-
-
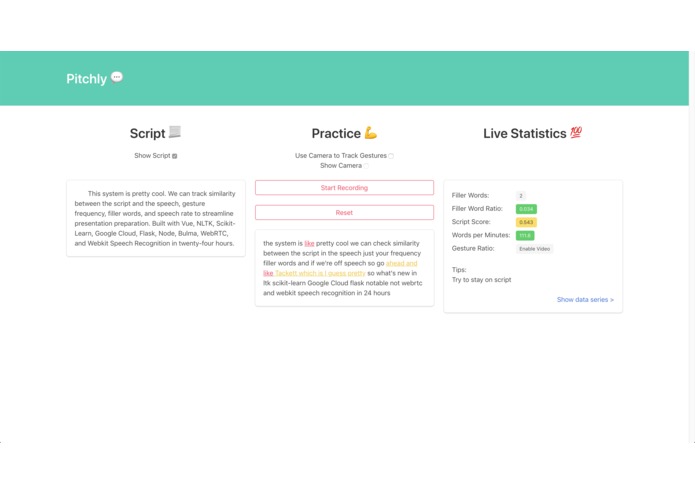
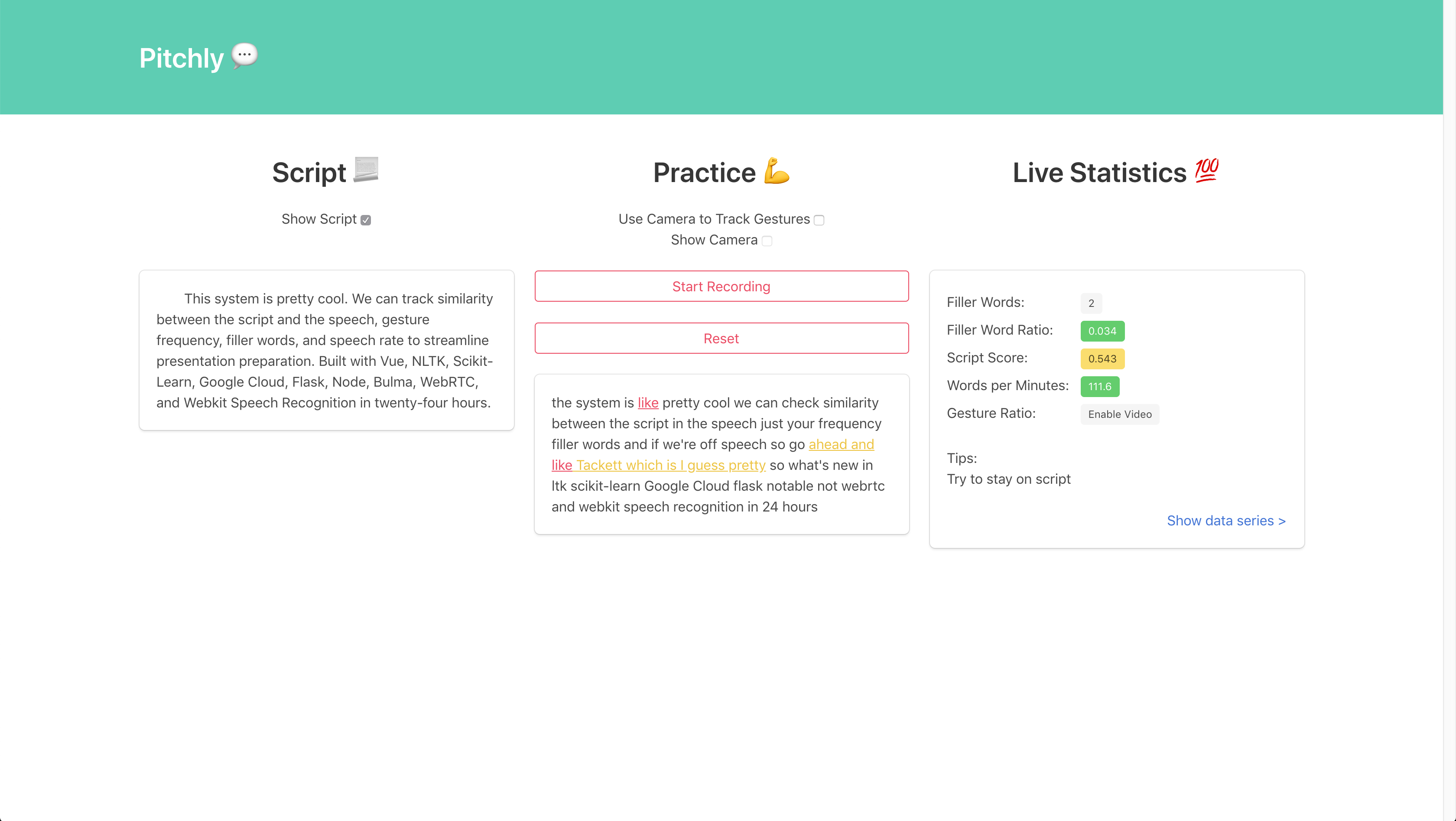
The home page
-
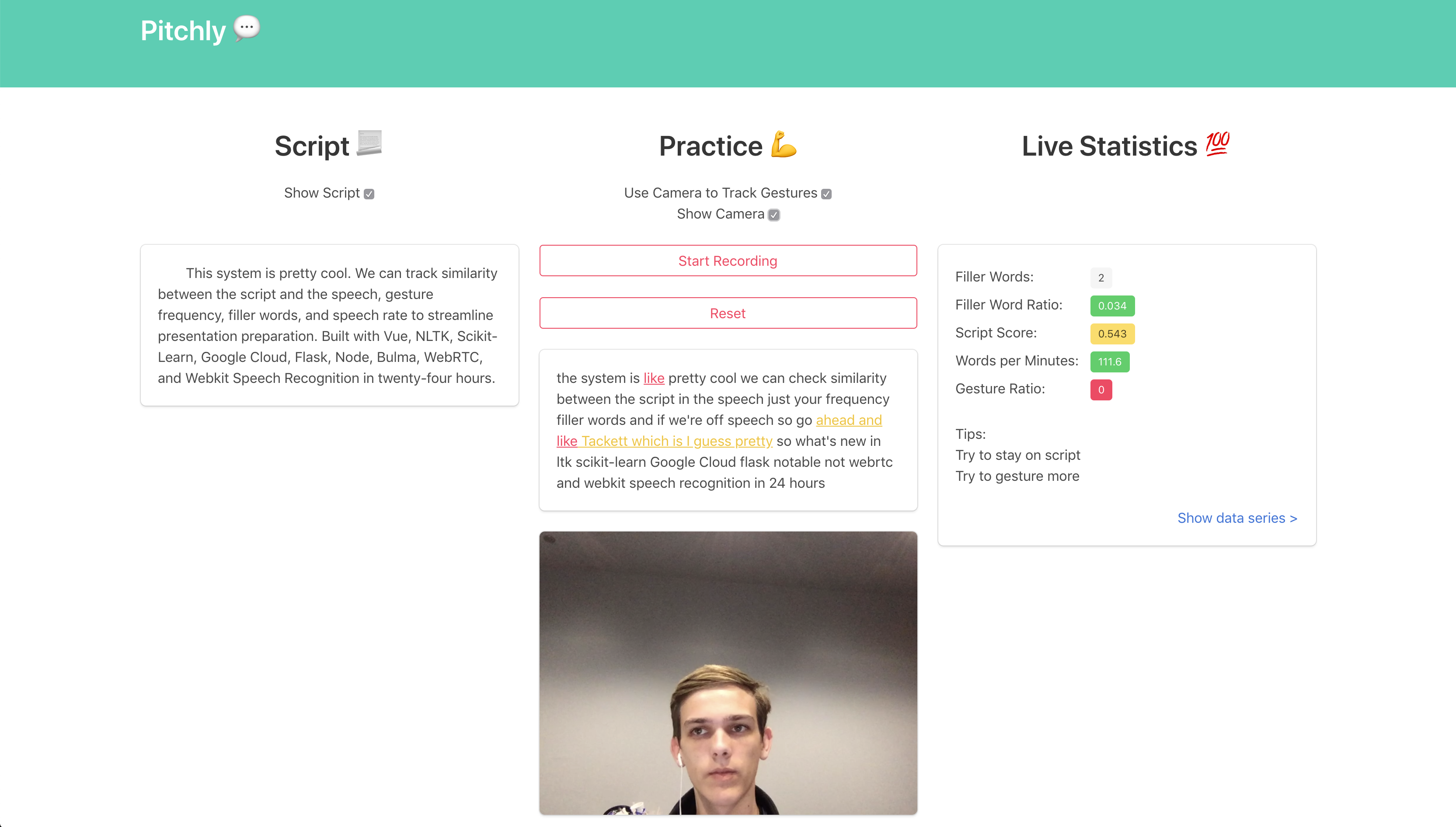
I look mad I'm not actually mad just sleepy
