-
-

Our Logo
-
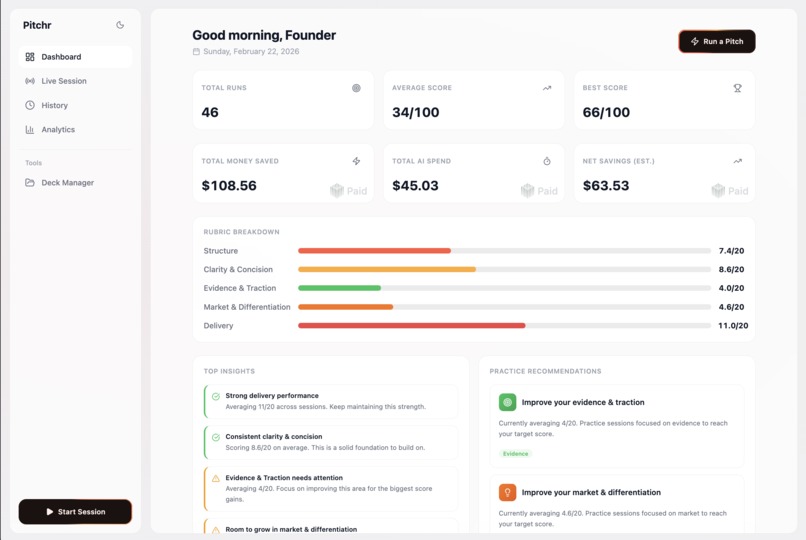
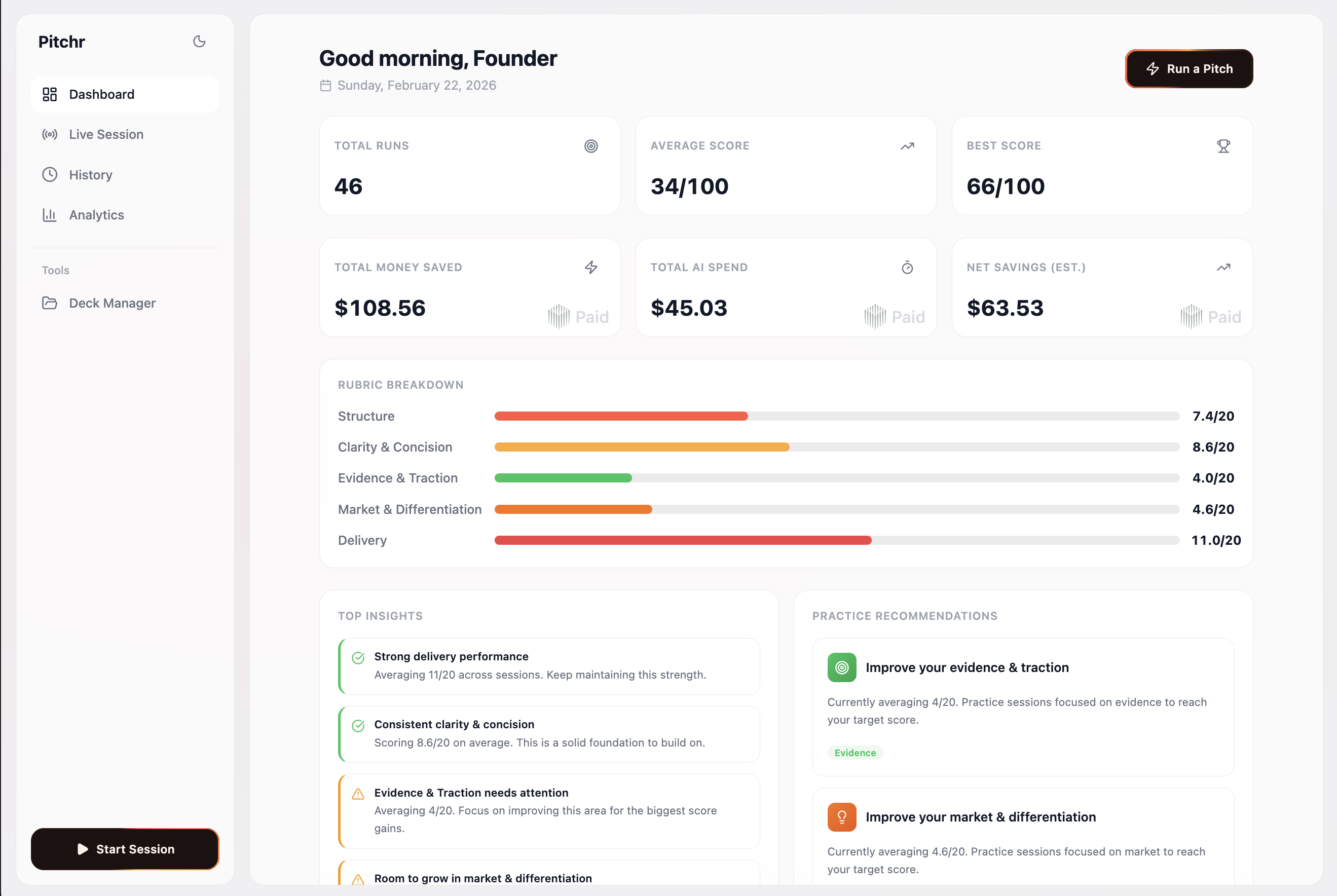
Our main dashboard displaying analytics + Paid AI cost of using our services + money saved assuming 200$/hour pitch coach
-
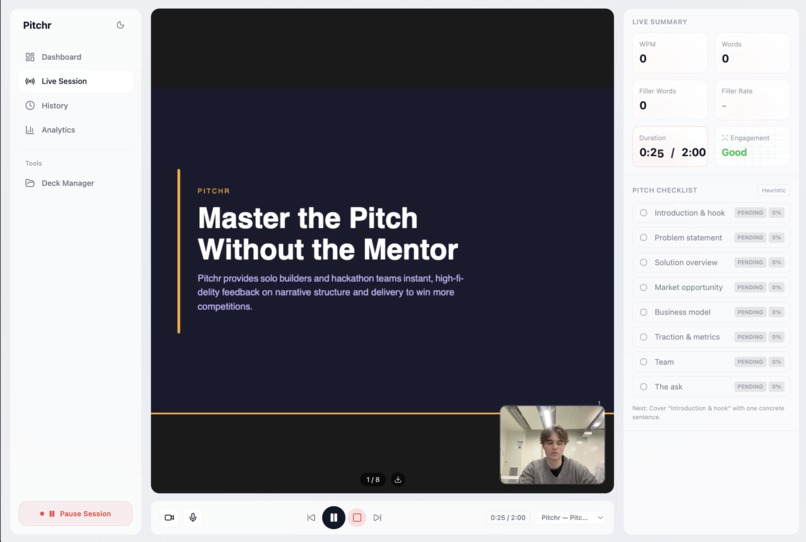
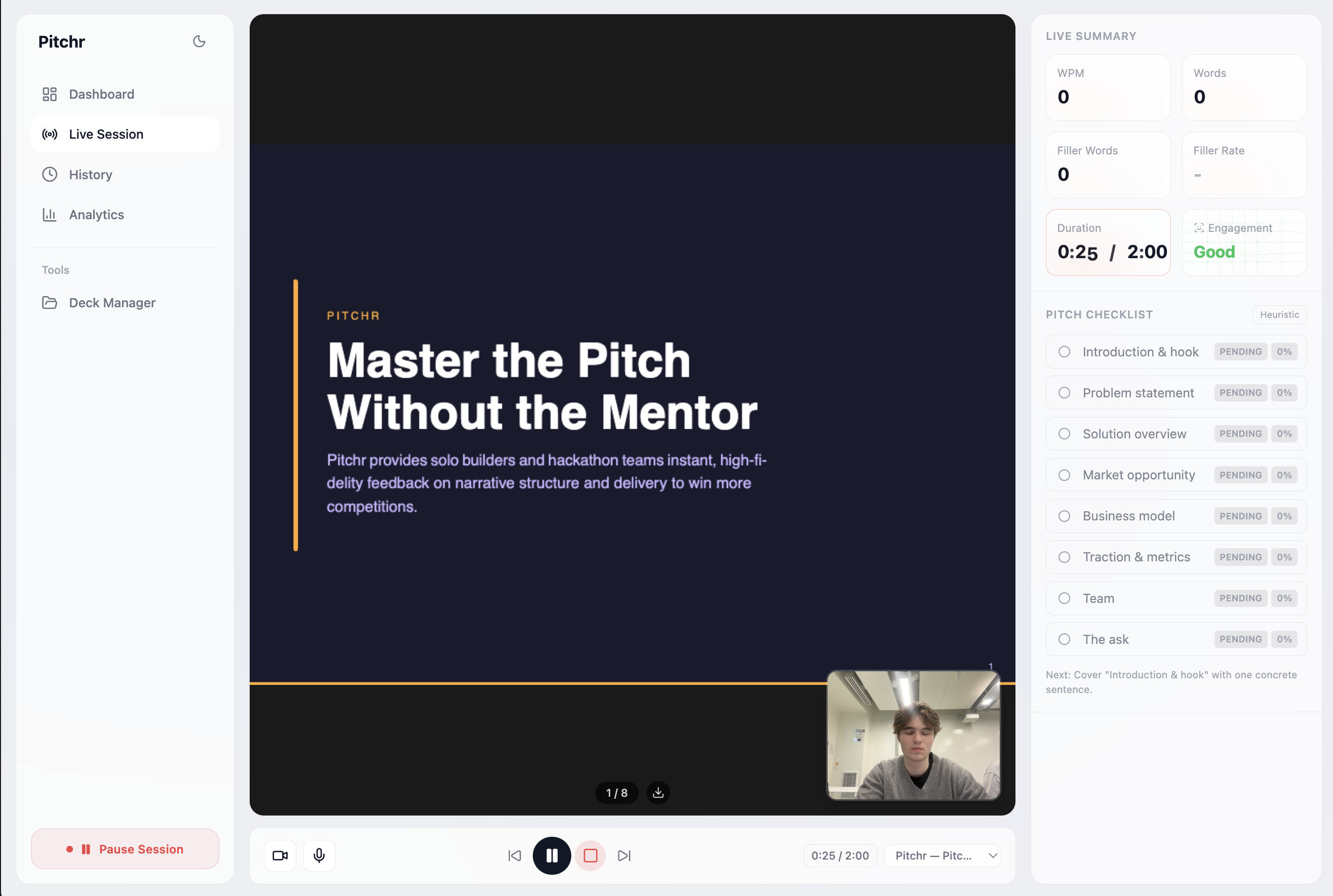
Our live pitch practice tool, using a generated deck, live video camera, gathering live metrics using our ML face detection model
-
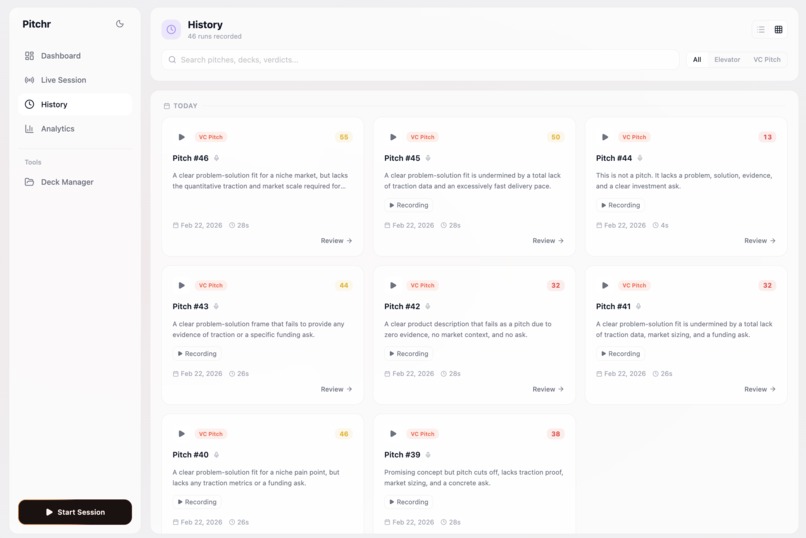
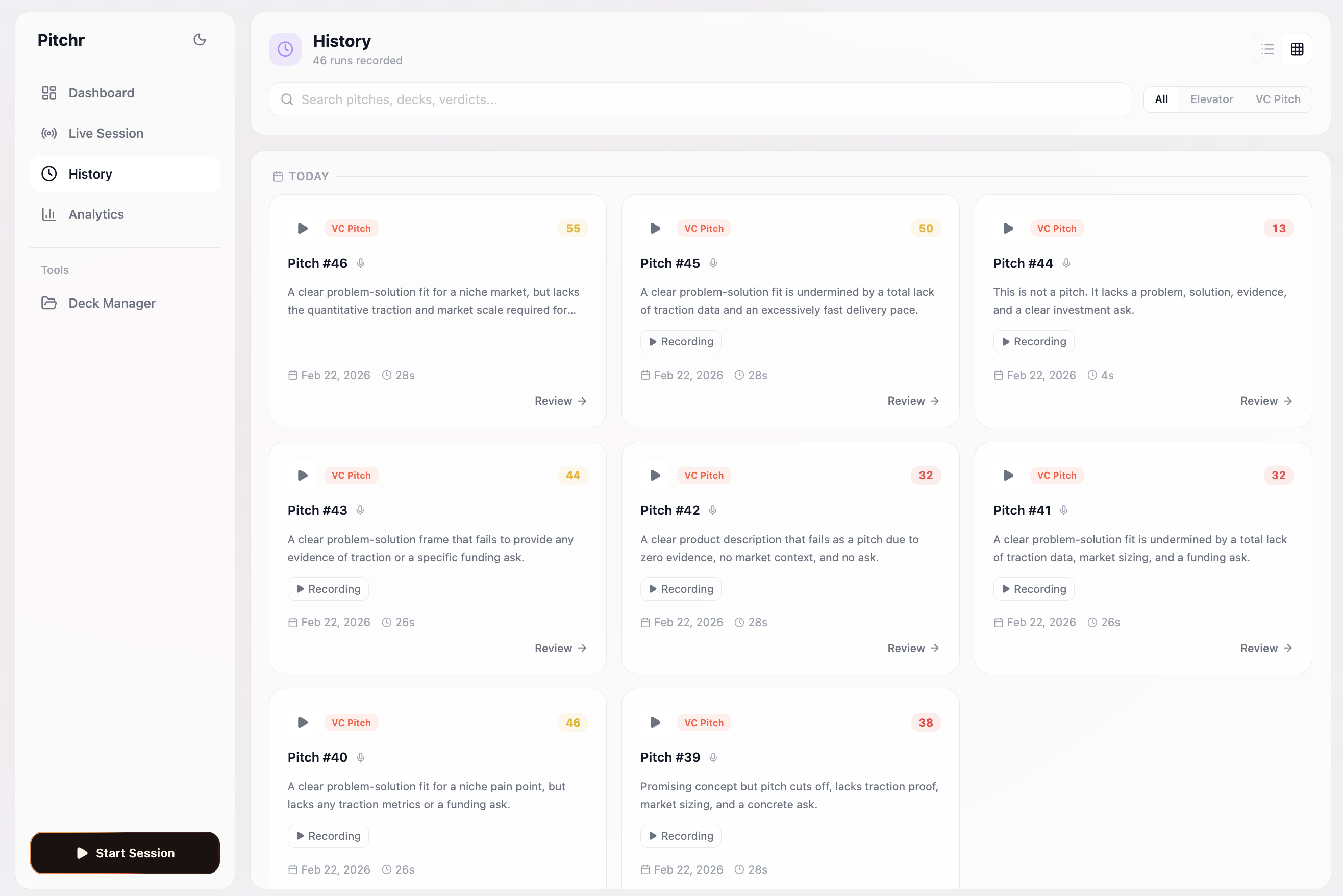
Our history view, to display past sessions and make the recordings + insights accessible to the user
-
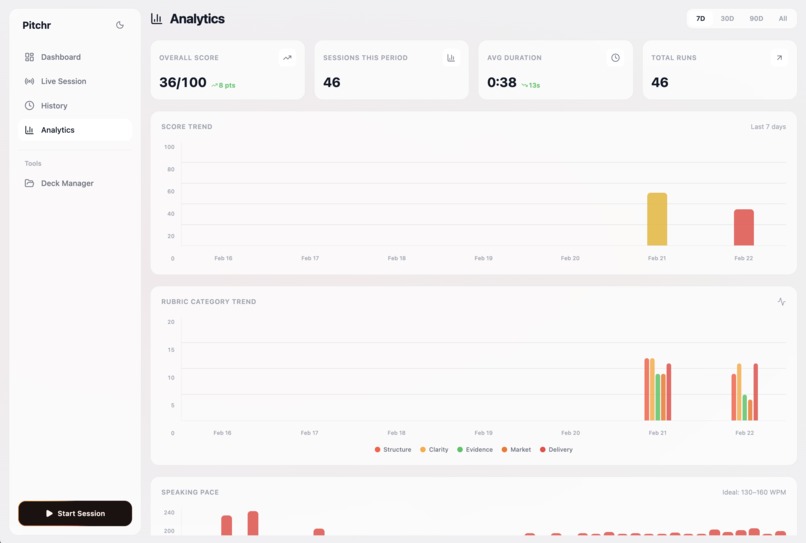
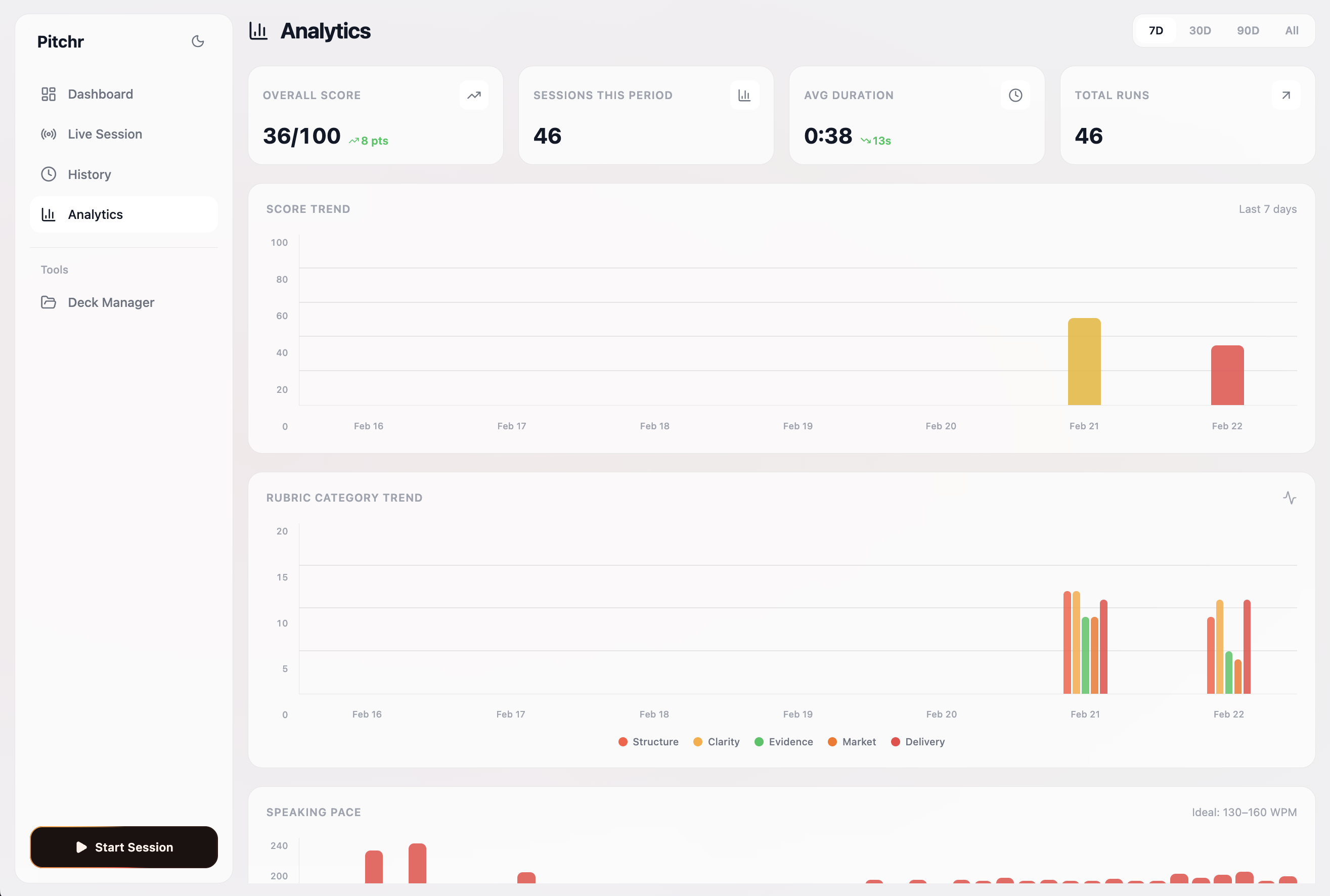
Our analytics view, that summarizes all the key metrics from each session and brings it to a easy overview for improvement
-
