-
-
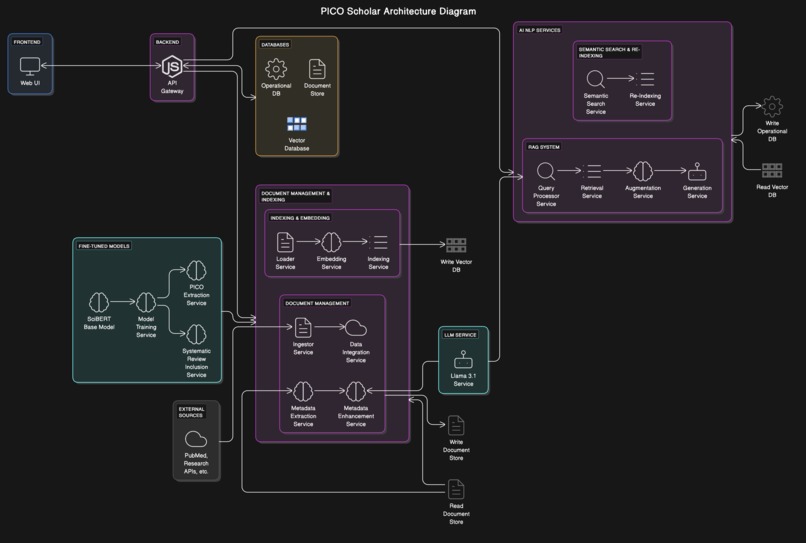
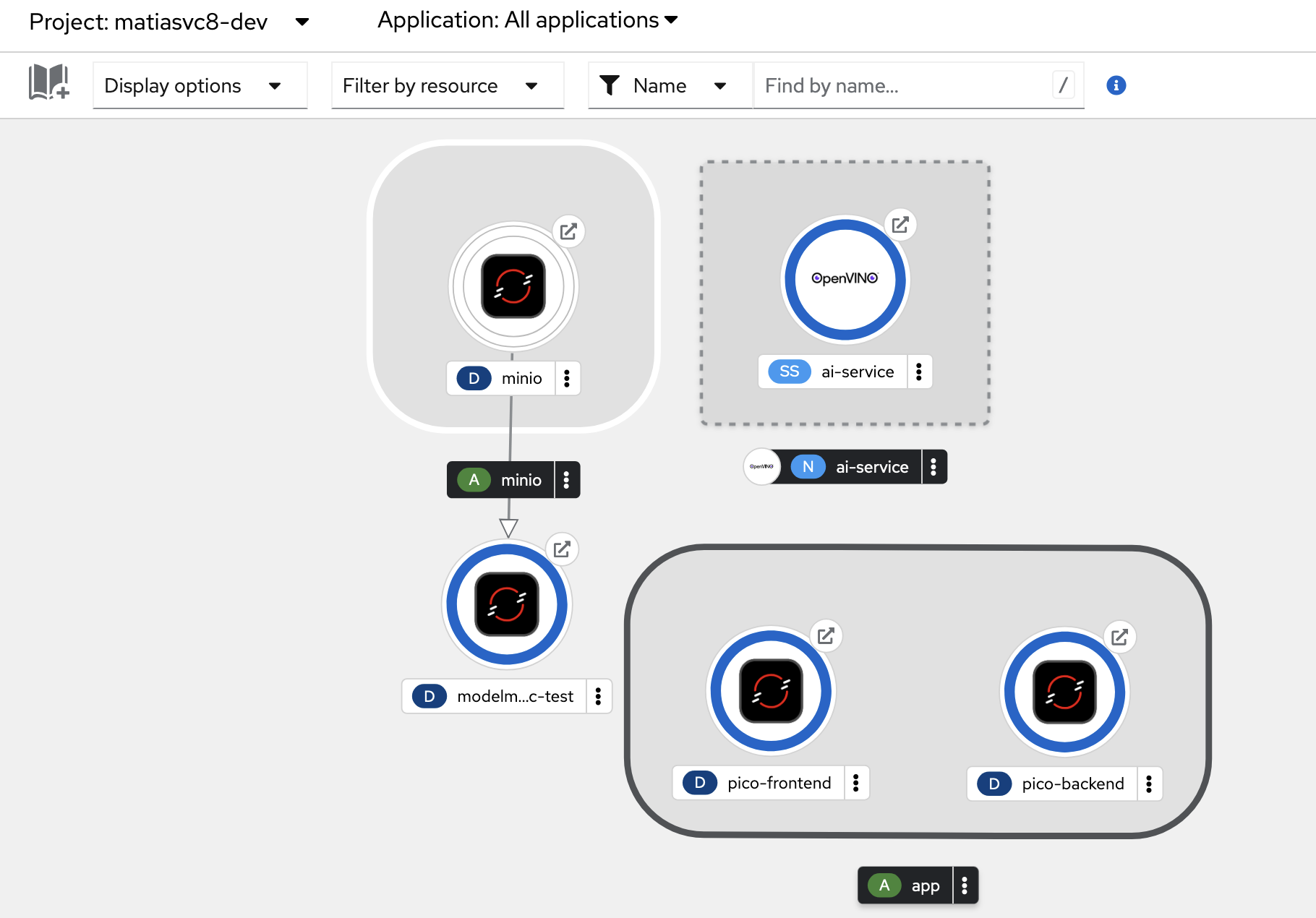
Microservices Architecture
-
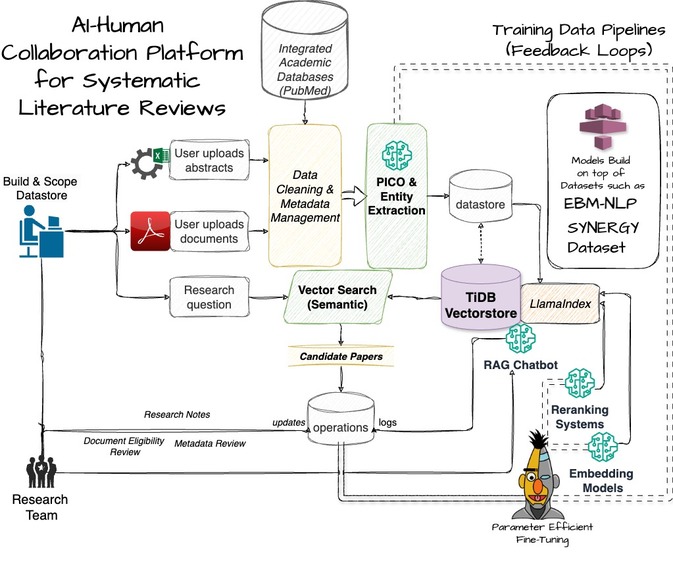
Solution Design
-

Intel XEON
-

Homepage Screen
-
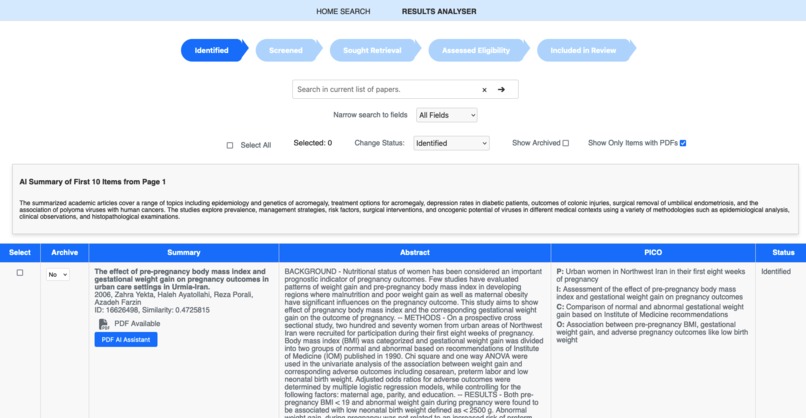
Funnel Screen
-
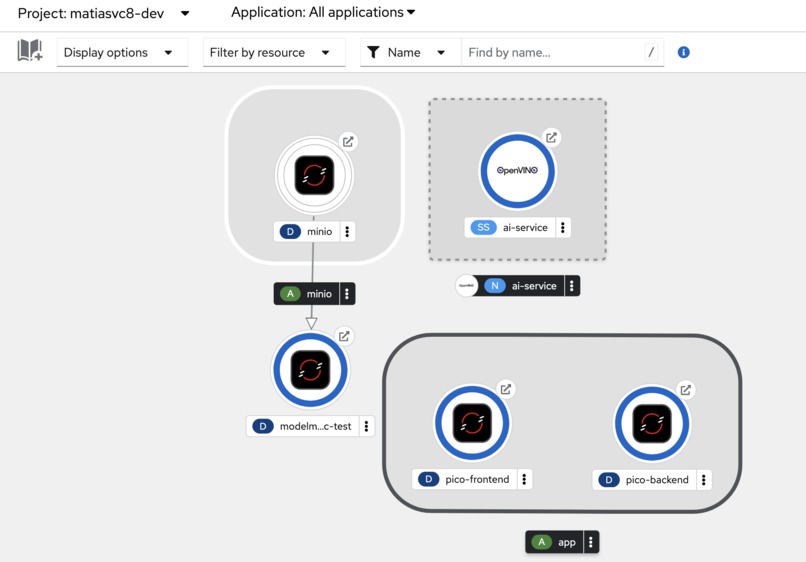
OpenShift Services
-
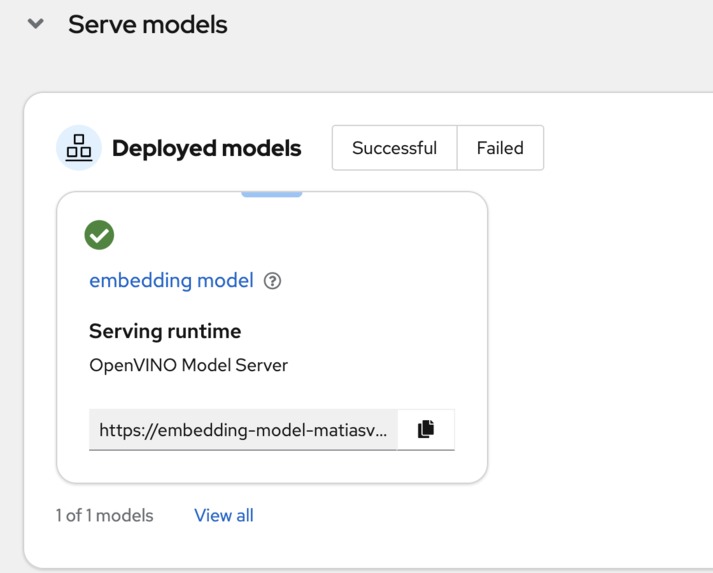
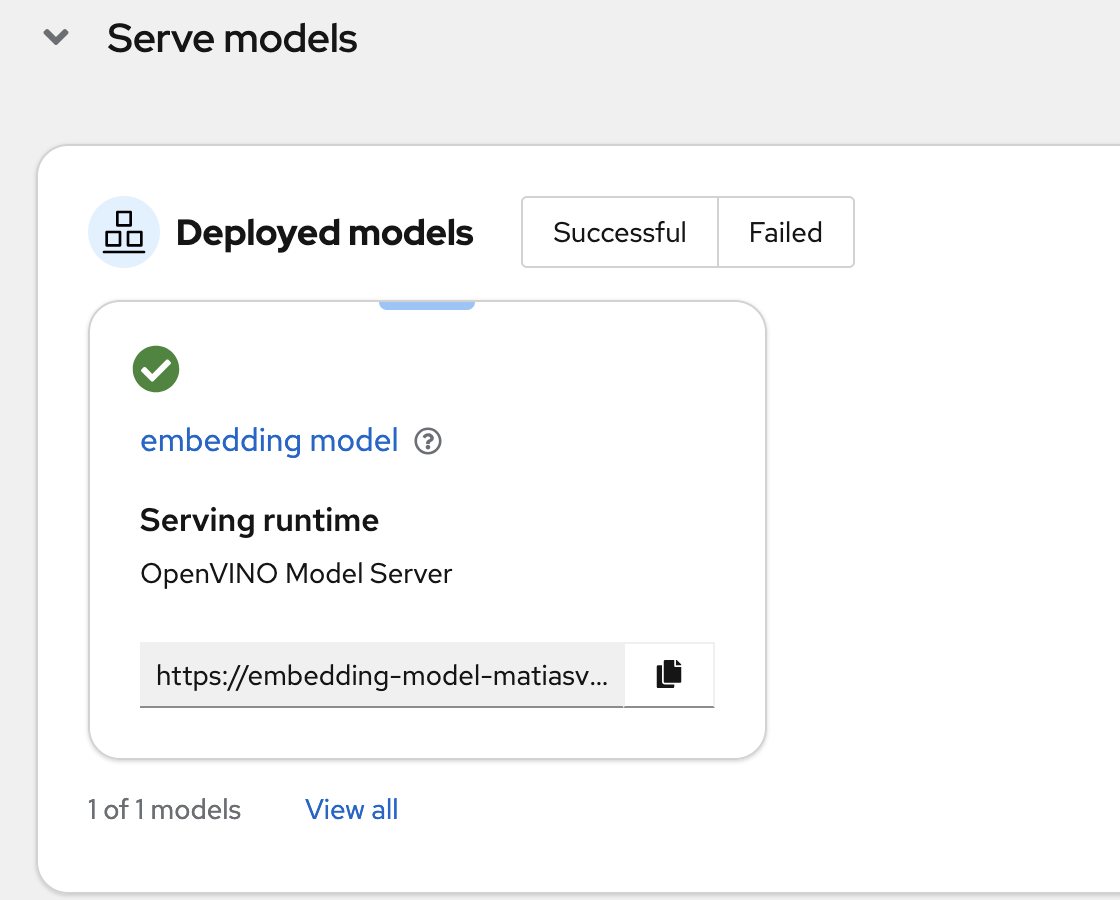
OpenVINO Model Server


Inspiration
Systematic literature reviews are critical for evidence-based research, but the process is time-consuming and labor-intensive. Our team, composed of MSc students from Georgia Tech and initial guidance from researchers