-
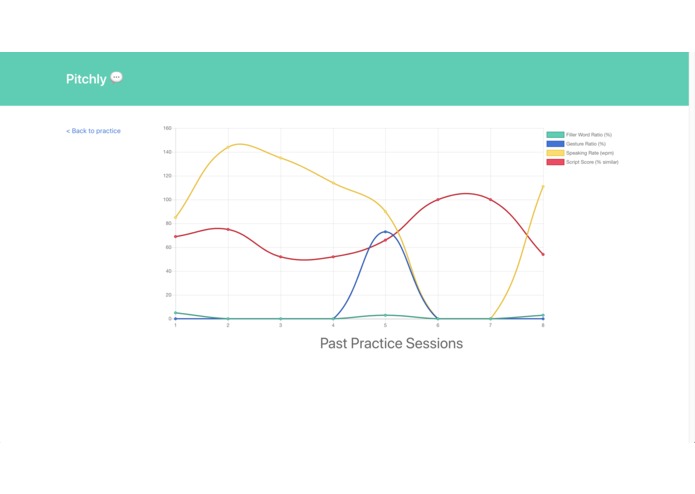
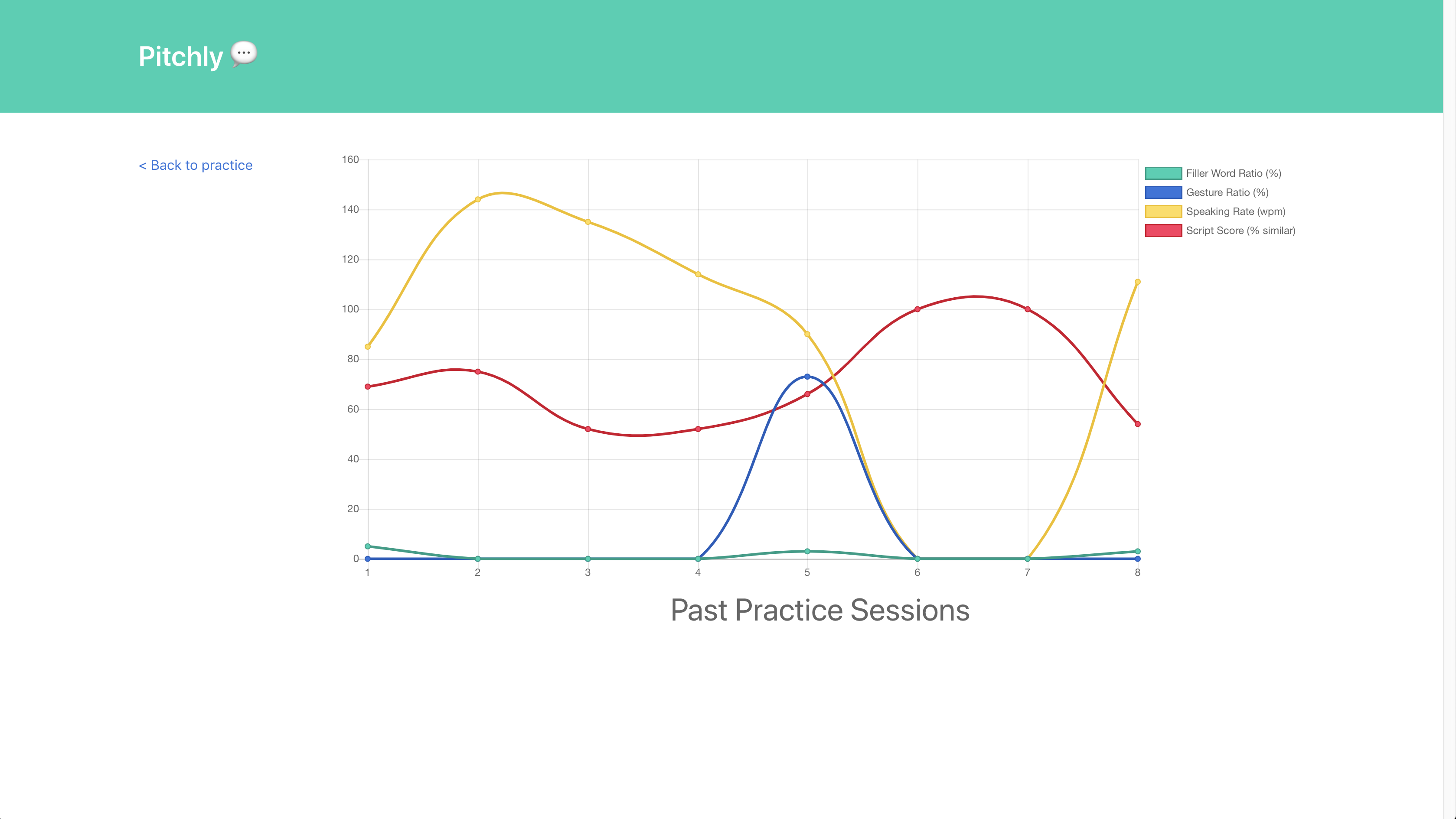
Data visualization of stats over practice sessions
-
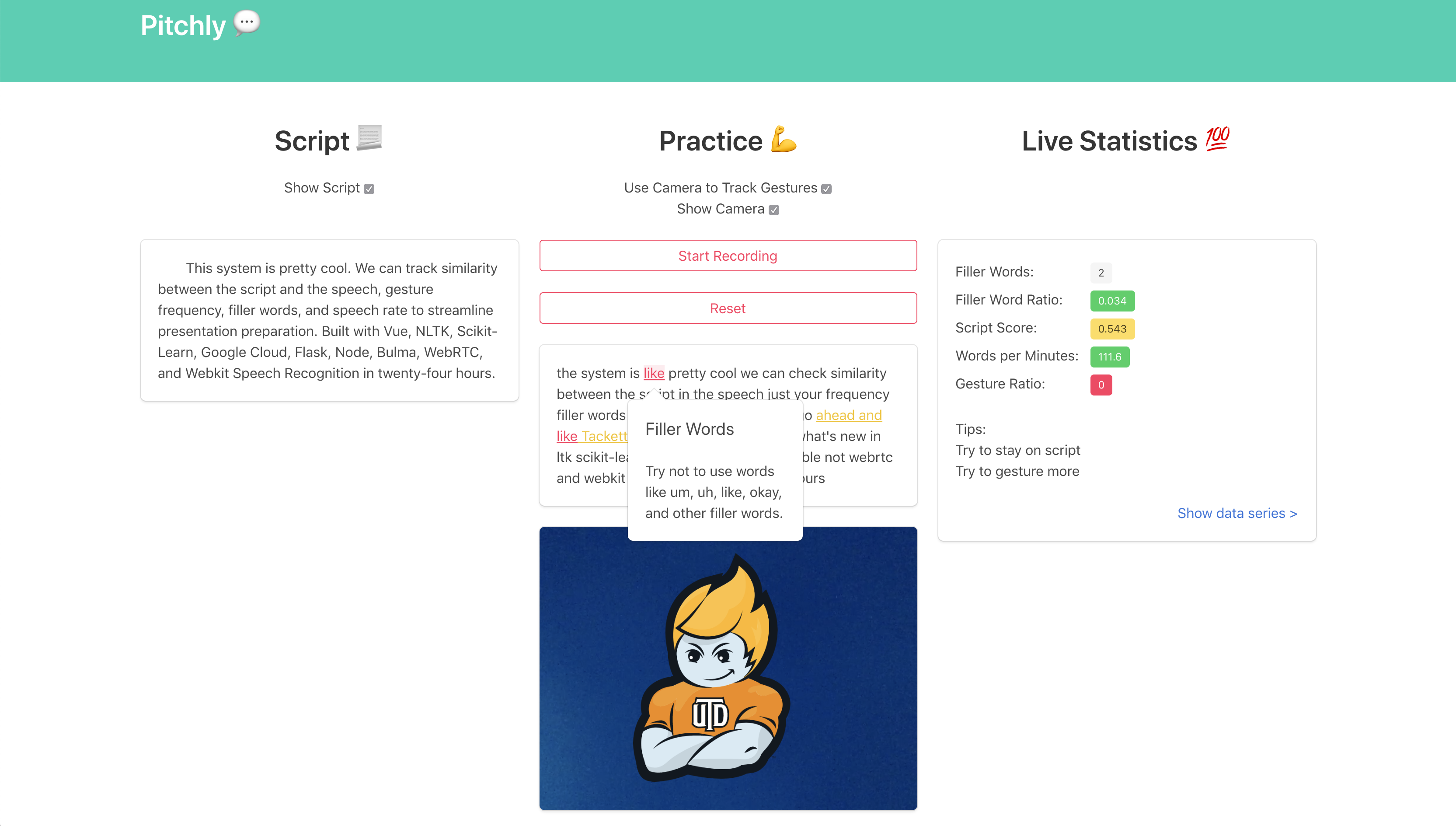
Tooltips and Temoc
Inspiration
We can practice a presentation or pitch all day without feedback and get acceptable results, but why work hard when you can work smart and achieve a smoother, more professional presentation with the press of a button? Your friends are tired of giving the same feedback for your speeches over and over, so we automated the process.
