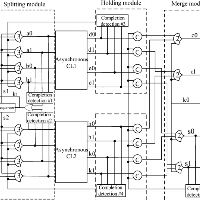
The datapath design that I implemented for the Datapath Project was, in fact, grossly inefficient. By focusing on increasing throughput, a pipelined processor can get more instructions done per clock cycle. In the real world, that means higher performance, lower power draw, and most importantly, happy customers!
In this project, I will make a pipelined processor that implements the Bob-2200 Instruction Set Architecture. There will be 5 stages in my pipeline:
- IF - Instruction Fetch
- ID/RR - Instruction Decode/Register Read
- EX - Execute (ALU operations)
- MEM - Memory (both reads and writes with memory)
- WB - Writeback (writing to registers)
I will have to build the hardware to support all of my instructions. I will have to make each stage such that it can accommodate the actions of all instructions passing through it.

Log in or sign up for Devpost to join the conversation.