-
-
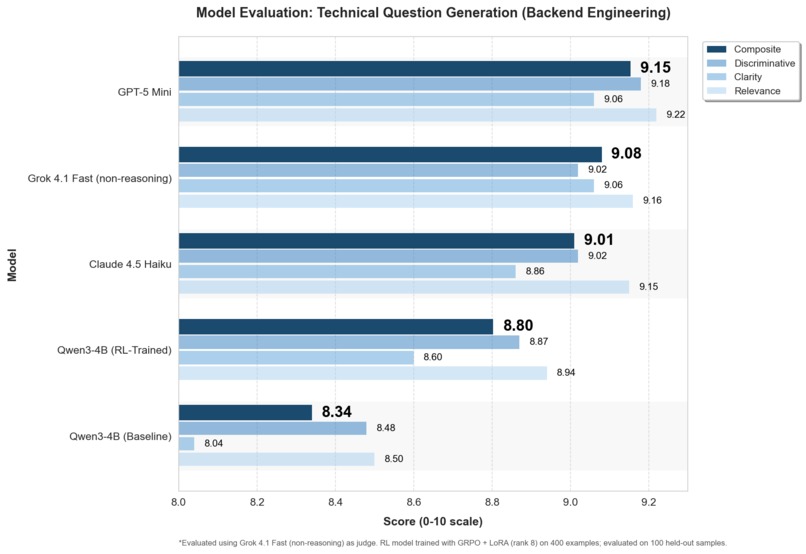
Technical Question Generation Evaluation
-
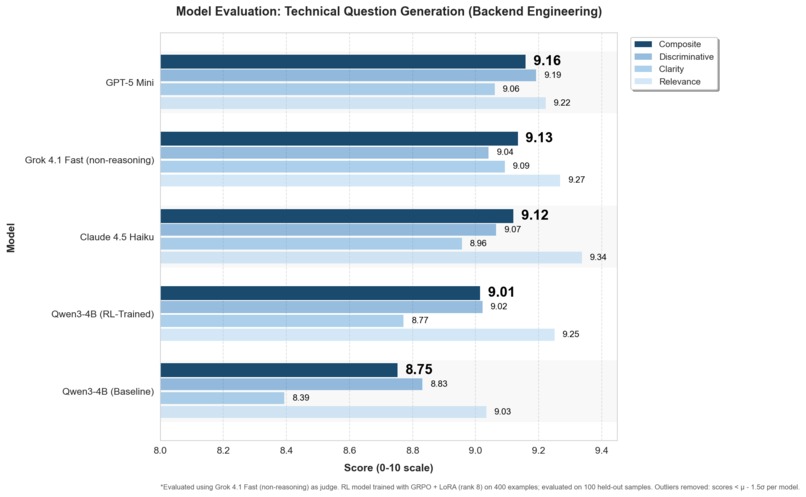
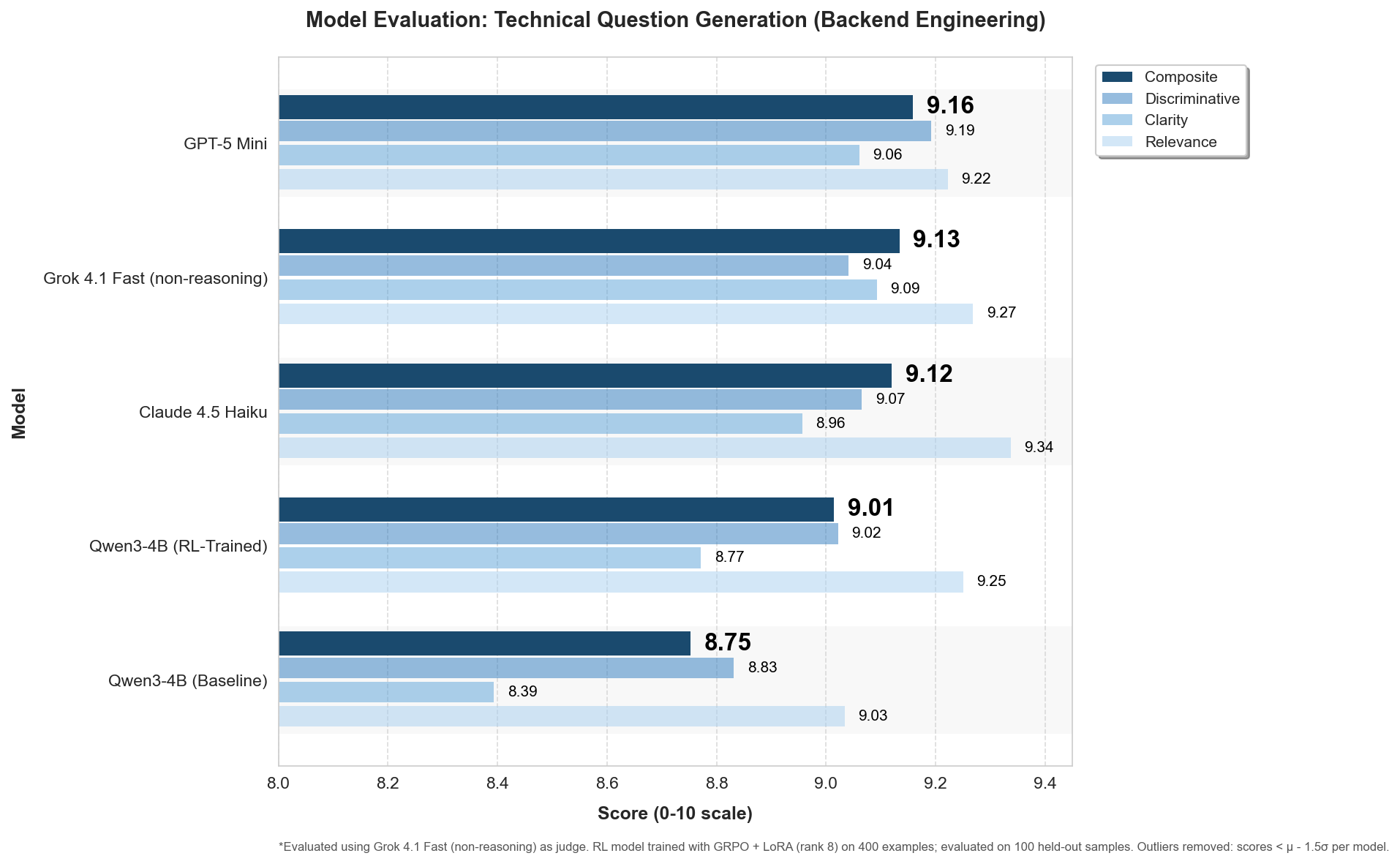
Technical Question Generation Evaluation (Outliers Removed)
-
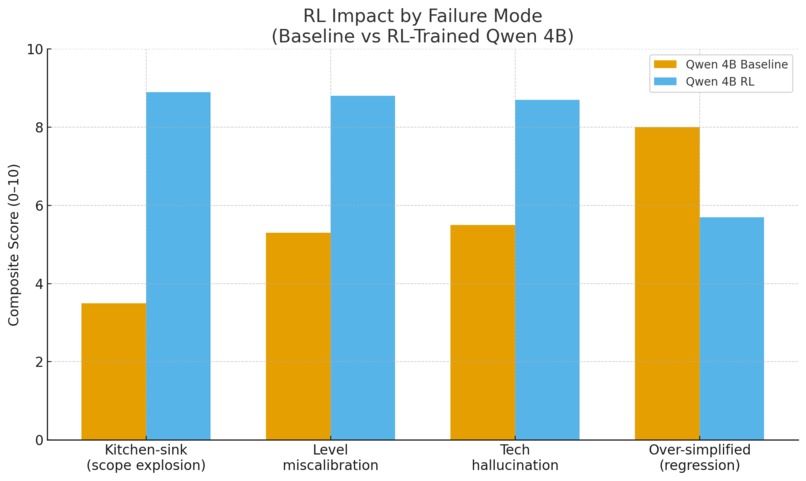
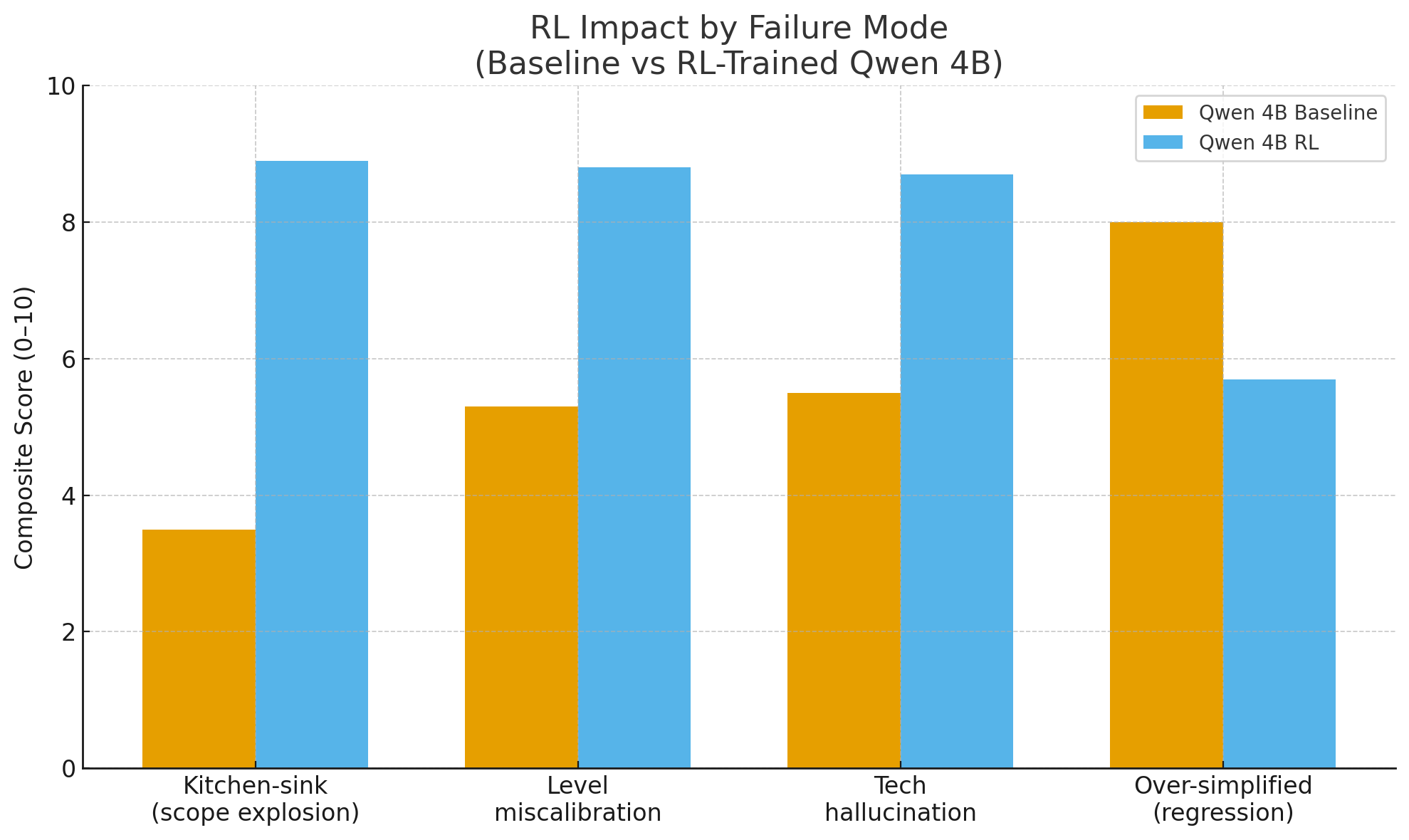
Failure Modalities of RL-finetuned Qwen vs Normal Qwen
Inspiration
Recruitment is a labor-intensive task. Technical interviews stand out as the most labor-intensive of all. Engineers would rather be shipping new software but are stuck in long interviews with candidates that passed generic screening. And when they're not in an interview, they have to draft new technical questions.
What it does
We introduce two products: a RL fine-tuned model used to generate technical interview questions and an interview software that conducts coding exercises with a live AI interviewer that can read, test, and provide hints with code alongside a replay feature that allows you to view an exact replay of hints provided and code written.
