-
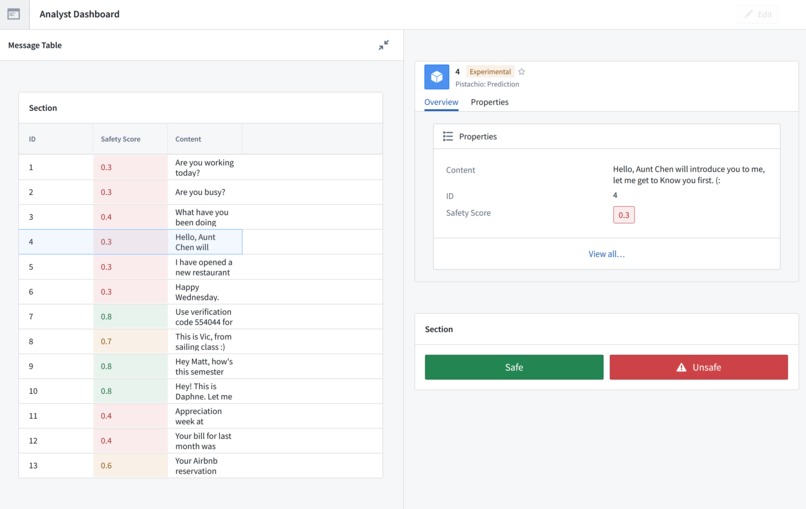
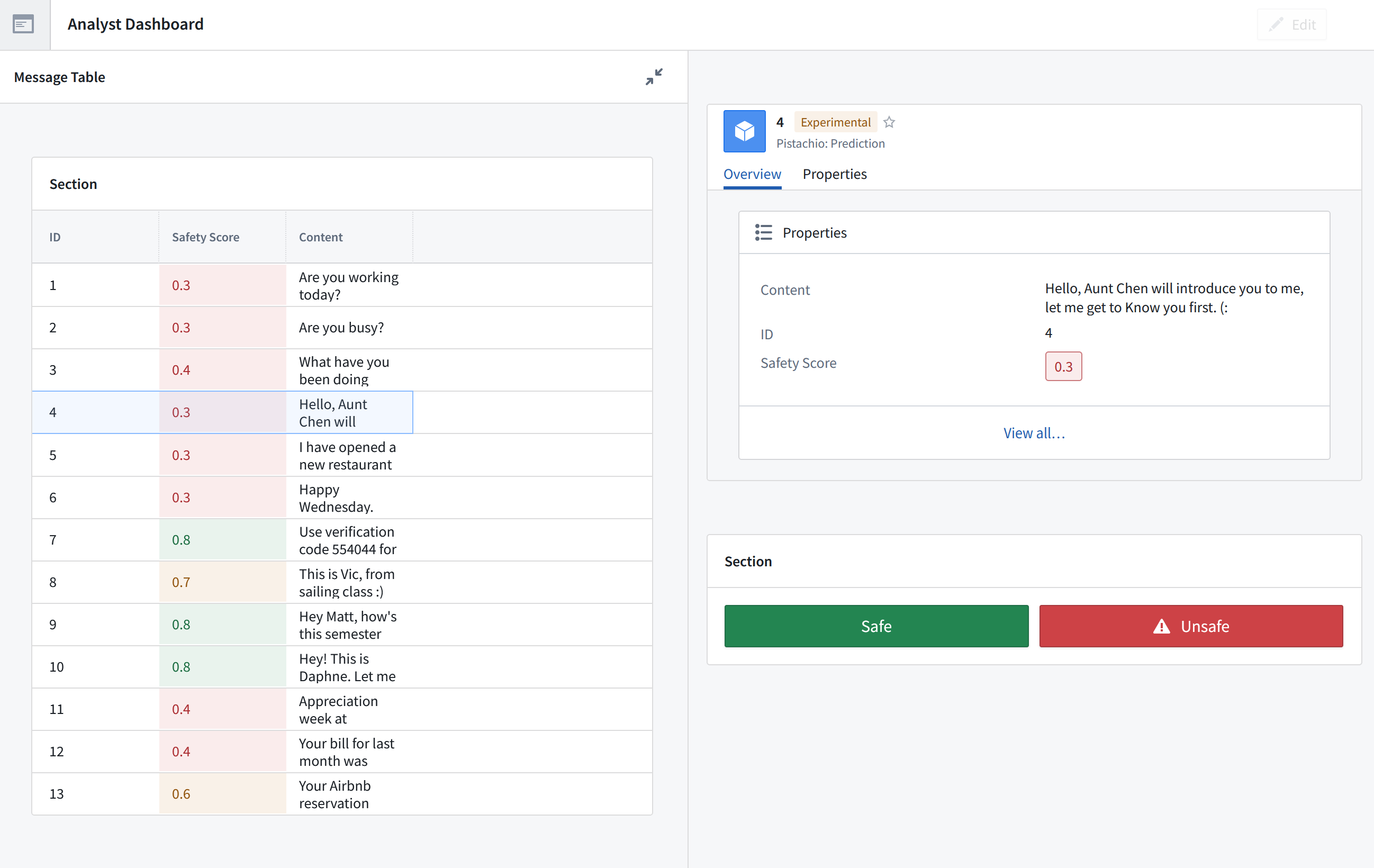
Analyst Dashboard
-
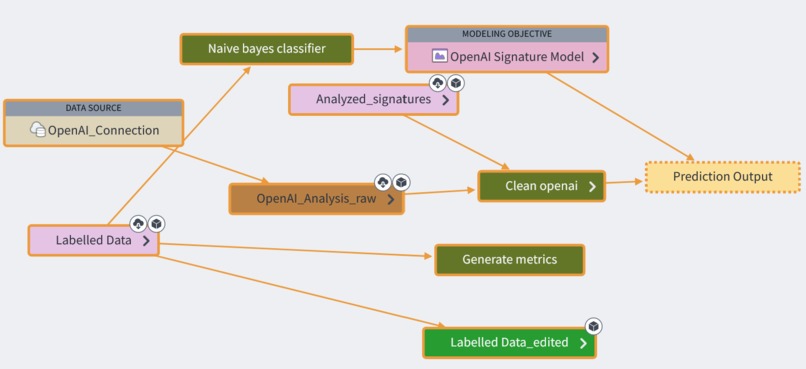
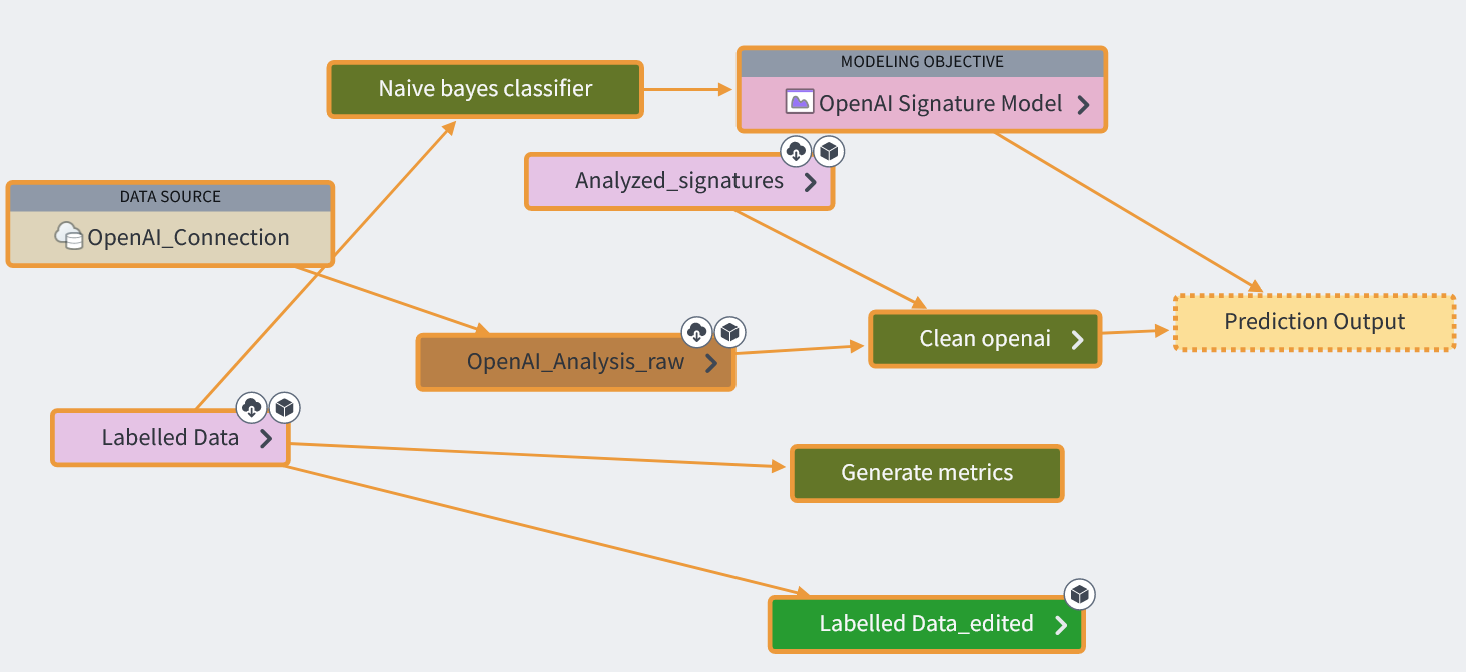
Data lineage
Inspiration
Having grown frustrated with the sheer volume of spam, fraudulent, and malicious unsolicited messages being sent over the internet, we wanted to develop a reliable way to distinguish the authentic from the spurious. We identified that the elderly and those who are not as technologically literate are at greater risk of falling victim to these social engineering attempts. These vulnerable sections of the population, typically overlooked by technology services, should be provided with more resources for protecting them from malicious actors.
