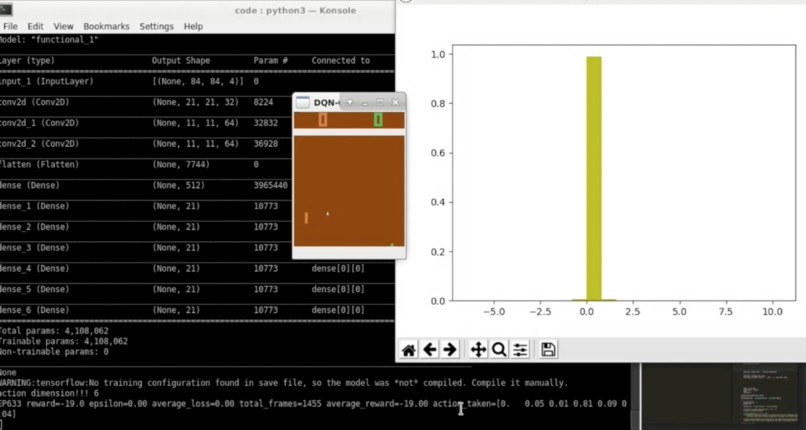
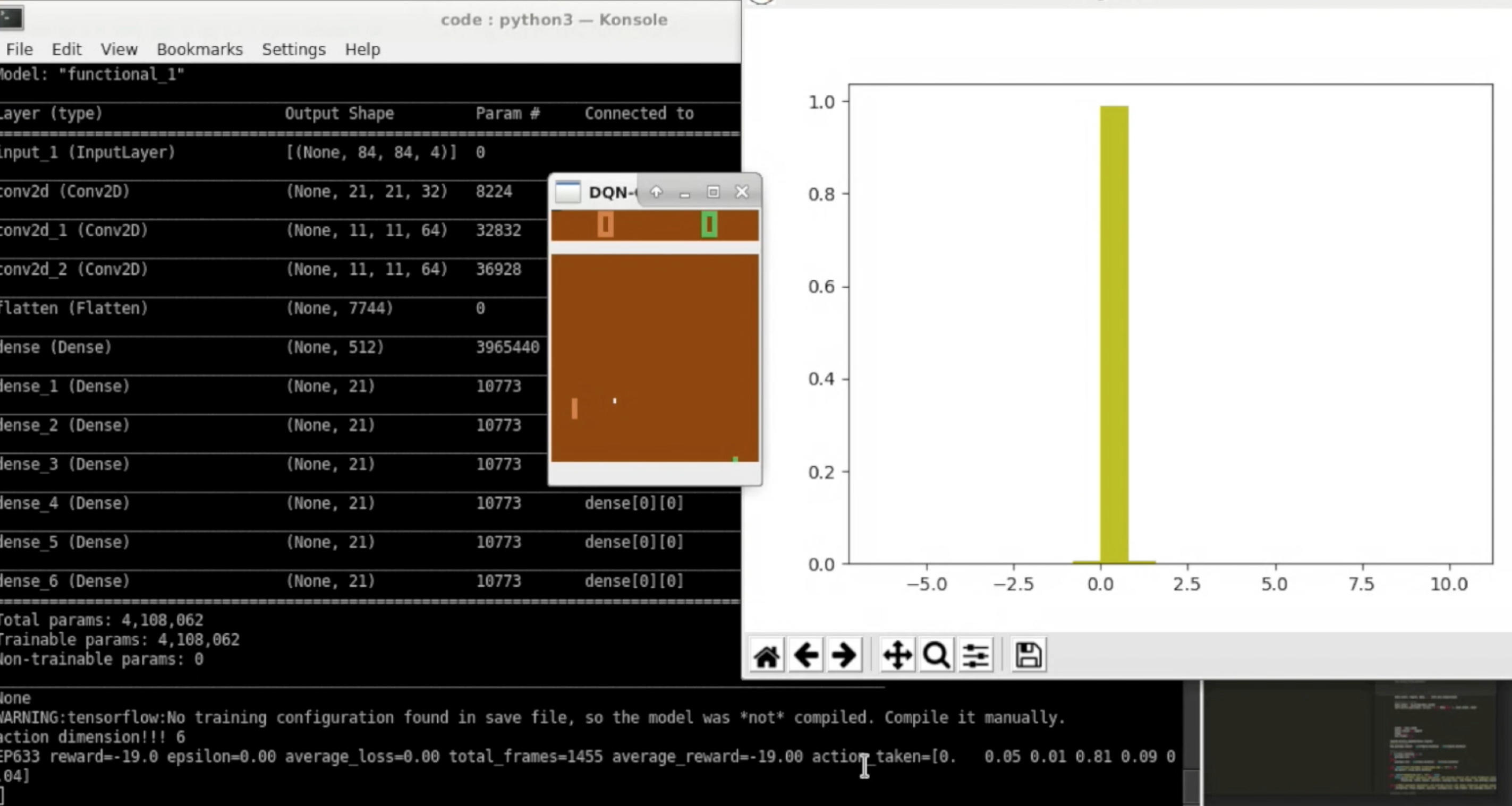
Pong
-
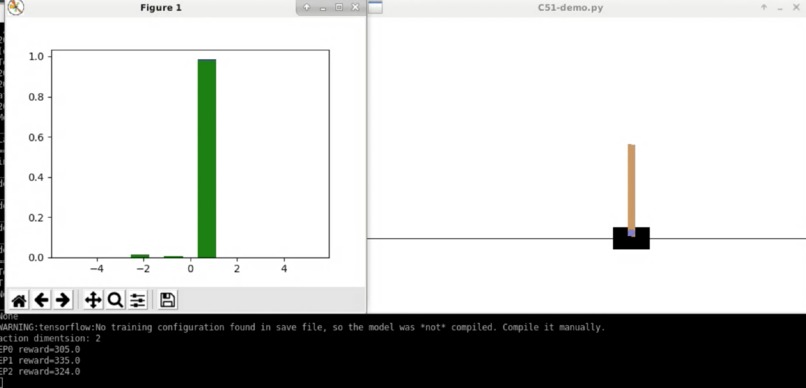
Cartpole

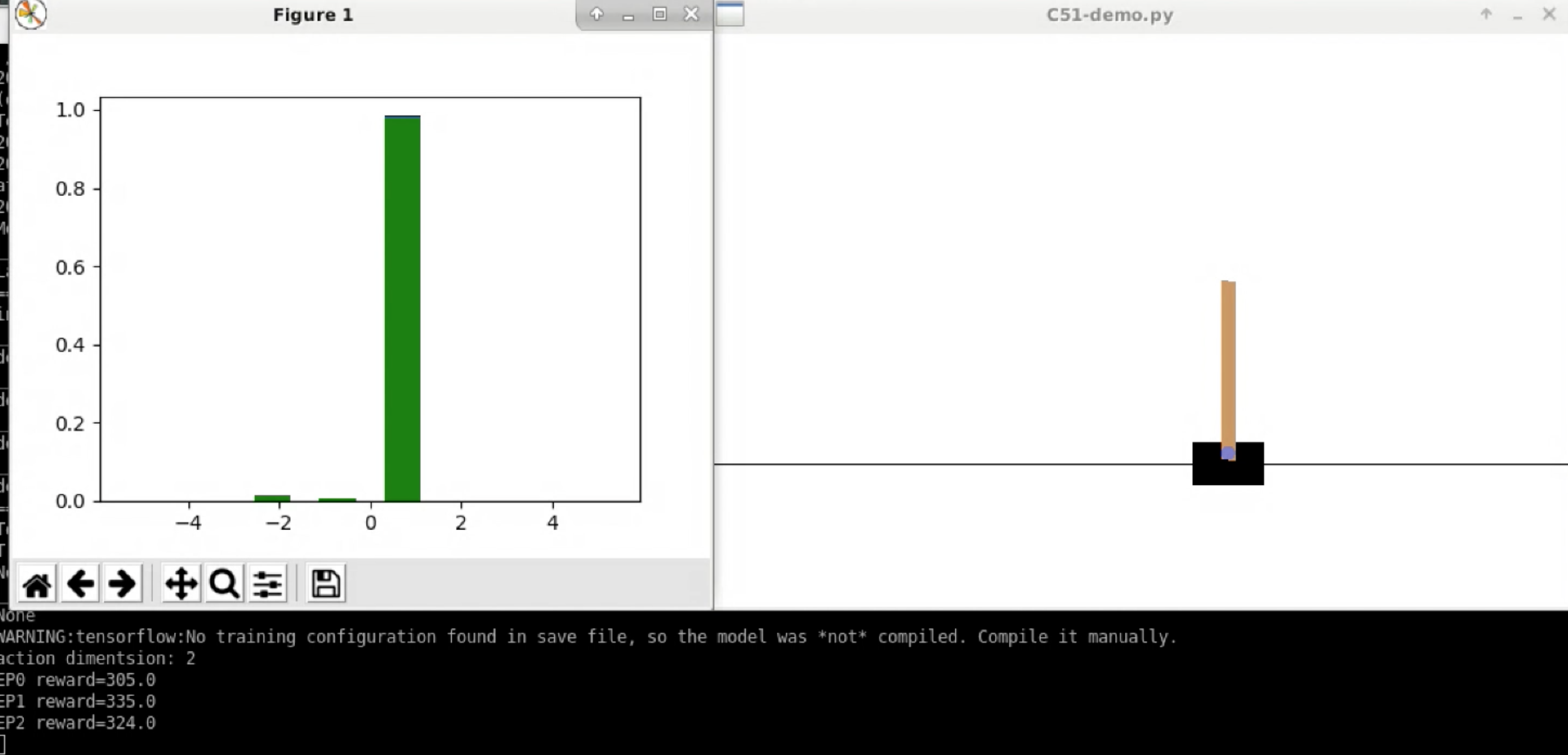
Value Distribution Evolution Demo (Pong)
Inspiration
The outline that you submit/write-up to Devpost should contain the following:
Title: Reinforcement Learning with Value Distributions
Team
Simon Shnagqun Yu, Hanyu Liu, Bowen He, Eric Hsiung
Introduction:
We aim to re-implement and extend learning and utilizing probabilistic value distributions in reinforcement learning for learning policies, based on work from Bellmare et al:
Existing Paper: Bellemare 2017
We plan to implement the core distributional algorithm, and then compare performance to other reinforcement learning methods utilizing the OpenAI Gym environment.
Related Work:
Fully Parameterized Quantile Function for Distributional RL