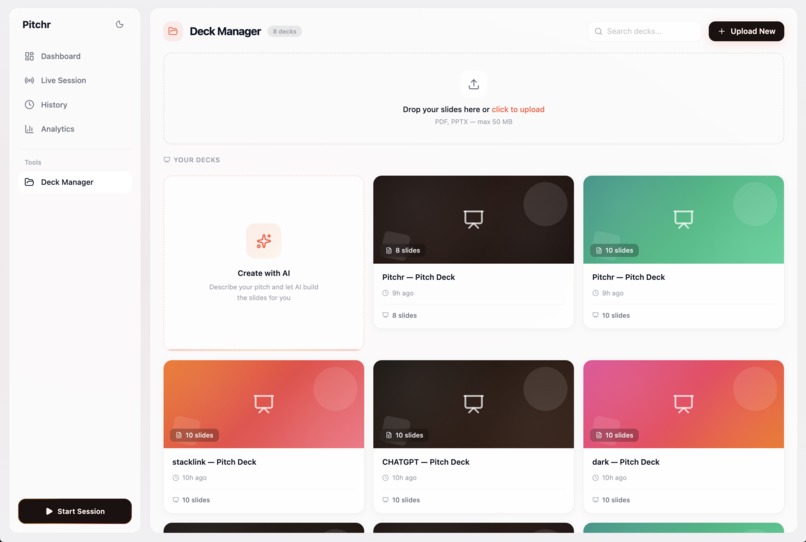
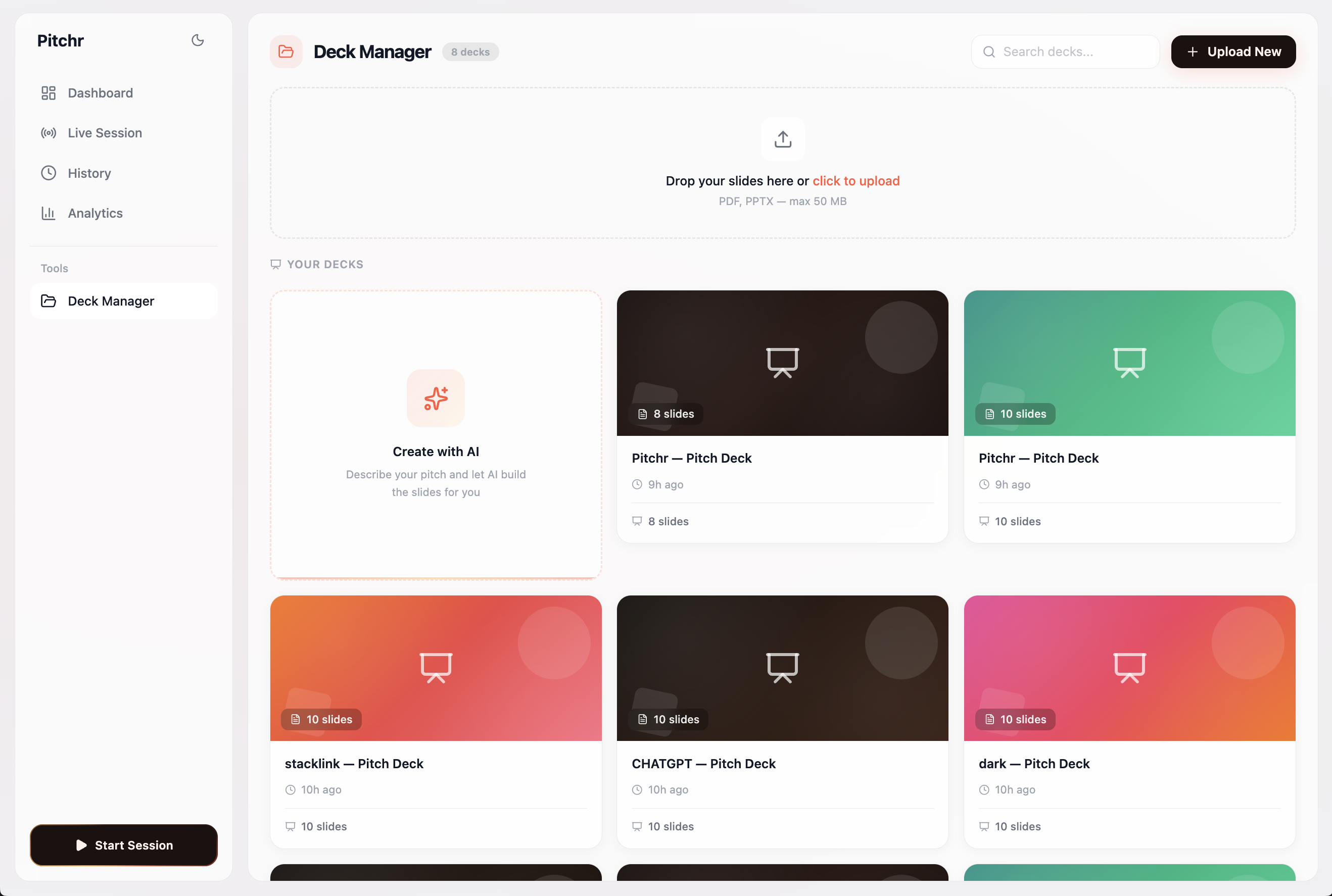
Our AI deck generator tool, using scraped YC winning pitches as templates
-
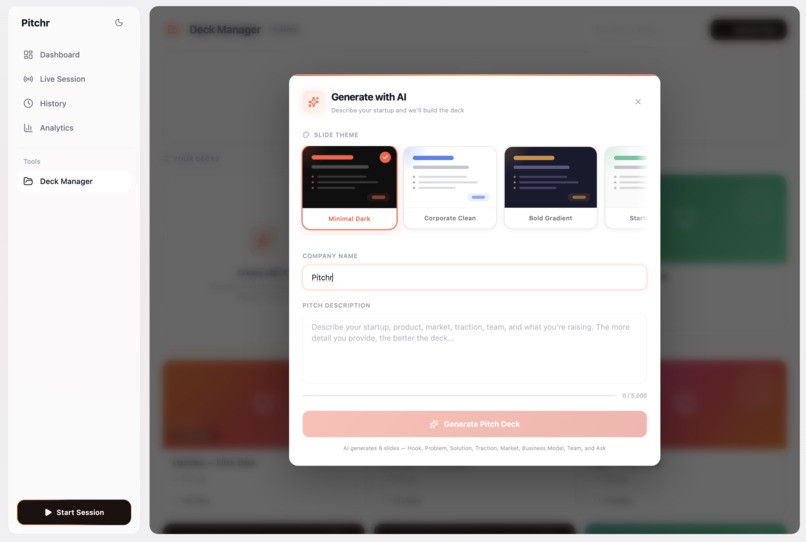
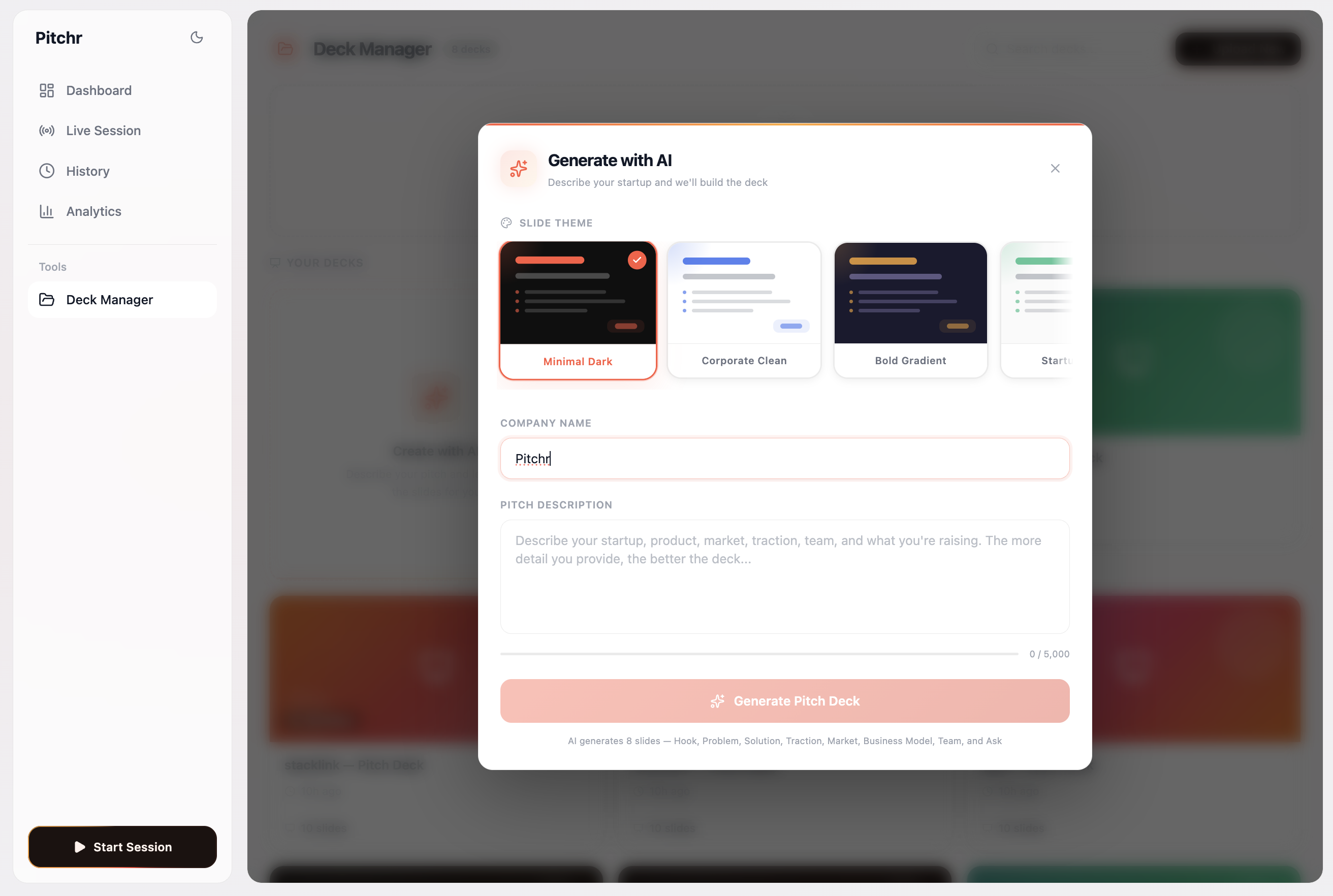
The process of AI deck generation, picking your template, and writing your content
-
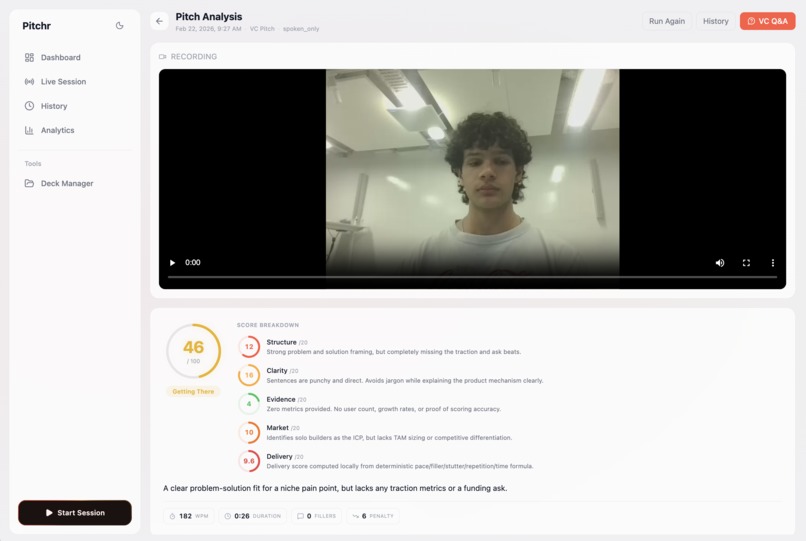
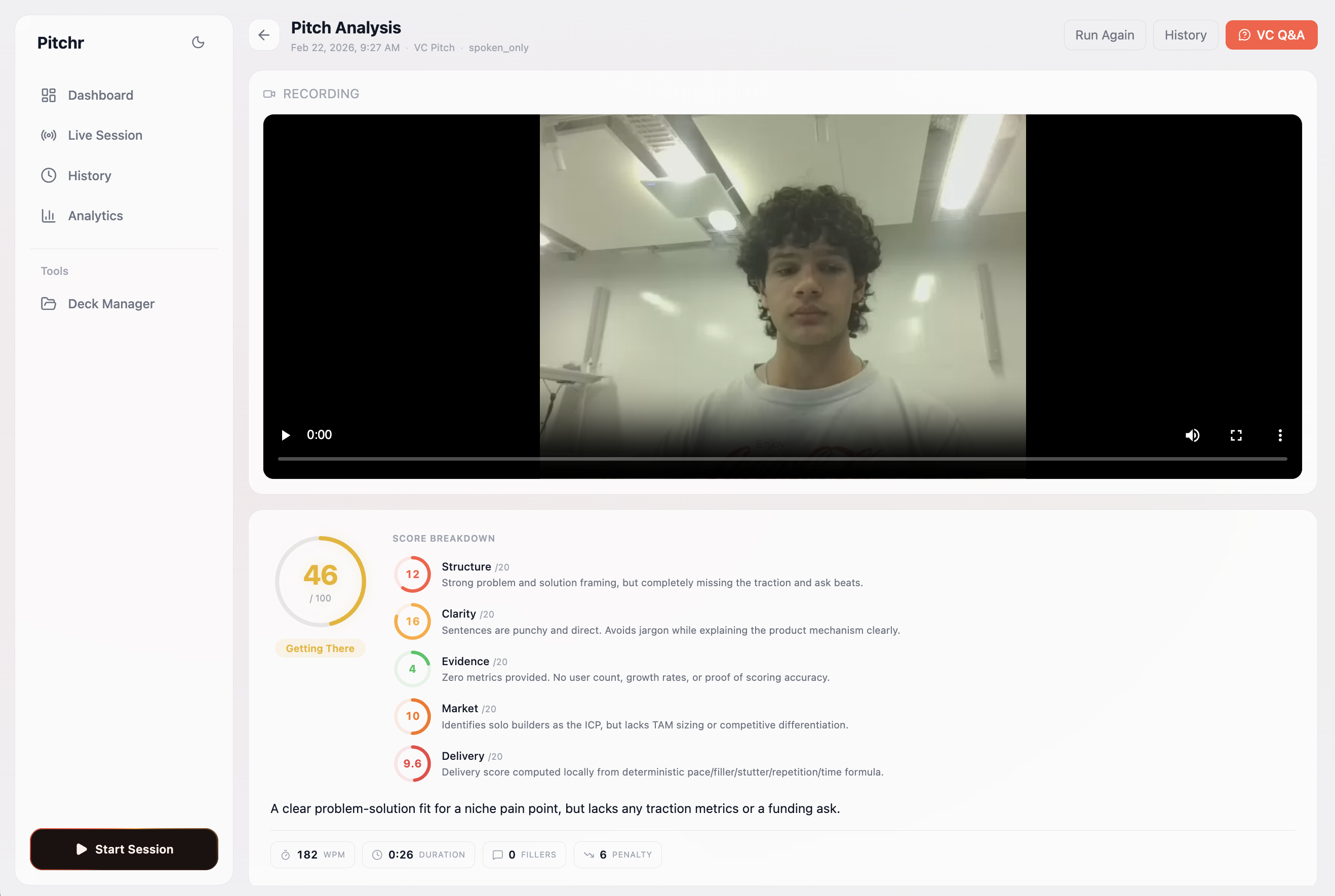
Our session review page, rewatch your pitch, and see our analytics
-
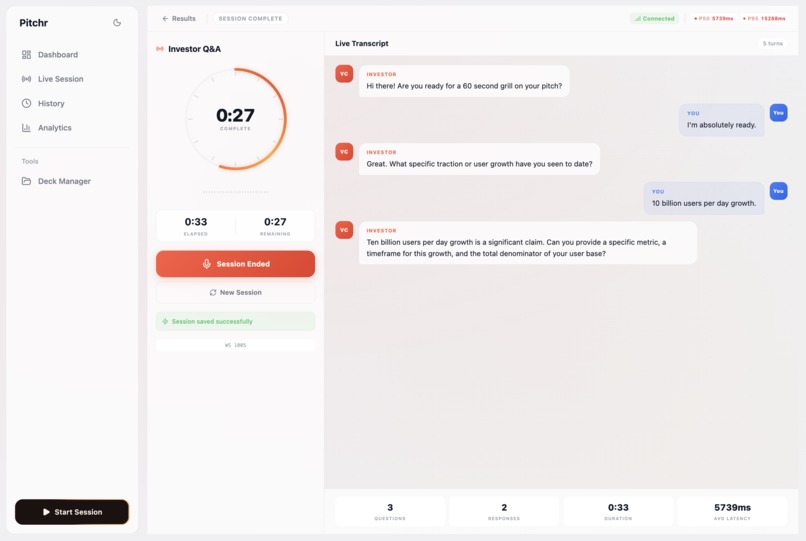
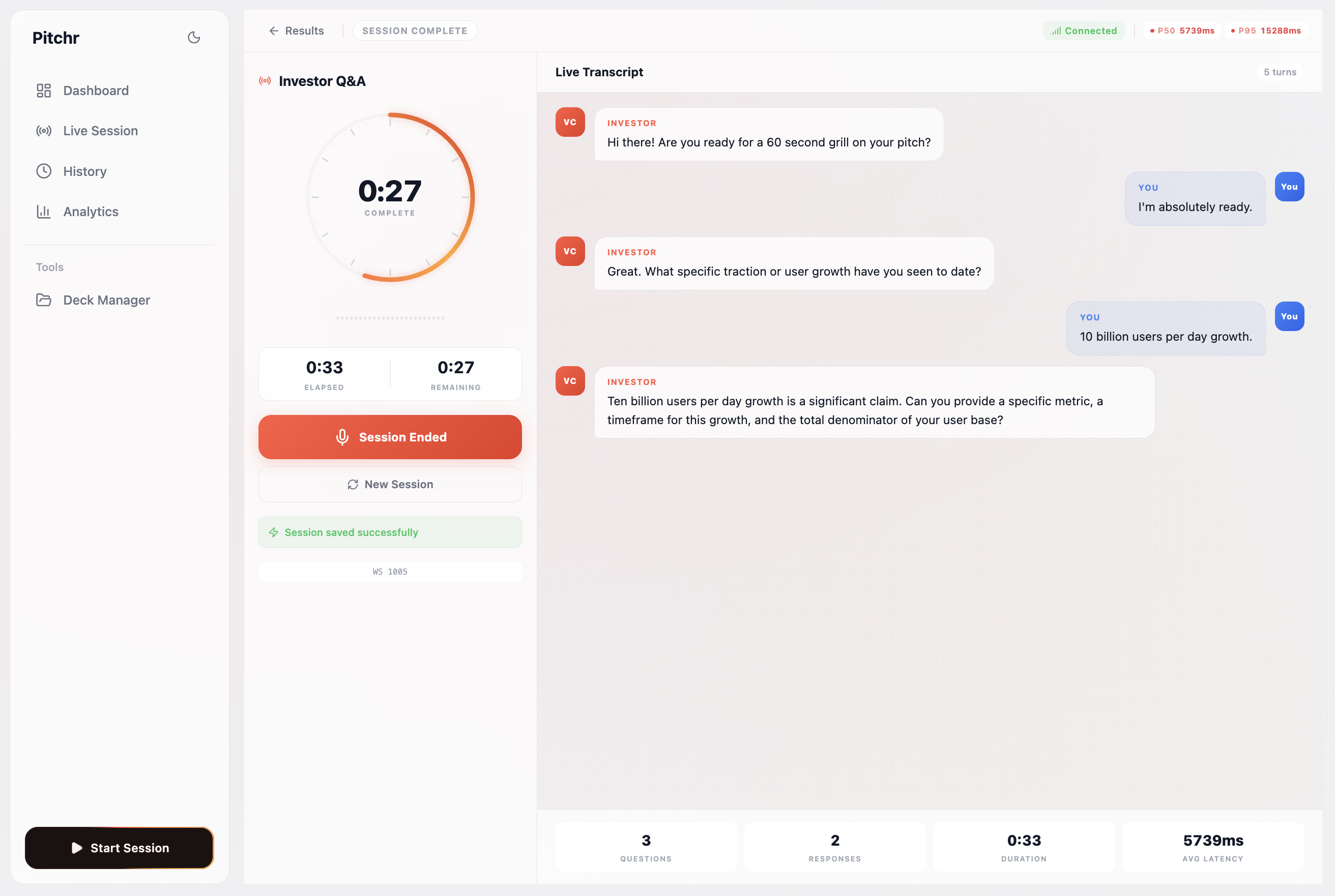
Our live agentic Q/A tool using ElevenLabs to grill the user on their just-performed pitch with questions inspired by hackathon judges
-
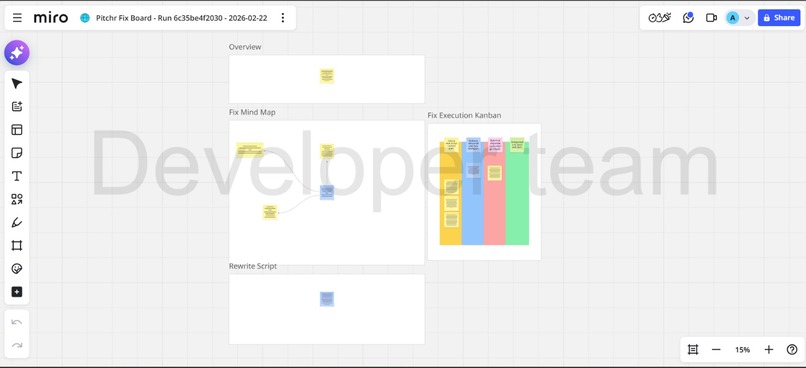
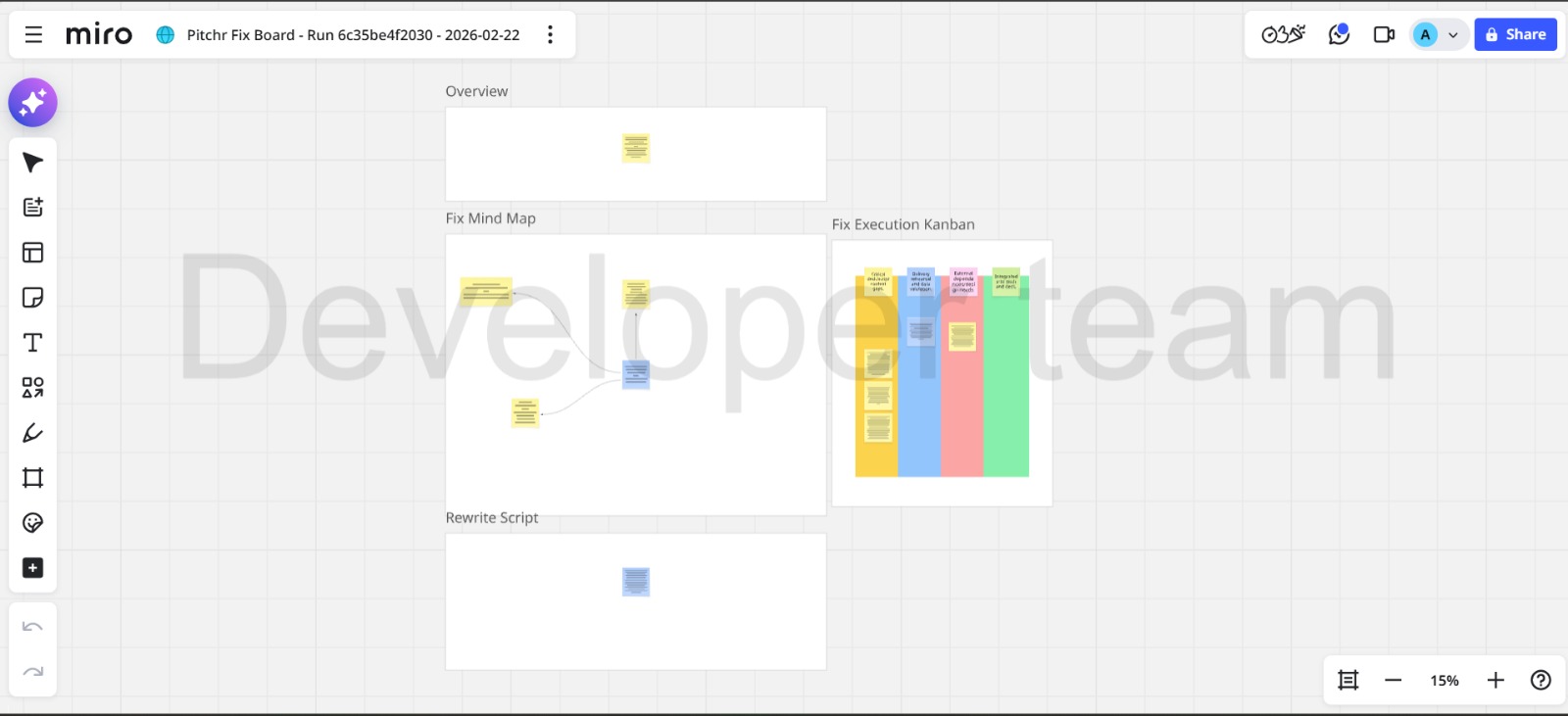
Miro integration dual-sync, tracking progress of the user's pitch abilities

