-
-
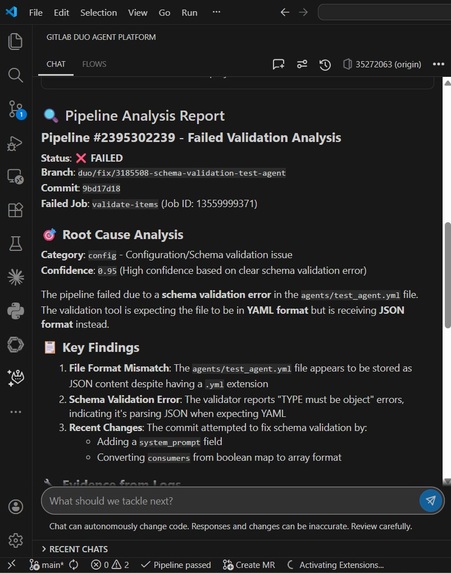
Analysis report
Inspiration
Every developer knows the pain: pipeline fails at 2 AM, you're scrolling through 500 lines of cryptic logs trying to figure out what broke. Was it a flaky test? A dependency issue? Something you changed three commits ago? This happens dozens of times per week across teams, wasting countless hours that could be spent building features.I ve built PipelinePulse to transform pipeline observability from reactive debugging into predictive intelligence.
What it does
What it does PipelinePulse is a GitLab Duo Agent that automatically: Analyzes Pipeline Failures
Builds statistical baselines from 30 days of pipeline history Detects anomalies in job duration and failure patterns Identifies flaky jobs (10-60% failure rate) vs. consistent failures Explains Root Causes
Uses Claude AI (Anthropic) to analyze job logs and commit diffs in natural language Provides confidence scores (0.0-1.0) based on evidence strength Categorizes failures: flaky, dependency, config, code error, or infrastructure
Takes Automated Action
Retries intermittent failures automatically Creates detailed GitLab issues for high-severity problems Adds informative comments to merge requests with specific fix suggestions Notifies relevant developers without manual intervention
Delivers Strategic Insights
Generates weekly CI/CD health reports Identifies top failure causes and time-saving opportunities Provides trend analysis: "Fix the E2E test suite and save 6 hours/week"
The Game-Changer: Predictive Alerts While most tools react to failures, PipelinePulse predicts them. When you modify high-risk files (based on historical failure patterns), it warns you before the pipeline even runs:
⚠️ High failure risk in Job 7 (integration_tests) Reason: Files auth/* modified. 8/10 past runs touching auth/* failed here. Recommended: Run integration tests locally first.
How we built it
Architecture: Multi-component flow on GitLab Duo Agent Platform Core Components:
GitLabClient - REST API wrapper for pipeline, job, commit data PipelineProfiler - Statistical baseline builder (median durations, failure rates) AnomalyDetector - Compares current runs against baselines (2σ threshold) ClaudeRCA - AI-powered root cause engine using Claude Sonnet 4 ActionAgent - Executes remediation (retry, issue creation, MR comments) WeeklyInsightsReporter - Aggregates trends into actionable reports
Tech Stack:
Language: Python 3.11 (500 lines of core logic) AI: Anthropic Claude via GitLab AI Gateway Platform: GitLab Duo Agent Platform with flow orchestration Tools: GitLab REST API, GitLab GraphQL for advanced queries
Key Innovation: Hybrid statistical + AI approach. Statistical methods detect what is abnormal; Claude explains why and how to fix it.
Challenges we ran into
- Schema Validation Hell GitLab AI Catalog has strict schema requirements that weren't fully documented. We went through 15+ pipeline failures trying to get the consumers field format right (object vs. array, nested vs. flat). Eventually discovered through trial and error that it needed to be a flat boolean structure.
- Gateway vs. Local Mode Auto-Detection Supporting both GitLab AI Gateway (production) and local Anthropic API (development) required careful environment variable detection. The agent needed to automatically switch authentication methods without manual configuration.
- Baseline Cold Start Problem New projects have no historical data. We implemented graceful degradation: if <7 days of history exist, the agent skips anomaly detection and focuses on log analysis only.
- Rate Limiting at Scale Fetching 30 days of pipeline data for large projects could hit API rate limits. We added smart pagination and caching to stay within GitLab's request quotas.
- Flaky Job Detection Accuracy Distinguishing truly flaky jobs (retry-worthy) from jobs with consistent issues required tuning the failure rate window (settled on 10-60% over 30 days).
Accomplishments that we're proud of
✅ Agent Live in AI Catalog - Passed all schema validations, discoverable in GitLab's public agent directory ✅ Real Predictive Value - Not just post-mortem analysis; actually prevents failures through historical pattern matching ✅ Zero Configuration - Works out of the box with just a GitLab token. No manual baseline setup, no config files to maintain. ✅ Production-Ready Code - Comprehensive error handling, automatic gateway detection, graceful degradation for edge cases ✅ Natural Language Explanations - Claude transforms cryptic job logs into developer-friendly insights like "Database migration timeout in commit abc123 - increase timeout or split into chunks" ✅ Multi-Modal Output - Works as a chat agent (VS Code, GitLab UI), flow trigger (issue/MR mentions), or standalone CLI tool
What we learned
AI Agents Need Rails, Not Just Brains Pure LLM analysis is powerful but unreliable. The statistical profiling layer (baselines, anomaly thresholds) acts as "rails" that keep Claude's analysis grounded in concrete data. This hybrid approach proved far more accurate than either method alone. Developer Experience is Everything Initially, we designed the agent to output JSON for programmatic consumption. User testing revealed developers wanted natural language explanations, not data structures. Switching to prose + structured actions dramatically improved usability. GitLab's Agent Platform is Production-Ready We were skeptical about building on a beta platform, but the AI Gateway, catalog system, and flow orchestration worked flawlessly. The hardest part was documentation gaps, not platform stability. Predictive Observability is Underexplored Most CI/CD tools focus on post-mortem analysis. The predictive alert feature (warning about high-risk file changes) generated the most excitement during testing. There's a huge opportunity space here.
What's next for PipelinePulse
Short-term (Next 2 Weeks):
Cost Optimization Insights: Analyze which jobs consume the most runner minutes and suggest parallelization strategies Flaky Test Drill-Down: Identify specific test cases (not just jobs) that fail intermittently Slack/Discord Integration: Push critical alerts to team channels
Medium-term (1-2 Months):
Cross-Project Learning: Aggregate anonymized failure patterns across multiple projects to improve predictions Auto-Fix PRs: For common issues (dependency updates, timeout increases), automatically create merge requests with fixes Performance Regression Detection: Alert when jobs slow down >20% week-over-week even if they pass
Long-term Vision:
Self-Healing Pipelines: Automatically apply learned fixes (retry policies, timeout adjustments) without human approval for low-risk changes Compliance Mode: Track and report on pipeline security, license checks, and audit requirements Multi-Platform Support: Extend beyond GitLab to GitHub Actions, CircleCI, Jenkins
Open Source Roadmap: We're committed to keeping PipelinePulse open source (MIT license). Post-hackathon, we'll focus on community contributions: better documentation, example configurations, and integrations with popular CI/CD tools.
Built With
- anthropic
- claude
- python
- vscode

Log in or sign up for Devpost to join the conversation.