Bellemare builds upon the standard Bellman equation and RL literature by creating defining a distributional version of the Bellman operator. Whereas the Bellman operator indicates convergence of Q-values based on expectation, the distributional version indicates a convergence to a family of optimal distributions for values.
Data Sources
We will utilize a selection of OpenAI Gym RL Environments.
Methodology
The original paper utilizes Minh DQN with Bellmare distributional loss function. We may initially utilize Minh DQN, and then deviate to experiment with other architectures.
Additionally, the current algorithm is a discretized algorithm. We might consider exploring if it is possible to extend or approximate it to a continous space. For instance, while the "distributional" portion of is a set algorithm that generates weights in an actor-critic loss function, it might interesting to replace the algorithm with a neural network to observe what changes might occur.
TODO: Explain how the value distributions work (diagram, etc)
Metrics
We will consider standard RL and the value RL distribution method to be a baseline. We will compare results from various experimental architectures to these standards.
A success constitutes an experimental architecture training correctly to convergence, even if it might not perform as well.
The training and testing environments will be chosen from OpenAI Gym.
Accuracy does not apply; rather having an agent maximize its reward quickly as possible is an important metric to track in RL.
In the Bellmare paper, the authors found that the distributional model (C51), where 51 refers to approximately the probability distribution with 51 discrete bin states, outperformed other models.
