-

picassio logo
-
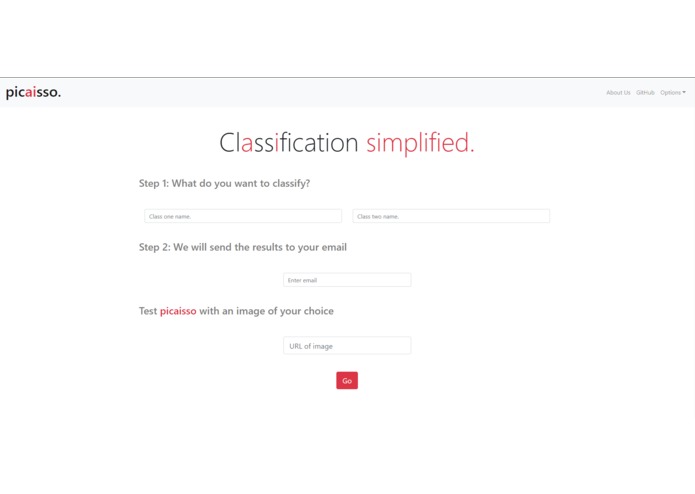
static webpage

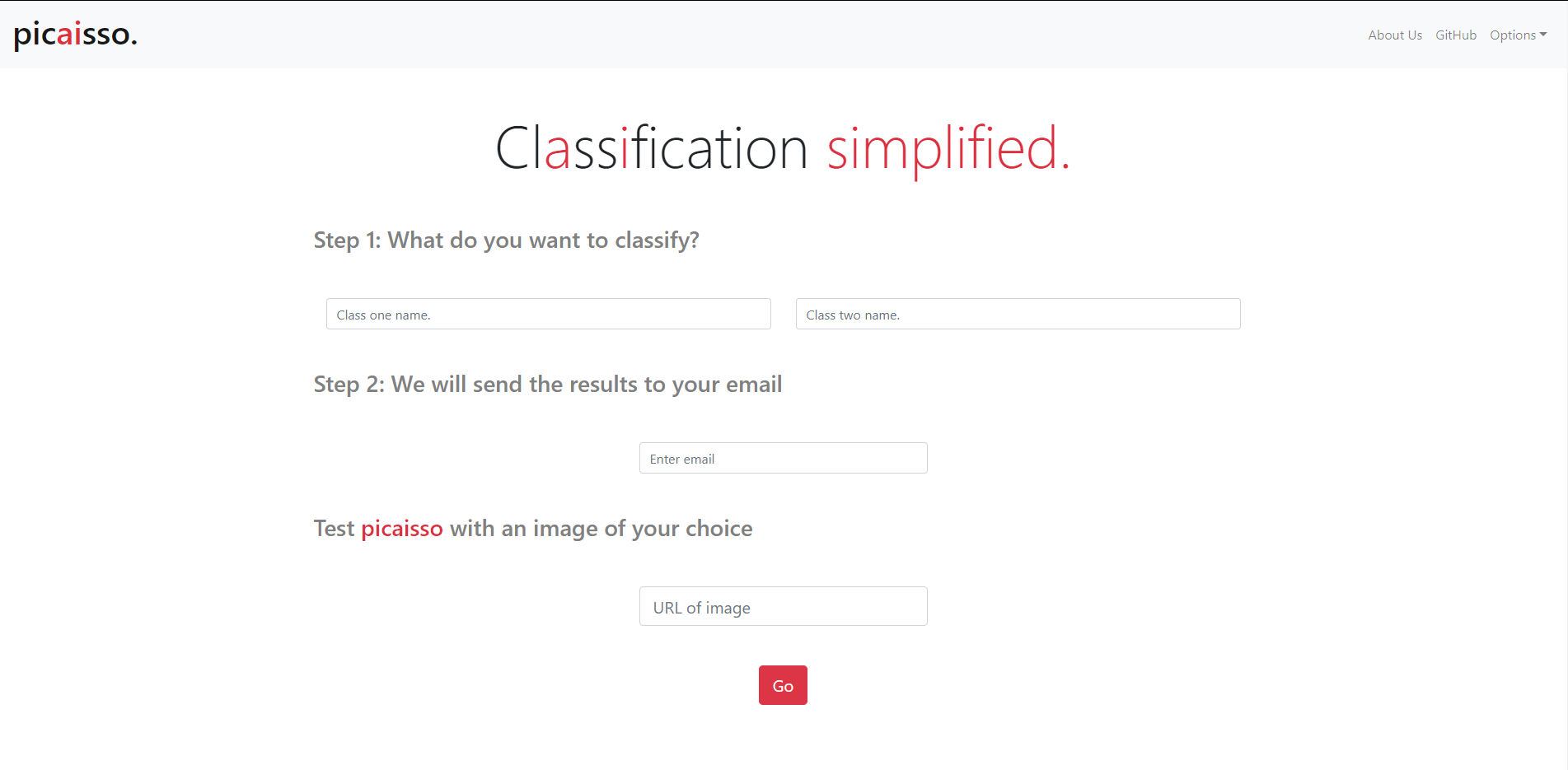
picaisso.
