-
-

Logo
-
Website
-
Website
-
Website
-
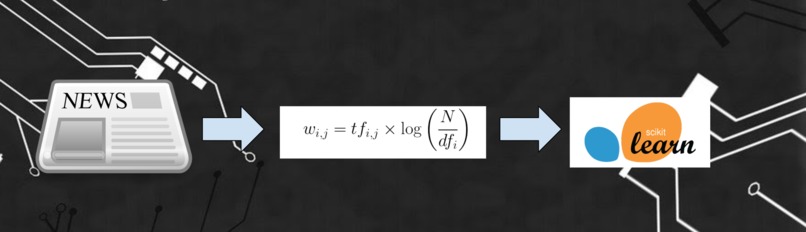
News > Vectorizer > Passive Aggressive Model

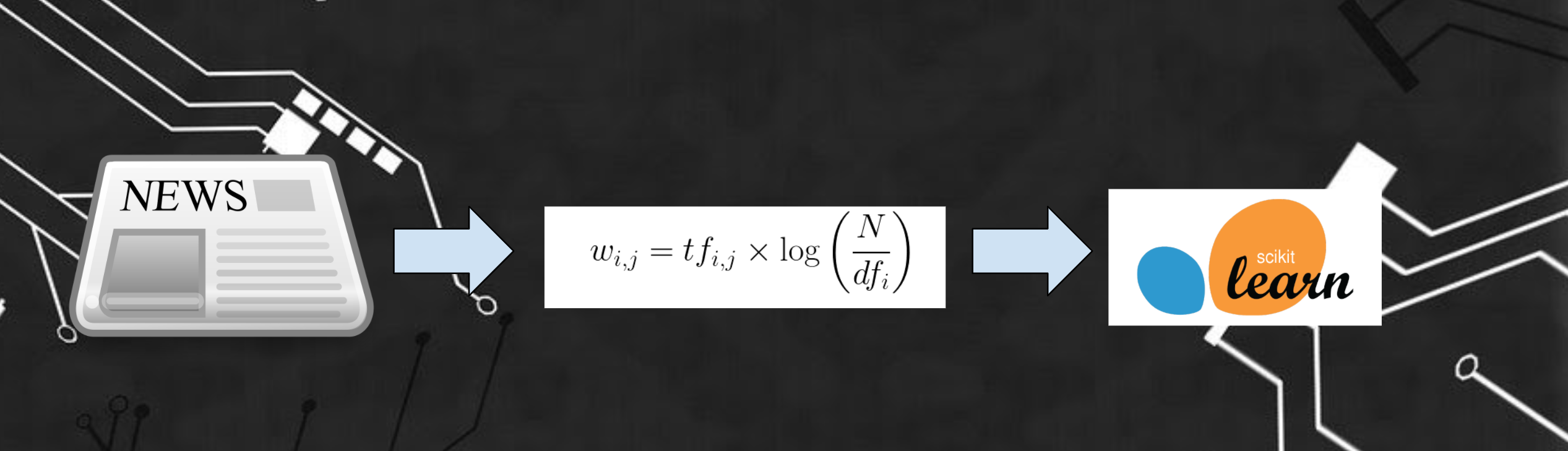
Inspiration
The pandemic took the world by storm. It pillaged our healthcare systems and caused millions of deaths. But if there were one thing to take out of it, it would be the effect of fake and biased news on the population.
This effect is massive. Because of unreliable news, people have used dangerous alternative medicine, ignored the recommendations by health experts, and refused vaccines. Not only is fake news dangerous to the health of the country, but also dangerous to the mental health of the people reading it. A study by the American Psychological Association concluded that 66% of Americans are stressed about the future of the United States. A major contributor to these stress levels is the increasing consumption of news, especially those that are fake/biased. Therapist Steve Stosny says:
“For many people, continual alerts from news sources, blogs and social media, and alternative facts feel like missile explosions in a siege without end”.
Enter pobide.Ai, a solution for automatic detection of disinformation and political bias in news using advanced machine learning and natural language processing techniques.