Base goals: Implement Value Distribution and a standard RL model. Target Goals: Experimental and tweak distributional architectures Stretch Goals: Experimental architecture exceeds Bellmare and other RL performance on tasks.
Ethics
Choose 2 of the following bullet points to discuss; not all questions will be relevant to all projects so try to pick questions where there’s interesting engagement with your project. (Remember that there’s not necessarily an ethical/unethical binary; rather, we want to encourage you to think critically about your problem setup.)
Why is Deep Learning a good approach to this problem?
In games, environment, rules, and operations are relatively complicated. In order to achieve the goal of letting the machine play the game, we need to make it perceive the screen display or information of the game, understand the rules of the game, and be able to find a way to correctly lead to higher scores in practice. The deep convolutional neural network in deep learning is very suitable for processing visual information and can solve the problem of visual information perception. Deep neural networks can be used to fit most functions, including the rules of the game. Deep reinforcement learning has the ability to learn all kinds of behaviors needed to play a game well. Compared with other methods, deep learning methods can also reduce the dependence on a large number of manually set action rules. Based on the above reasons, we believe that deep learning is a very good choice for machines to play games.
How are you planning to quantify or measure error or success? What implications does your quantification have?
In the field of games, we usually use a score to mark the achievements and progress of game players. The reinforcement learning model we use should be able to describe the actual situation corresponding to the score, and make the correct response and action to maximize the score. Under normal circumstances, the game will set a rule and a total score. Whenever the player completes a certain behavior, the player's score will increase. Of course, there are many complicated situations. In some games, the game will have multiple scores. And even in some cases these scores will be used and reduced. In this case, we need to set some importance, upper and lower bound limits for these different scores. For example, some games have the value of money, and players can choose to consume a certain amount of money in exchange for other scores or changes the game content. We need to set a more refined reinforcement learning reward function to accomplish these things. Some games do not have a clear and fixed score to indicate the current state of the game, or the state is not clear before the end of the game, such as chess. For this, we need to use other deep learning methods to describe the state. In general, for the games we are studying, we can use a single score to quantify our success and failure. The higher the single score, the better and more successful our method is.
Division of labor
Briefly outline who will be responsible for which part(s) of the project.
Reflection:
Introduction:
See above
Challenges:
The most difficult part of this project has been finding enough time to get started on the project, organizing and communicating with group members, and ensuring everyone understands the paper and theory. For some group members, the paper was not particularly difficult to understand.
However, there were some nuances in the paper that required a bit of discussion. For instance, we had a discussion on exactly what it meant for a value probability distribution to evolve in time as states and actions are taken. In particular, it was not immediately obvious how the categorical distribution algorithm pseudo-code was performing projections from a continuous space onto a discretized approximation. Now however, we have an intuitive understanding of how an "update" of the distribution Bellman operator works on an approximated value distribution: if an initial histogram (approximated distribution) has a finite set of bins and is bounded over a certain domain, translations and scaling of the histogram will alter the effective bin size (result after applying the distributional Bellman operator). In order to map (project) the resulting histogram back onto the same space as the original histogram, the counts or density in the new histogram bins need to be put back into the original histogram bins. We will stick a diagram in the methodology to explain the concept more clearly.
The implementation and architecture so far does not seem to be particularly difficult. However, we expect that making experimental modifications to the base architecture and getting to work properly in an RL context will be difficult to pull off.
We've been discussing what would be a good way to define the maximum and minimum possible values in the distribution (some thoughts include reading the max value from the environment, or taking timesteps * max_value). We also discussed how the gradient should propagate through terms in the loss function, since the loss function is in actor-critic form (though the critic seems to mostly just be a weight).
Insights:
No concrete results yet. It might be interesting to perform an experiment where the critic includes another approximator for the Q-value, and perhaps experiment with other approximation methods other than discretization.
Plan:
We've been discussing what Gym environment to utilize for testing and training. We plan to have a base model completed by 11/23. We will perform a comparison with an implementation of DQN.
Built With
- gym
- python
- tensorflow
- tf-agents





Log in or sign up for Devpost to join the conversation.