Inspiration
Every processor you've ever used executes instructions through a pipeline — fetch, decode, execute, memory, writeback. But that process is invisible. You never see a stall bubble inserted, a forwarded value saving a cycle, or a branch flush rippling through the stages. PipelineVM makes it visible. We wanted to build something that didn't just simulate computation, but exposed every mechanical detail of how a CPU actually works at the lowest level — in real time, in your terminal.
What it does
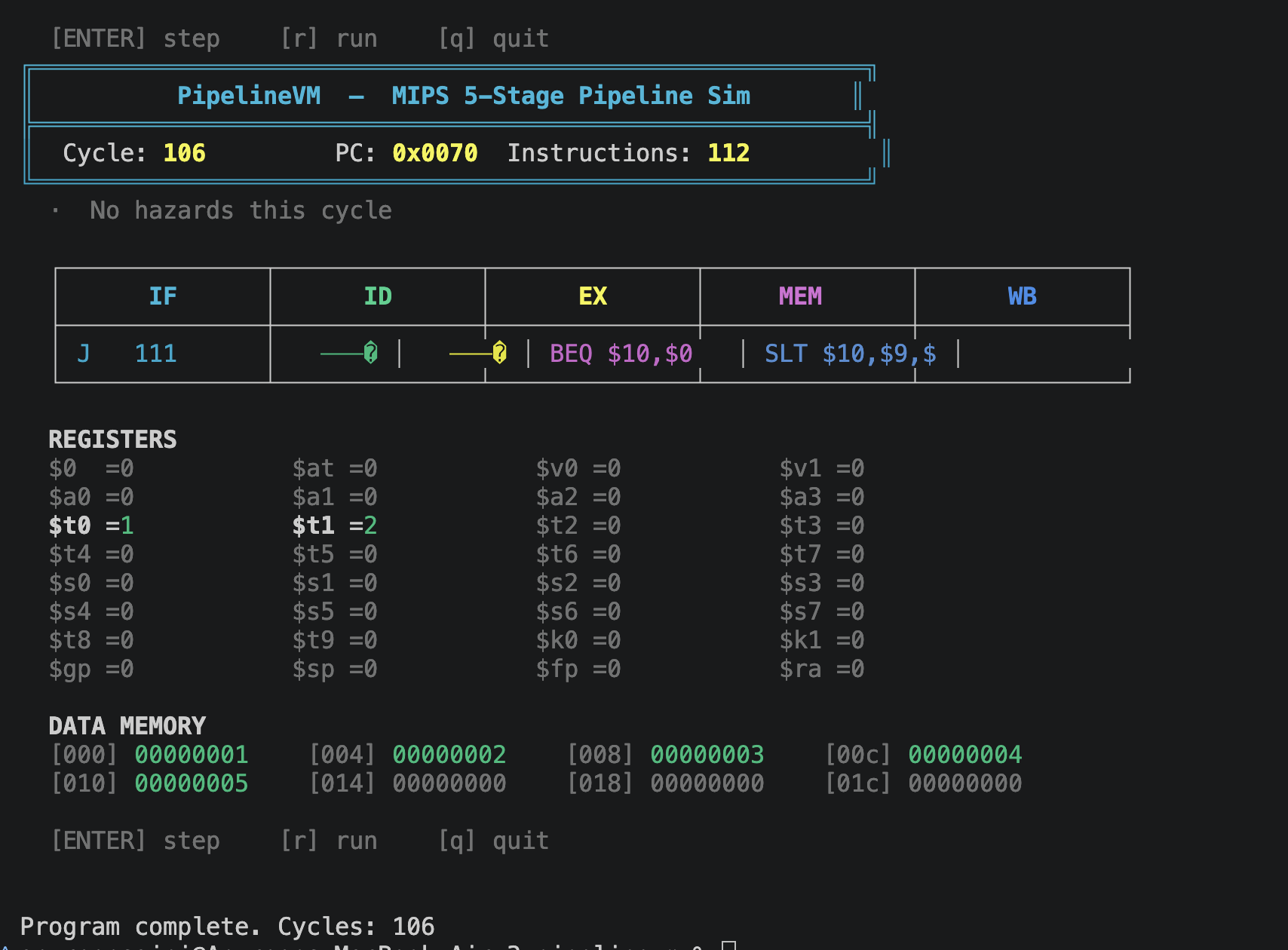
PipelineVM is a fully functional virtual machine written in C that simulates a simplified MIPS-like instruction set through a 5-stage pipeline. It ships with a custom two-pass assembler that compiles human-readable .asm files into a custom binary bytecode format (.pvm), which the VM then loads and executes. Every clock cycle, a live ANSI terminal visualizer renders the current pipeline state — which instruction is in IF, ID, EX, MEM, and WB — with color-coded stages, hazard banners, and a live register and data memory display.
How we built it
The project is split into clean, modular components entirely in C with zero external dependencies:
Assembler (assembler.c) — A two-pass assembler that tokenizes .asm source files, resolves labels in the first pass, and encodes instructions into big-endian binary in the second pass. Output is a .pvm file with a magic header (0xDEADC0DE) and a text segment.