Although current technology is capable of searching for specific keywords, it is not always capable of identifying the more advanced attacks that are becoming increasingly common. With recent advancements in Natural Language Processing models, however, we realized the potential that they had in the space of recognizing, identifying, and analyzing human-readable text for malicious content. We decided to use these new tools to identify higher-level and abstract features of potentially harmful messages, and use these analyses to better filter out those messages.
What it does
We first collect text-based messages from different sources, such as messages and emails. Using these messages and existing threat knowledge, we engineered prompts for OpenAI to detect features that are common to modern attacks, including concrete topics (such as Finance) but also abstract concepts (such as friendliness or perceived closeness). We pass this information into a classifier, which generates a predictive score about the likelihood that this message is malicious or fraudulent.
We filter out highly suspicious messages and allow through very safe messages. We recognize that human involvement is important to developing an evolving tool, both through catching edge cases and data generation. Therefore, we have a dashboard for trained analysts, to which we provide information for both oversight and processing messages with less-clear classification.
Ethics
The power behind Pistchio’s ability to detect potentially fraudulent behavior comes from a highly advanced Natural Language Processing tool. This means that the messages received by the user are scanned and analyzed before a final safety rating can be determined. With this in mind, it is most important that Pistachio recognizes and upholds the user’s data security and privacy. Additionally, the team behind Pistachio recognizes the existence of potential ethical risks associated with AI and large-scale data analytics products.
Some areas of concern have been addressed by our team in the following ways:
Privacy: Our users will be made aware of the way in which our Natural Language Processing tool analyzes their information, including how their data will be stored, and who it can be accessed by. We require that users are fully informed of how we use their data before giving their consent.
One major issue with our platform is that senders of messages cannot give informed consent before sending their initial message. We acknowledge that people expect privacy in their communications, but message gathering is essential to our platform. To better address this step in the future, we will research and carefully follow the laws and regulations around third party collection and viewing of communication.
Pistachio will need to collect sensitive information or private communications that the user may not want to reveal to others. Therefore, we decided to develop an option for users to not filter out certain known forms of communication. This feature, enabled by default and configurable by users, will allow them to protect their private communications, though at the slight expense of product effectiveness. We also hope to develop personal information filters and message scrambling services to ensure that our analysts do not have intrusive levels of access to personal data.
We also try to avoid data security issues by storing only data that we need to provide our services. This includes deleting the raw messages as soon as processing them is complete. Only portions of messages flagged as highly likely to contain malicious content will be stored for the purpose of justification and training.
Bias: The nature of Natural Language Processing models requires a large amount of data to be trained on. Since our model is trained in English, it may be the case that text containing minor grammatical, spelling, or syntactic errors will be flagged as potentially fraudulent. This means that some users for whom English is not their primary language of communication may experience mistakenly labeled fraudulent messages more frequently compared to native English speakers. This may also extend to those from other underrepresented backgrounds, whose language usage patterns may trigger more investigation.
To address these issues, future training will use data collected from a diverse set of sources and reflect the different way in which all people communicate. We can also give extra attention to sources that may be underrepresented, which would allow us to provide a more equitable analysis. Finally, we need to make sure that our models are equitable through thorough testing on this equitable data before deployment.
Reliance on technology: We recognize that technology is fallible and that something as important as security should always have human oversight. Therefore, we designed our technological tools to support, rather than replace our analysts, who are essential to ensuring user safety.
The use of technology to identify fraudulent activity may also result in a reliance on technology over human judgment, which could lead to an erosion of critical thinking skills in detecting fraudulent behavior. It is important for Pistachio to educate users on how to identify and handle suspicious messages themselves, rather than solely relying on technology to do so.
What's next for Pistachio
We want to continue to develop the most advanced and effective form of fraud protection for our customers. Some improvements that we want to develop to achieve this goal include forming better methods of gathering data to train our model to identify fraud and providing support for more mediums including phone calls and social media messaging. In order to keep up with the advancing sophistication of scamming techniques, we want to be able to rapidly iterate new and improved analysis patterns to stay ahead of the curve.
How we built it
Palantir Foundry, Python code, and OpenAI API
Challenges we ran into
New technology - We were new to Palantir Foundry and accessing the OpenAI API. There were a few configuration issues we ran into, we really appreciated all the help from the Palantir team to get us through these! Lack of training data - Publicly accessible data is quite old and not relevant. The only data we had was the messages and spam from our own devices, which was limited.
Accomplishments that we're proud of
- Quickly learning how to use Palantir Foundry.
- Solving a real world problem using cutting edge technology.
Built With
- openai
- palantir
- python
- sklearn

Log in or sign up for Devpost to join the conversation.