Inspiration
At Hackathons we noticed a recurring failure mode: teams build something technically impressive, then underperform because the pitch has no fast feedback loop. First time founders and hackathon teams usually practice alone, rehearse bad habits (rambling, filler words, vague claims), and cannot get high quality coaching at the exact moment it matters, like late at night before a demo. Professional pitch coaching can be expensive and not always available on demand, so the gap between “great idea” and “clear communication” becomes the difference between winning and getting ignored.
Pitchr was inspired by that last mile problem: make pitch practice feel like iterating code, run, measure, fix, repeat.
What it does
Pitchr is a live AI pitch coach:
- You speak into a visual Zoom-like interface.
- It transcribes your pitch in real time (with timestamps).
- It tracks delivery metrics like pace (words per minute), filler words, repetition, and timing drift.
- After each run it scores you on an investor and judge style rubric (structure, clarity, proof, market, delivery).
- It returns a prioritized fix list, a cut list, and rewritten scripts (for example 60s and 120s).
- It can generate presentation slide content from what you said, so your deck and your pitch stay aligned.
- It saves runs to history so you can see score trends and recurring failure modes across attempts.
How we built it
We built an MVP around a tight practice loop, optimized for hackathon pitches:
Capture + stream audio (browser mic) The app records audio and streams it so feedback can feel live, not post-mortem.