ISA — A simplified MIPS-like instruction set supporting R-type (ADD, SUB, AND, OR, SLT, SLL, JR), I-type (ADDI, LW, SW, BEQ, BNE), and J-type (J, JAL) instructions.
Pipeline (vm.c) — The heart of the project. Every cycle takes a snapshot of all 4 pipeline registers (IF/ID, ID/EX, EX/MEM, MEM/WB) at the start, then processes WB → MEM → EX → ID → IF in order using the snapshots. This prevents read-after-write corruption across stages.
Key pipeline features:
Load-use hazard detection — when a LW result is needed by the immediately following instruction, a 1-cycle stall bubble is inserted and the PC is frozen
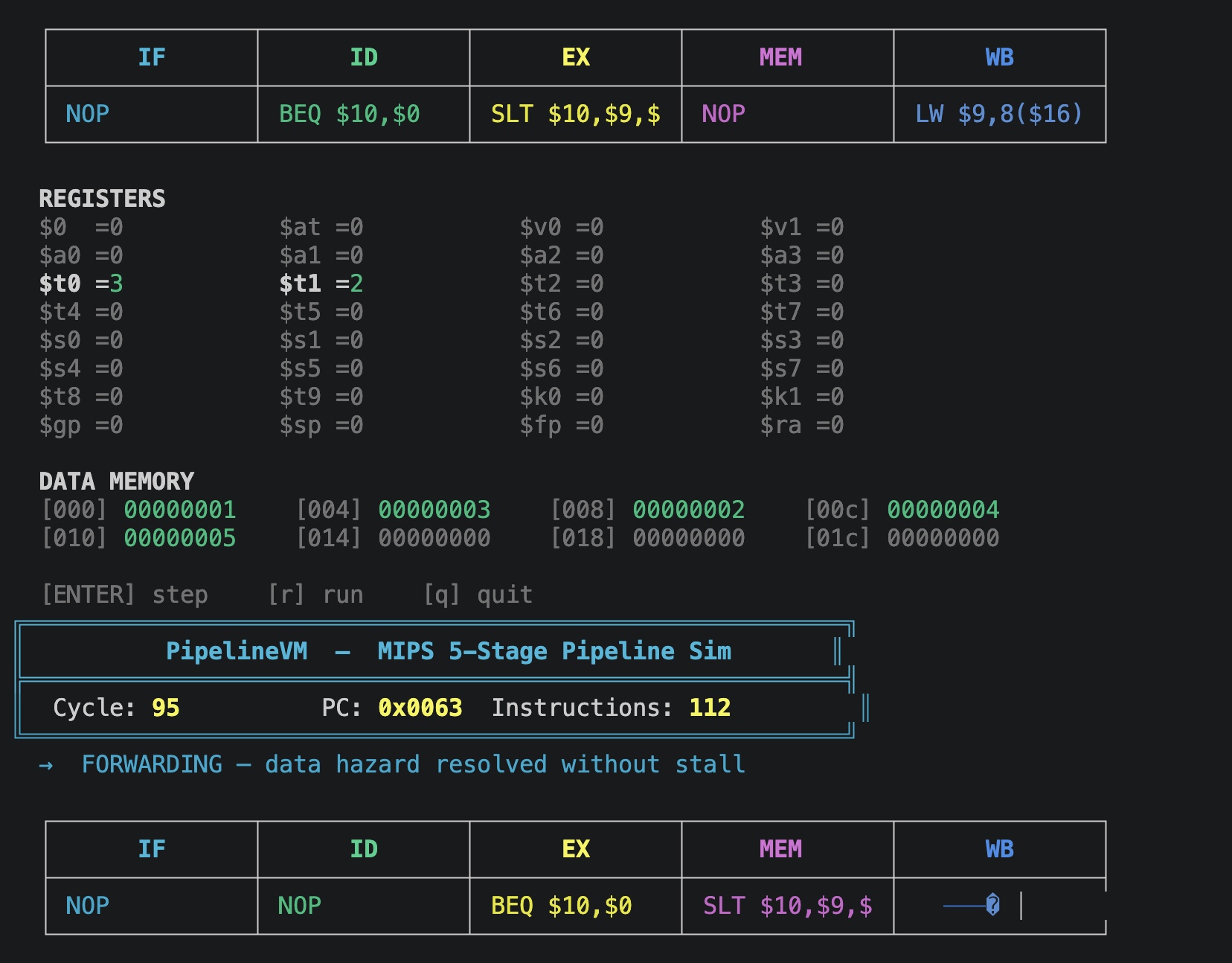
EX/MEM → EX forwarding — ALU results from the previous cycle are forwarded directly into the current EX stage, eliminating stalls where possible
MEM/WB → EX forwarding — load results from two cycles ago are forwarded into EX
Branch resolution in EX — taken branches flush 2 pipeline stages
Jump resolution in ID — jumps flush 1 pipeline stage
Memory (memory.c) — A 32-register file and 4KB byte-addressed data memory with big-endian word layout. $zero is hardwired to 0.
