Inspiration
Millions of researchers, students, and professionals worldwide sift through endless papers, tables, and videos every day.
Think about the typical research process: you open one PDF, search for specific information, save where you found it, compare it with other documents, and repeat. It’s tedious, manual, and time-consuming. Current tools often fall short, leaving researchers buried in inefficiency and repetitive work.
That’s where Lexis steps in. By leveraging Streamlit, Mistral LLM, Snowflake Cortex, and a hybrid retrieval pipeline, we empower researchers to focus on breakthroughs instead of busywork.
How it works
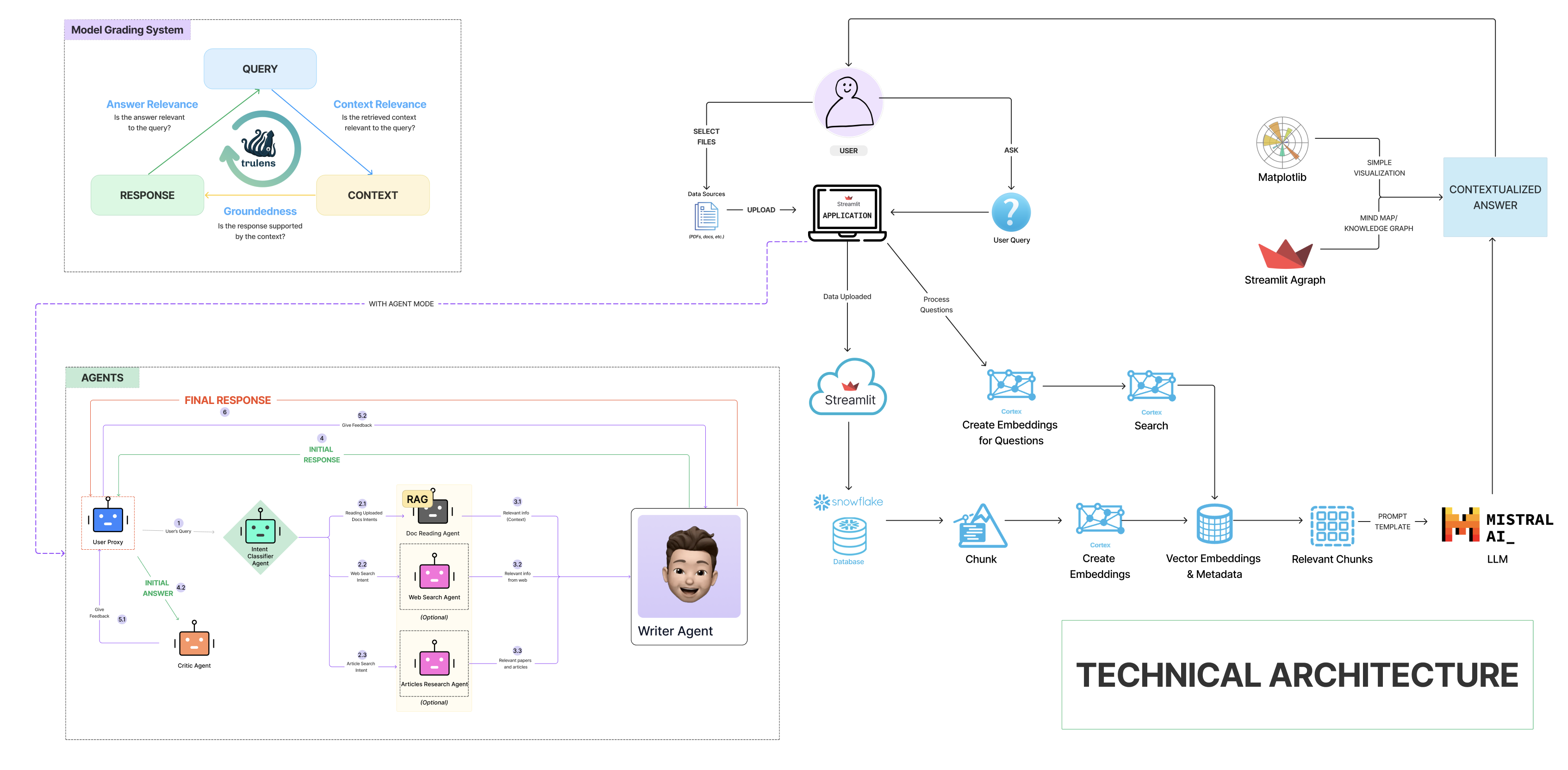
First, researchers upload documents, datasets, or video links via an intuitive UI built with Streamlit. Files are securely stored in a Snowflake database, where they are automatically chunked and converted into vector embeddings using Snowflake Cortex. The hybrid retrieval pipeline then combines traditional full-text search with advanced AI-driven vector-based methods, re-ranking results to ensure the most accurate and relevant insights.
