Title: Music To Picture
Who: Griffin Ares, Amari Brooks
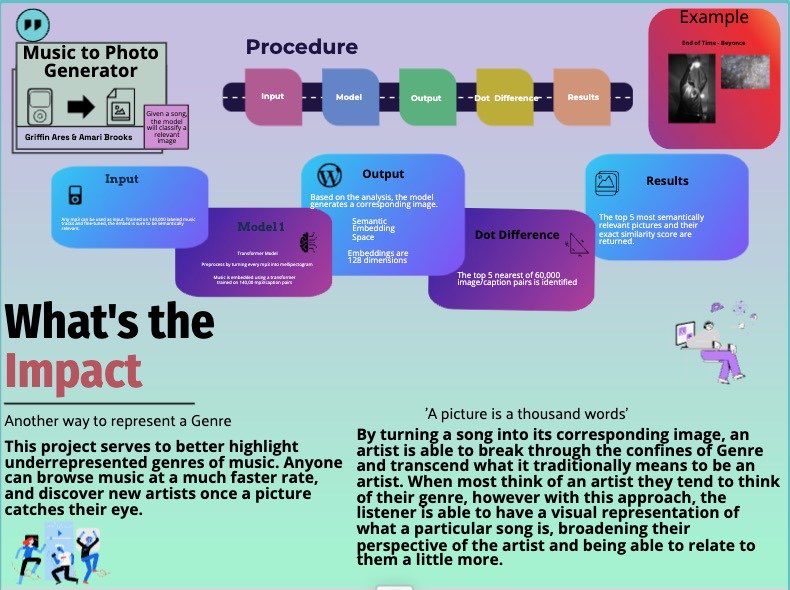
Introduction: Team OK Computers is creating a classification model that will take in an audio track, output a sentence, and link to DALL-E for sonic-inspired art relevant to the track. This may be purely abstract, or maybe specifically a relevant album cover for the audio.
Data: Our song embedding model is trained on a human-labelled dataset from Wasabi. The dataset is 140,000 song/caption parings large. Our embedding space is created from a dataset of 60,000 picture/caption parings from a public google research dataset.
Metrics: As our final output is art, the only requirement is subjective coolness and relevancy. We can test the intermediate output from the music classification model to text, however.
Ethics: Why is Deep Learning a good approach to this problem? This problem is incredibly abstract, from music analysis to art creation. Deep Learning is the only realistic way to approach it.
How are you planning to quantify or measure error or success? What implications does your quantification have? Majority approval. As our output is very subjective in terms of accuracy, getting majority approval for coolness/relevancy from a large enough sample size is how we will measure error/success.
Contribution: Griffin - Data collection, model 1 and help with model 2 Amari - Presentation and Model 2

Log in or sign up for Devpost to join the conversation.