Visualizer (viz.c) — A full ANSI terminal renderer using color-coded pipeline stage columns, hazard/forward status banners, live register display (non-zero values highlighted in green), and a dynamic data memory view.
Challenges We Ran Into
The hardest part wasn't writing the pipeline — it was getting the details right.
Snapshot ordering — A naive pipeline implementation reads and writes the same pipeline registers in the same cycle, causing instructions to bleed into each other. The fix was snapshotting all four pipeline registers at the start of every cycle and processing stages strictly WB → MEM → EX → ID → IF using those snapshots. Getting this order wrong produced subtle bugs that only appeared on specific instruction sequences.
Load-use hazard + forwarding interaction — When a stall fires, the EX/MEM register also needs to be cleared, not just ID/EX. Missing this caused the forwarding logic to see a stale value from the previous iteration and forward it incorrectly into the next instruction's operands, corrupting memory addresses during the bubble sort.
SLL encoding and execution — Shift instructions encode the shift amount in bits 10–6 of the instruction, not in a register. The assembler was encoding it correctly but the VM was passing rs (always 0 for shifts) into the ALU as the shift amount instead of extracting the shamt field. Every SLL silently executed as a NOP, breaking all array address calculations in sort.asm.
Big-endian memory layout — The data memory is a uint8_t array but load/store instructions operate on 32-bit words. An early implementation treated dmem as a uint32_t array, which worked on little-endian machines but produced wrong byte ordering. Rewriting dmem_lw and dmem_sw to manually pack and unpack 4 bytes fixed correctness across platforms.
Branch resolution timing — Resolving branches in EX means two instructions have already entered the pipeline behind the branch by the time we know it's taken. Both IF/ID and ID/EX need to be flushed and zeroed, not just one. Missing the second flush caused the instruction after a taken branch to partially execute and corrupt register state.
Accomplishments That We're Proud Of
Getting the forwarding paths right. It sounds simple — just pass a value forward a stage — but correctly prioritizing EX/MEM over MEM/WB, handling the case where both paths fire simultaneously, and making sure forwarding never happens across a stall boundary required careful reasoning about every possible instruction sequence. When the bubble sort finally produced [1, 2, 3, 4, 5] in data memory after 10 hours of debugging, that was a real moment.
Building a complete toolchain from scratch. PipelineVM isn't just a VM — it's an assembler, a binary format, a custom ISA, and an execution engine, all written in C with zero external libraries. Every layer was built by hand, from the two-pass label resolver in the assembler to the byte-packing in the memory module.
The visualizer. Watching instructions flow through color-coded pipeline stages in real time, seeing a stall banner appear exactly when a load-use hazard fires, and stepping through bubble sort cycle by cycle while data memory values turn green as they're written — it turned a correctness problem into something you can actually watch and understand.
Five fully verified demo programs. fib.asm produces $t0 = 55 in exactly 67 cycles. sort.asm sorts [5,3,1,4,2] into [1,2,3,4,5] in 106 cycles. hello.asm counts down to zero cleanly. These aren't approximations — the outputs are cycle-accurate and match hand-traced expected values.
Proving the concept works. A pipelined CPU is usually something you study on paper or implement in Verilog with dedicated hardware. PipelineVM shows that the same concepts — hazard detection, forwarding, flush logic, control signals — can be implemented cleanly in a few hundred lines of C and run on any machine with a terminal.
Why It Matters — Systems and Low-Level Impact
PipelineVM sits at the intersection of compilers, computer architecture, and systems programming. Building it requires understanding:
How instructions are encoded at the binary level and what every bit means Why out-of-order data dependencies cause correctness failures without stalls or forwarding How memory abstraction works — bytes vs words, alignment, addressing modes Why branch mispredictions are expensive and how flushes restore correctness
What's next for PipelineVM
As a working model it already demonstrates the core mechanisms of any real pipelined processor. But the architecture is deliberately extensible — future additions could include a cache simulator with hit/miss tracking, a branch predictor with accuracy statistics, a superscalar dual-issue front end, privilege levels and a trap/exception mechanism, or a full syscall interface for I/O. Each addition maps directly to a real concept in modern CPU design. The project proves that you don't need thousands of lines of Verilog or a silicon fab to understand how a processor works. A few hundred lines of C, a terminal, and the right abstractions are enough to build something that behaves like the real thing.
Demo Programs
Five verified programs ship with the VM:
- **`fib.asm`** — Computes Fibonacci(10) iteratively → `$t0 = 55` in 67 cycles
- **`sort.asm`** — Bubble sorts `[5,3,1,4,2]` in-place → `dmem = [1,2,3,4,5]` in 106 cycles
- **`hello.asm`** — Countdown loop from 10 to 0 → `$t0 = 0`
- **`sum.asm`** — Sums first 10 natural numbers (1+2+...+10) → `$t0 = 55`
- **`test.asm`** — Register arithmetic stress test, loads `$t0=10`, `$t1=20`, computes `$t2=$t0+$t1` in a continuous loop → `$t2 = 30` per iteration
GitHub Link:
Built With
- ansi
- assembly
- c
- make




Log in or sign up for Devpost to join the conversation.