We RL fine-tuned the model using self-play on technical question generation. Evaluating on a held-out test set of 100 Backend Engineering job descriptions, this raises the mean rating significantly (8.34 → 8.80) and slashes variance (σ 1.36 -> 0.80), while frontier models sit around 9.1 with σ≈0.2-0.5. That means the small model can already hit frontier-quality questions, it just does so much less consistently. And RL on small models in technical question generation significantly reduces variance in a larger step-function than correctness.
When you trim per-model outliers (μ−1.5σ), Qwen 4B RL jumps from 8.80→9.01 and nearly overlaps GPT-5 Mini (9.16), while GPT-5 barely moves at all. This shows the long tail of catastrophic generations, not the “typical” case, is what drags small-model averages down, and those catastrophes cluster in niche backend subdomains that are likely underrepresented in pre-training. That makes outlier buckets a novel diagnostic for where the model is out-of-distribution in technical question generation and where to target RL or domain data for maximum gain.
RL for technical question generation almost eliminates kitchen-sink prompts, level miscalibration, and tech hallucinations (e.g., +3–5 points in those buckets) but introduces a smaller “over-simplified” failure mode in niche domains like container security. In other words, it trades unusable problems frequently to sometimes too easy problems, a much safer error profile.
This RL-finetuned LLM technical question generator is extremely useful in the next product: AI live coding interviewer.
The AI interviewer receives a generated problem and introduces it to the user in a classic coding environment. From there, the user can write code and verbally converse with the AI, which proctors the interview and asks the user to justify code choices and explain their reasoning. The AI model stays updated with the latest version of the user's code throughout the session via tool use. The coding environment includes a set of basic tests that the user can run or extend, and the AI itself can use tools such as reading code, adding new tests, and executing them. At the end of each interview, an LLM-as-judge evaluates and highlights performance grounded in hints provided and direct code snippets, an auditable replay of user actions. The user can see how the user’s performance compares to other candidates that have been interviewed and replay the interview.
Link to the RL-finetuned model: https://huggingface.co/ash256/qwen3-4b-question-gen
How we built it
We RL fine-tuned Qwen3-4B using GRPO & LoRA with two training modes: offline RL where a Grok LLM judge automatically scores generated questions on relevance, clarity, and discriminative power, and online RL where human raters provide feedback through a web UI that integrates directly with the training loop. The training data consists of 400 role descriptions (title, level, tech stack, key skills) with the model learning to generate targeted screening questions as output, while 100 held-out roles serve as the test set for evaluation. The reward signal (0-1) is computed from three criteria scores, allowing the model to learn what makes an effective technical screening question through iterative policy optimization.
The live AI interviewing system is built on Grok's live audio agent API, with the agent prompted using a structured context that includes the problem statement, candidate information (role applied for, experience level, resume highlights), expected solution approaches with scoring rubrics, and behavioral guidance for conducting effective technical screens. The agent leverages native tool use to view code, run tests, and add tests in real-time during the interview, allowing it to dynamically adapt its follow-up questions based on candidate responses, probing deeper on areas of weakness while efficiently moving past demonstrated competencies to maximize signal extraction within the interview time window.
Challenges we ran into
Getting end-to-end RL working in hiring processes is difficult due to ambiguity in evaluation and RL in general is difficult to implement. For this reason, we downscoped aggressively: small model (Qwen3-4B), LoRA adapters, GRPO to skip the critic, LLM-as-judge to sidestep data collection, contextual bandits (single-turn) to simplify the environment, and SkyRL on a rented GPU cluster with batch sizes tuned via linear regression on OOM crash points. As a result we got three evidence-backed theses on RL in technical question generation validated in under 24 hours and our own fully RL-finetuned model with online RL capabilities.
The AI interviewer space is crowded with established players, making differentiation difficult. Many fast models lack strong reasoning capabilities, while models with good reasoning are noticeably too slow for real-time conversation. Grok's live voice API struck a balance where the product first felt natural, enabling real-time tool use during interviews: reading candidate code, running tests, and generating test cases dynamically without disrupting the conversation flow. This agent-driven approach also strengthened our LLM-as-judge evaluation. Because the interviewer actively interacted with the code through tool use, the judge had richer references to actual code changes and test outputs rather than relying solely on conversational context.
Built With
- evals
- grok
- grpo
- lambda-labs
- lora
- online-rl
- rft
- rl
- s2s
- skyrl
- vllm

Log in or sign up for Devpost to join the conversation.