If the agent mode is used, along with the retrieved documents, Lexis performs reasoning-based web searches for real-time, relevant information or articles for user queries. This additional insights and context helped Lexis address even the most complex, multi-step queries. For example, our agent can understand a user’s request, retrieve relevant articles on the specified topic, and provide concise summaries along with their sources.
Then, with multi-modal question answering capabilities, powered by Mistral LLM, Lexis generates nuanced and accurate responses, summaries, visualizations (I promise you our visualizations are better than GPT! Thank you Streamlit Agraph), and citations. Through this pipeline, it helps researchers explore complex connections and present insights with clarity and precision.
How we built it
At its core is the Agentic RAG, powered by the nested chat flow of Autogen agents, which enables Lexis to handle a wide range of tasks and queries effectively. Specialized agents work together to process user intents, search for relevant uploaded documents or documents on the web, and generate refined responses, ensuring every interaction is grounded and relevant.
Process Documents with Semantic Splitting
- Embedding Model: Use the Snowflake Arctic Embed model to embed text documents into a vector representation.
- Splitter: Process the cleaned documents into semantically meaningful chunks using SemanticSplitterNodeParser.
Agentic RAG with Multi-Agents Pipeline
- User Proxy: Initial query handling
- Intent Classifier: A semantic router to identify user's intent, whether reading uploaded documents, searching for papers, searching for real-time data, or general query.
- Specialized Agents:
- Document Reading Agent: extracts and retrieves relevant information from uploaded documents using LAYOUT mode, embeddings, and search algorithms.
- Web Search Agent: fetches real-time data via search engine APIs or scraping, with result ranking for relevance.
- Articles Research Agent: searches academic databases for papers relevant to the query.
- Writer Agent: aggregates context from all agents and generates a cohesive, factually accurate response. Prioritizes data based on agent reliability and relevance.
- Critic Agent: Response refinement based on user's query, retrieved context information, writer agent's response to reduce hallucinations from LLMs.
Evaluation and Tracking for LLM Experiments
Utilizing Trulens for tracking and evaluating performance across three core metrics:
- Answer Relevance: Ensures responses are coherent, accurate, and reasoned.
- Context Relevance: Validates the quality of retrieved information, ensuring it aligns with the query.
- Groundedness: Functions as hallucination detection, verifying all responses against source documents.
Our development process included creating multiple RAG versions:
- Agent-Based Version: Combines multiple AI agents (Document Reading, Article Research, Web Search) with Trulens's context filter guardrails. This approach enhanced context quality, reduced hallucinations, and balanced latency.
- Agent-Free Version: Offers simplicity with low latency by retrieving relevant context solely from uploaded documents. Although limited in accessing real-time data, it maintains high context relevance.
Our agent_v3's iterative refinements, including Trulens context filtering guardrails at threshold 0.5 and enhanced processing through multiple AI agents, make it a more robust and efficient RAG system compared to Agent_v1. It achieves better groundedness and higher answer quality, thus reducing hallucinations.
Future plans
While Lexis is already revolutionizing research workflows, we have big plans for the future. We’re working on introducing real-time collaboration tools for teams, fully integrating multi-modal AI for text, audio, and video analysis, and enhancing visualization tools for creating knowledge maps and presenting insights.
Accomplishments that we're proud of
We threw away our original idea last minute and had only 3 days to work on this project. We slept for 3 hours a day and ran on coffee.
What we learned
Snowflake is amazing!!!
Built With
- autogen
- python
- snowflake
- streamlit
- trulens



Log in or sign up for Devpost to join the conversation.