from Robert Gordon University, was inspired by the potential of Retrieval-Augmented Generation (RAG) to automate and accelerate this process. By leveraging Red Hat OpenShift AI and Intel’s optimized hardware, we set out to create PICO Scholar—a platform that combines advanced AI tools to streamline systematic reviews and support researchers in making faster, more accurate insights.
What it does
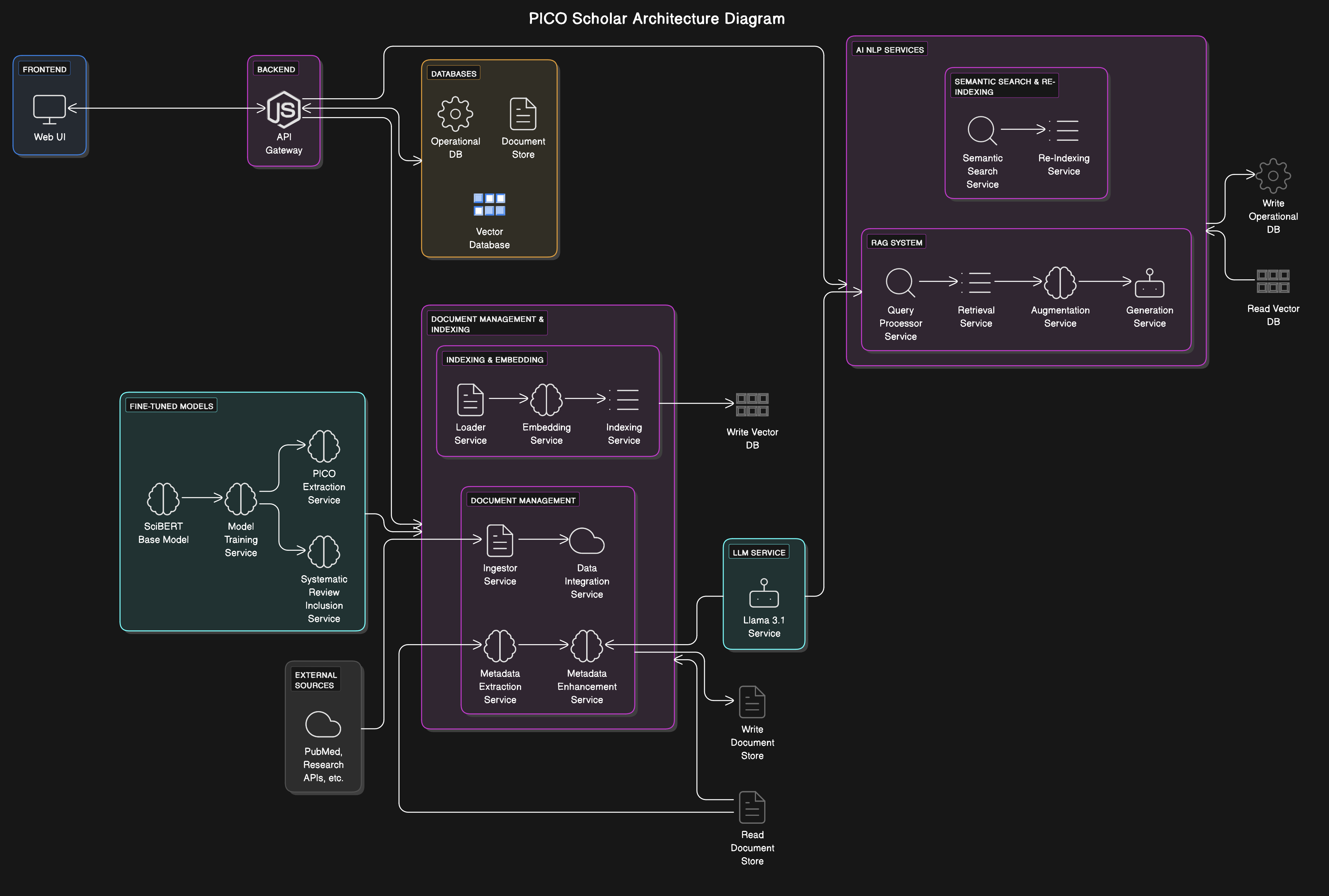
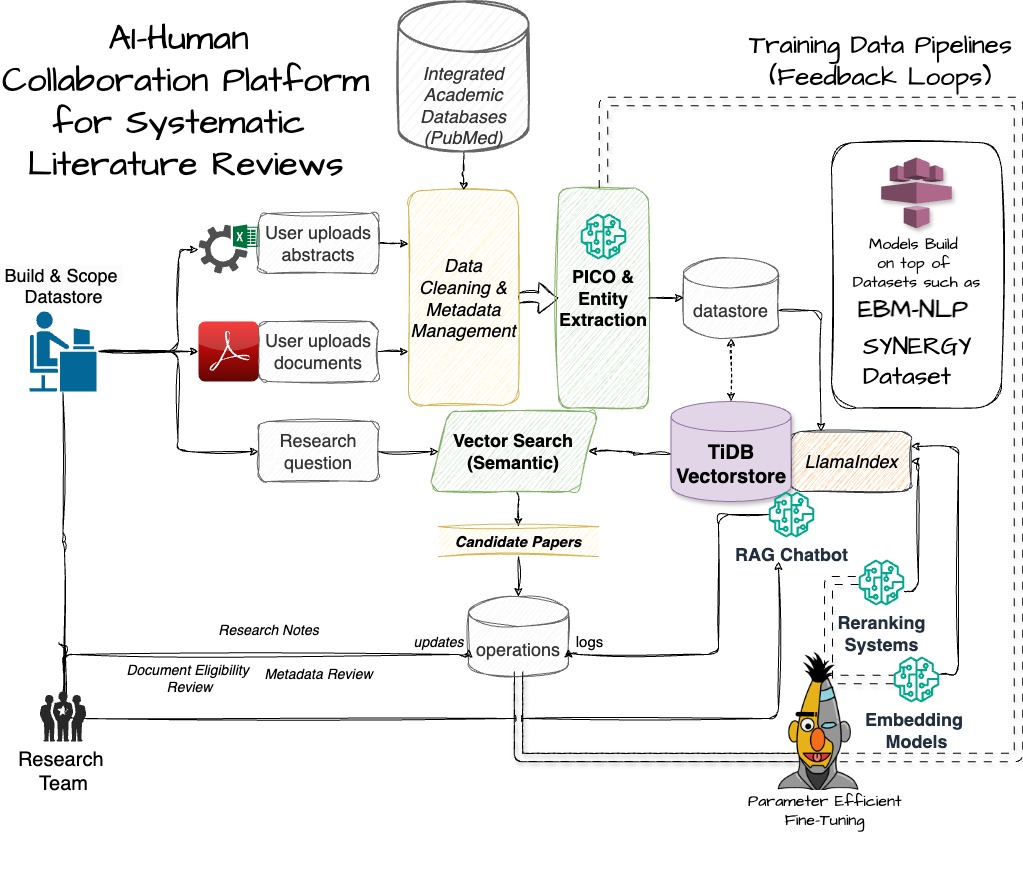
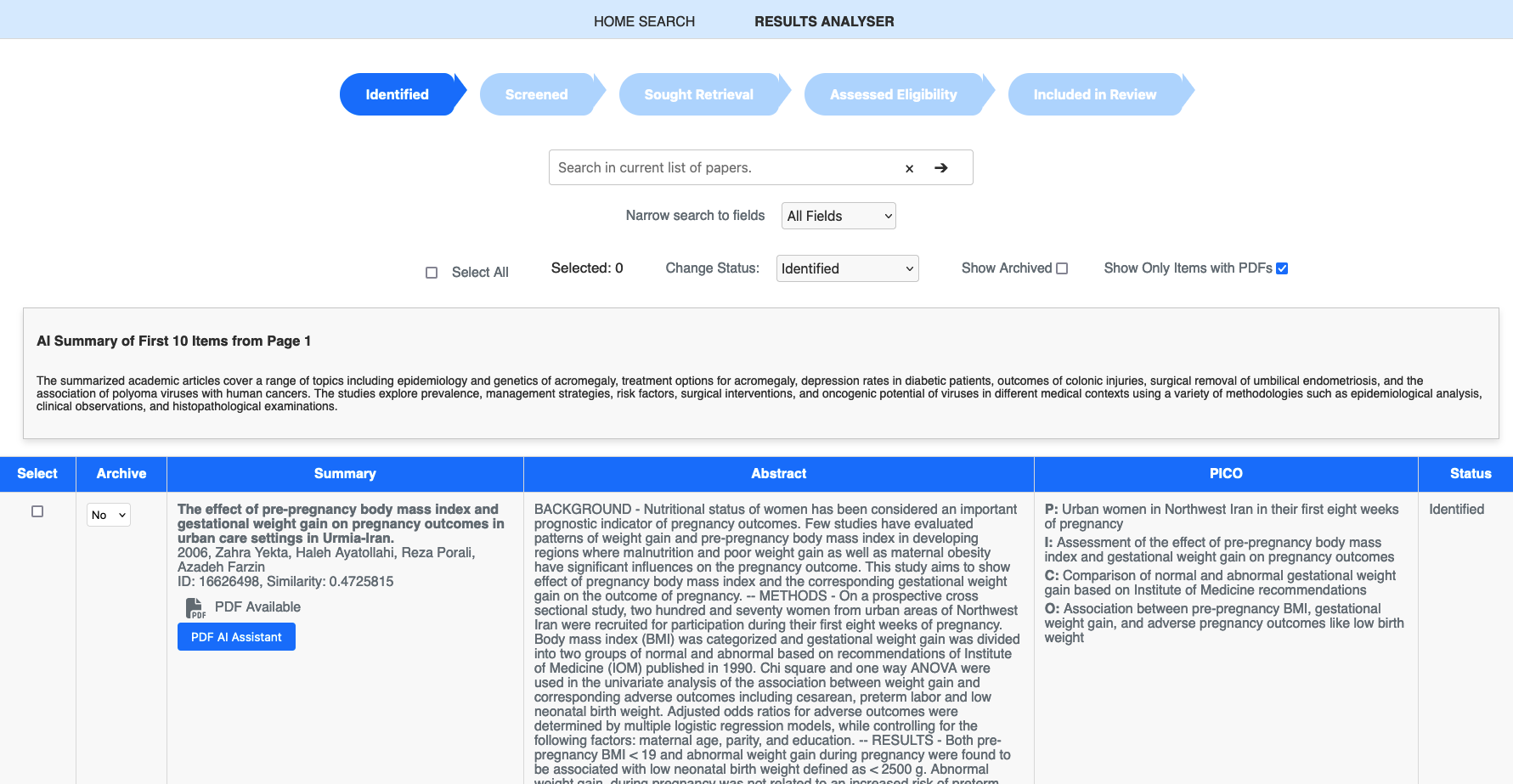
PICO Scholar is an AI-driven platform designed to support researchers conducting systematic literature reviews. It enables users to