What it does
Pitchly automatically gives feedback on your presentation through video and audio recorded practice sessions. It tracks the number of filler words such as "um" or "like" and the ratio of filler words to total works, the rate of speaking, the similarity of the presentation to the uploaded script, and the frequency of gestures. This helps presenters eliminate unnecessary words and phrases in their presentation while making sure they stay on script in a timely manner, without looking like a robot without any gesturing. Pitchly also allows the user to upload their pitches to an open source repository that acts as an archive of presentations.
How I built it
The front end is built with Vue.js and Bulma, with jQuery to connect to the node.js backend. The node backend can then forward API requests to either a Python API built on flask or Google Cloud depending on the task.
We are able to convert speech into text using Webkit's Speech Recognition API that is built into the browser. This means that we do not have to query a cloud for speech to text, significantly improving recognition speeds and reducing data usage.
Filler word detection and highlighting is done using regex in python. Speech rate measurements are taken by tokenizing the phrase, looking at the number of words, and dividing by the time spent recording.
Document and phrase similarity is accomplished using the cosine distance of a set of tf-idf vectors from the script and the speech in a way that resembles a convolutional neural network. Each word is then given a score based on the similarity of the phrases it appears in. When this score is below a certain threshold, it is highlighted as off script until the score rises above the threshold.
To measure the frequency of gestures, an image is taken every 0.5 seconds. This is accomplished through WebRTC streaming to a video element which then writes its data to a canvas to be sent back to the server as base 64 encoded png data. The png data is finally sent to a Google Cloud model that we trained to classify images as gestures or non-gestures. By looking at groups of these classifications over time, we can develop a sense of the amount that the speaker is gesturing.
We visualize the data using Chart.js. Past presentations are stored using the HTML 5 LocalStorage, where it can be retrieved and added on to after each presentation.
The open source pitch publication is done using the git command line tool through a NodeJS exec call. The file is written in a markdown template where it is then staged, committed, and pushed to the repository.
Challenges I ran into
Connecting Flask to our Node server proved to be difficult, especially when sending large amounts of data that was not sanitized. We finally got the Node server to forward language processing requests to the Python Flask server by remodeling our data as form data sent over a post request with the request module.
Sending data to the Google Cloud model was also difficult. We resorted to calling curl from a shell statement from within Node after writing the png data to a json file as specified by Google, which simplified credentials tremendously.
Accomplishments that I'm proud of
With limited time, we could not get a large set of pictures to train our gesture prediction model on. However, with less than 500 sample images, we were able to achieve over 99% accuracy on gesture prediction, demonstrating the efficiency and robustness of our model.
The phrase similarity model was also a large undertaking that involved developing our own natural language model. We are happy with the boundary detection for off-script comment highlighting and the methods used to assign a similarity score to each word.
What I learned
We learned how to connect Node and Flask together to allow the best of both worlds, with Python for machine learning and Node for routing, Google Cloud connection, and security. We also learned how to work with Google Cloud AutoML and Computer Vision to develop models that can label images with high accuracy.
What's next for Pitchly
We would like to improve our speech to text methods, but as this is a highly active area of research that major tech companies are working on just to improve results by a percent or two, we may have to settle. The current accuracy is by no means application breaking, but it can lower the script similarity score.
We would also like to open up an API that can automatically comment on a video of a speech with all of the statistics described above. This would allow a computer to look at and judge debates and speeches and for speakers to look at what the perfect ratios are for a speech that can awe an audience.
Finally, we want to implement a speech inflection metric. This could be implemented by taking the audio recorded, running a fourier transform to determine the pitch and amplitude of the voice at specific moments in time, and considering the variance in pitch and amplitude as well as pauses in between phrases for effect.
Built With
- bulma
- chart.js
- css3
- express.js
- flask
- github
- google-cloud
- html5
- jquery
- nltk
- node.js
- python
- scikit-learn
- vue
- webkitspeechrecognition
- webrtc










Log in or sign up for Devpost to join the conversation.