Realtime transcription (WebSocket STT) We use ElevenLabs Scribe v2 Realtime STT for low latency transcription and streaming partial plus committed segments.
Two parallel analysis layers
- Deterministic delivery stats: pace, fillers, repetition, time fit.
- LLM rubric critique: structured feedback, top fixes, rewrites, and optional judge style objections using Claude and Gemini (routed via a provider layer like OpenRouter).
Slides from speech We convert the transcript into a simple deck outline (problem, solution, proof, ask) so teams can go from a spoken pitch to a coherent slide flow quickly.
Persistence and history We store sessions and results in Supabase so users can track progress over multiple runs.
UI that feels like practice, not a form We use live metrics displayed during the practice session like engagement and filler words to subtly suggest feedback live so users can adjust mid-pitch
A small piece of our scoring logic is intentionally transparent. For example:
WPM = (60 * w_c) / d r_f = f_c / w_c
where w_c is word count, d is duration in seconds, and f_c is filler count. These feed into the delivery part of the rubric score.
Challenges we ran into
- Realtime complexity: streaming audio and handling partial vs committed transcripts without glitches is harder than a normal “upload then transcribe” flow.
- Latency tradeoffs: feedback only feels useful if it is fast, so we had to be strict about what runs live vs what runs after the pitch ends.
- Schema reliability: the UI needs consistent structured outputs (score breakdown, ranked fixes, rewrites). Getting LLMs to always return clean, parseable results took iteration.