input research queries, which are transformed into embeddings and matched against a semantic vector database. PICO Scholar extracts key elements (Population, Intervention, Comparison, Outcome) from research documents, ranks relevant studies, and provides a RAG-powered chatbot for in-depth document exploration. The platform also supports real-time collaboration, allowing teams to refine and review literature more effectively.
How we built it
We built PICO Scholar using a microservices architecture on Red Hat OpenShift AI, optimizing our models with Intel’s OpenVINO toolkit. ModelMesh was used to efficiently manage and deploy multiple models, including SciBERT for embeddings and TinyLlama for generation tasks. We used LlamaIndex to load and structure embeddings within a TiDB VectorStore, enabling semantic search across documents. Fine-tuned adapters enhanced our model’s domain-specific accuracy, and MinIO S3 provided seamless access to model storage. Each component was deployed as a separate microservice, allowing for scalable, independent resource management.
Challenges we ran into
Our biggest challenges were managing resource constraints and ensuring compatibility across model formats. Initially, we attempted to deploy large models in OpenVINO’s IR format, but faced issues with serving the TinyLlama-1.1B model this way, leading us to switch to ONNX format for stability. Additionally, balancing memory usage with ModelMesh while supporting high-density model deployment required careful tuning. These challenges provided valuable insights into efficient model serving in cloud environments with limited resources.
Accomplishments that we're proud of
We’re proud to have successfully implemented a scalable, RAG-enabled system optimized for real-time systematic literature reviews. Our use of Red Hat OpenShift AI and Intel’s OpenVINO toolkit resulted in a highly efficient platform that can perform complex retrieval and generation tasks without the need for external GPUs. The integration of ModelMesh for model serving and federated learning for privacy considerations has set a strong foundation for scalable, domain-specific research assistance.
What we learned
This project taught us the importance of choosing the right tools and architectures for scalable AI systems. We gained hands-on experience with OpenShift’s model-serving capabilities, ModelMesh, and Intel’s OpenVINO optimizations. We also learned how to overcome challenges in managing memory and compute resources in a cloud-based environment, developing strategies for dynamic model loading and efficient inference with minimal latency.
What's next for PICO Scholar - RAG Enabled
Our next steps for PICO Scholar include expanding the platform’s capabilities with advanced RAG agents for autonomous fact-checking, implementing enhanced retrieval systems, and integrating privacy-preserving AI through federated learning. We also plan to introduce multi-user collaboration features to support larger research teams, making systematic reviews more efficient and accessible across diverse fields of study.
Built With
- docker
- fastapi
- intel-xeon
- javascript
- llamaindex
- minio
- modelmesh
- openshift
- python
- ract
- rag
- rosa
- tidb










Log in or sign up for Devpost to join the conversation.