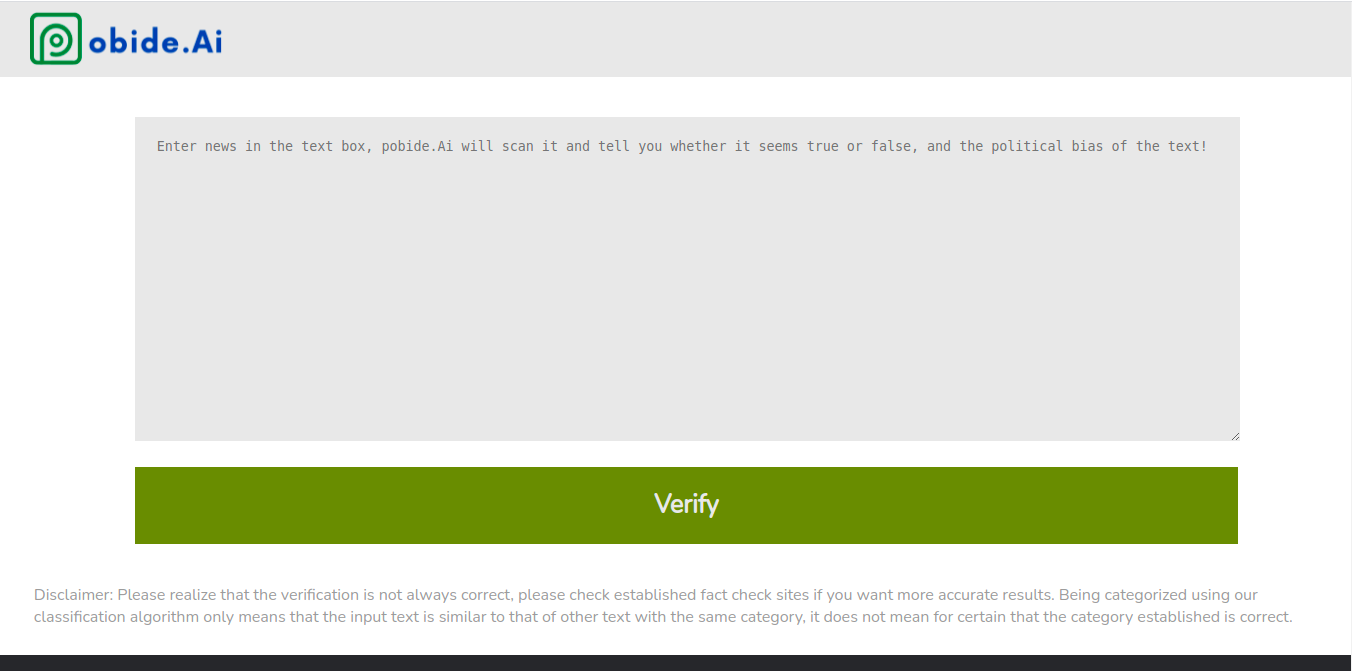
What it does
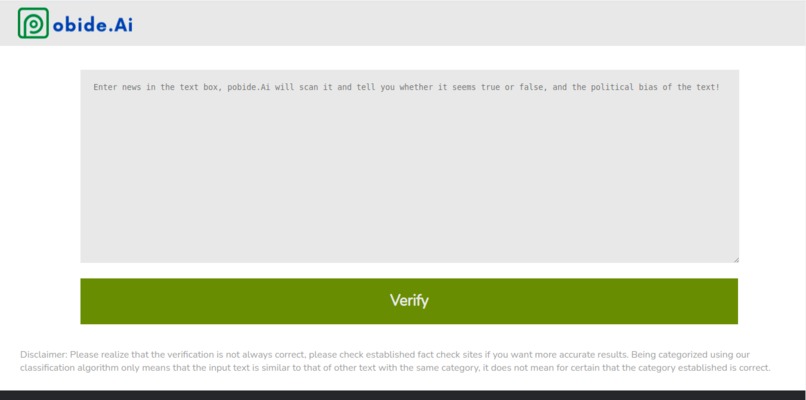
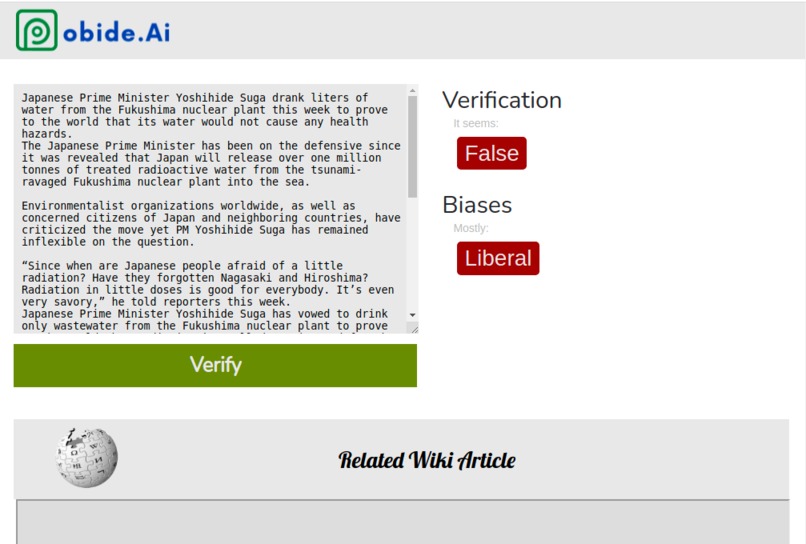
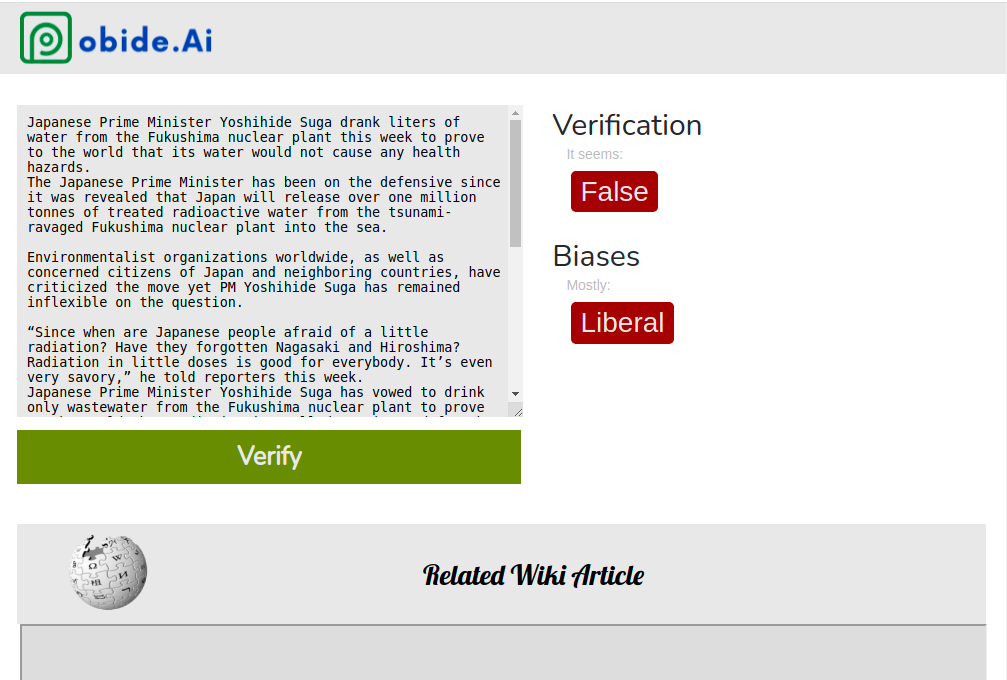
pobide.Ai allows the user to paste any piece of text into its website. The users then presses "VERIFY", and pobide.Ai will return the political bias of the text, and whether the text is fake.