- Scope discipline: full live video body language analysis plus slide mismatch detection is tempting, but risky in a hackathon timeframe. We prioritized an audio and text first MVP with a clean demo path.
Accomplishments that we're proud of
- An end-to-end loop that turns “rambling pitch” into a scored run with a fix list and a rewritten script, fast enough to iterate multiple times.
- A defensible rubric breakdown (not just generic advice), plus measurable delivery metrics that users can improve run by run.
- Slide generation from the transcript, reducing the last minute chaos of rewriting decks separately from the spoken story.
- History and score trend tracking so progress is visible, not anecdotal.
What we learned
- The biggest value is not “more feedback,” it’s prioritized feedback. Five high leverage fixes beat a wall of text.
- Deterministic metrics build trust because they are consistent, while LLM critique adds the “why” and provides rewrites that save time.
- Hackathon pitching is a distinct use case: short formats, many iterations, and judge focused concerns like credibility, clarity, and demo flow.
What's next for Pitchr
- Better personalization: let users choose pitch mode (60s, 120s, 3 min), audience type, and learn from their history to recommend the next drill automatically.
Built With
- anthropic-claude-api
- drei
- elevenlabs-realtime-stt
- express.js
- mediapipe-tasks-vision
- next.js-(app-router)
- node.js
- openrouter
- pdf-parse
- pdfjs-dist
- playwright
- react-19
- react-three-fiber
- supabase-(postgres-+-storage)
- tailwind-css
- three.js
- typescript
- websockets-(ws)


Log in or sign up for Devpost to join the conversation.