How we built it
To detect fake news, pobide.Ai uses the Sci-kit Learn’s Passive-Aggressive Classifier; for political bias, pobide.Ai uses a fine-tuned version of Google’s Bidirectional Encoder Representations from Transformers (BERT) that we linked to a long short term memory (LSTM) layer attached to a standard fully connected (FC) layer. Through a vast amount of testing, these models had the best accuracy on test datasets.
As one may see, there are two parts to this problem, each requiring a detector, a Disinformation, and Political Bias Detector.
The Disinformation Detector uses a TF-IDF Vectorizer to transform the dataset into a way that can be processed by the model, or a sparse matrix of TF-IDF features. The model and vectorizer are trained and saved onto pickled files. The model and vectorizer can be loaded and can predict text inputs in split-second time, with a 96% accuracy.
The Political Biases Classifier uses Google's BERT, followed by an LSTM layer, and some simple neural network layers. The layers following BERT classify the data. This classifier consumes the output hidden state tensors from BERT — using them to predict whether the input statement is Liberal, Conservative, or Neutral. The pre-trained BERT model used is 'bert-base-uncased', and transformers.AutoTokenizer is used to convert the input data to the form which can be processed by the pre-trained BERT model.
Challenges we ran into
There are not a lot of publicly available political bias datasets on the web. Our team spent a good chunk of time finding and preparing datasets for usage. After a substantial amount of time and research, we found the Ideological Book Corpus, a dataset with 4062 individual labeled sentences. Though we found a dataset, it was only for labeled sentences, and the decision to scale that to document-level bias detection was expedient.
Another challenge was the accuracy of the Disinformation Detector. Though it regularly achieved >99% accuracy for predicting fake news on the test dataset, testing on real data had much lower accuracy. The team eventually found the problem within the dataset, each factual news site had a label with the news site written on it, and the same news site was in almost all of the factual news examples, and nearly none of the fake news sources. By guessing based on the tag on the factual news sources, you would achieve a >99% accuracy. We tried to stop this problem by removing all of the tags, but the dataset still did not work very well. Then, as a last resort, we changed the dataset to a smaller but more accurate one.
The political bias detector also had its fair share of problems. We first tried to implement a similar approach to the disinformation detector but found that it had low accuracy of 48-56%. Then, we implemented a Multi-layer Perceptron Classifier with fastText word embeddings, but the result was not much higher. Other word embeddings like Word2Vec and GloVe also had similar accuracy. (word embeddings implemented with sci-kit learn via Zeugma) We concluded that to detect political bias, we needed something deeply bidirectional, and Google’s BERT was a fit. In order to classify data, we added an LSTM layer attached to an FC layer, which yielded a 95.5% accuracy.
Accomplishments that we're proud of
We're proud of the massive amount of work and dedication put into this project. This was our first time creating and deploying a machine learning system with multiple models. This was also our first time using a fine-tuned BERT.
What's next for PoBiDe.ai
We have big goals. We first want to speed up our model. Currently, our architecture uses BERT, a very large model. We could use a smaller model to speed up the model to an industry-level speed.
In addition, we only trained our model on 4096 sentences. Though this is a good amount of samples, we are unsure of how our training on strictly sentences will scale to full-length articles. Based on some small amount of testing, we do not think that the sentence training approach will be good enough for a production ready app.
In the future, we want to use a faster model, and also train our model on full-length articles instead of just sentences.
Credits for Video
The first two articles were from the satirical news site "The World News Daily Report". The third site (conservative) was from Blaze Media (right). The fourth site was from Fox10 News (right-center). The last site (liberal) was from CNN (left).
We verified each of these news sources' political bias using AdFontesMedia and MediaBiasFactCheck.
Built With
- bert
- canva
- django
- figma
- keras
- python
- scikit-learn
- tensorflow






Log in or sign up for Devpost to join the conversation.