Two central problems in AI are 1) the lack of scalable datasets, and 2) the sheer amount of knowledge and resources someone needs to build a model. Picaisso targets these problems simultaneously by taking care of dataset collection and model training for you. Picaisso will compute a suitable dataset to train a general-purpose deep-learning classifier for any two classes you want. Better yet, Picaisso will provide you with the dataset of images from the two classes as well as the classifier itself. We automate everything; it's as simple as typing the classes you want to distinguish between. Classification simplified.
Stack
- React
- Express.js
- Node.js
- Python
- Flask
- Selenium
- PyTorch
- Google Compute Engine
- MySQL
Requirements
Because this project relies on ChromeDriver, you must have Chrome v77 installed in the default location on your machine. To run the picaisso-scraper-service, you also need Python 3.7. To run the React app, requires Node. To run the picaisso-model-service, because it's a local mock of the actual service running in the cloud, you'll need a pre-computed model file in the form of a .pt file in the root of the service in order for model.py to properly work. (These files have been excluded from the repo because they are too large.)
Setup
Navigate to picaisso-app-service/react-front and run npm install, then run npm start to start the React app.
Navigate to picaisso-scraper-service and run app.py to start up the Flask service. It will listen for incoming REST API calls.
Navigate to picaisso-model-service and run model.py to start up a Flask mini-service that mocks the actual model service that's in the Google Compute Engine cloud. You'll need a pre-computed .pt file placed in the root directory of this service (not included in the repo due to size) in order for the mock to work.
Project Overview
This repo contains three directories corresponding to the three services of picaisso.
The picaisso-app-service directory contains the code for the client-facing web application. It has a front-end built in React with a backend in Express.js and Node.js. Because the Node server runs locally, you would need some other third-party service to open it up to the general web (we've been using ngrok).
The picaisso-scraper-service is a RESTful Flask service that handles the web scraping of images to build the dataset. Its primary point of entry is the /picassio endpoint, which is reached by the picaisso-app-service whenever a user submits a new request. Upon making a POST request to the /picassio endpoint, the picassio-scraper-service runs through a workflow that scrapes images to build the dataset, posts the URLs to an external MySQL database, makes other requests to inform the picaisso-model-service when to fetch data and begin learning, then emails the zipped dataset and model to the user once both have finished compiling. To start up the service, navigate to the root directory and run app.py.
The picaisso-model-service is a local version of the model learning service running on Google Cloud's Compute Engine. We use the PyTorch deep learning framework to classify images. We can easily extend our DL backend to classify any number of image classes. As for the specific model architecture, we use PyTorch's ResNet50 architecture pretrained on the 1000 class ImageNet dataset, which is an industry-standard for classification. This service is split into two modes: train and inference. For training, we found that models typically converge within 100 epochs, which takes about 30 minutes to finish. The model file is provided to the user as a set of ResNet50 weights. To instantiate the model on another machine, follow the examples in the inference code. Our inference mode can be run on GPU or CPU (memory permitting), and requires a single image url, which the model will classify.
Story
Our idea came from Sai -- the one with the most ML/DL background among us -- and we drew inspiration from his frustrations with finding and (often manually) collecting good datasets for building models. We wanted to explore whether we could automate the process -- providing accurate, plug-and-play models, as well as an entire dataset of two classes for classification purposes, all through a simple, scalable service. We decided that picaisso was the best way to combine all of our skills and experience to build a web app/service that aimed to reduce the friction in collecting data and building a general model for classifying between two (or more) classes of objects.
This was an ambitious project. As we were exploring possible architectures for our service, we bounced between a single fullstack service to a completely distributed and containerized cloud cluster, with each container running one of our three services. Ultimately, our end-goal production architecture was to have our MERN stack hosted somewhere (e.g. heroku) to supply our static web page, where user inputs would then call our various backend services, which would be deployed dynamically on the GCP platform either via a Kubernetes cluster (each service in its own Docker container) or through some other native GCP dynamic deployment feature. In the end, because the DevOps was secondary to actually getting our services to work, we didn't have much time to revisit these ideas and we opted instead to just host our services locally for our MVP.
We encountered many unexpected difficulties along the way, including significant difficulties with overcoming Google's limit on search queries (as it turns out, going directly through Google's API limits you to 100 results per query, which is far too little when we're trying to aggregate hundreds or even thousands of images!), so we hacked together a web scraper that leveraged a headless Chrome driver via Selenium to scroll through the constantly-loading Google Images page until it bottomed out or reached the maximum limit of images we wanted to display. We also ran into some difficulties with fitting our model to the varying amounts of images that our datasets comprised, and we experimented with varying the number of epochs to data augmentation try and get the best fit with the data that we had. Finally, we drastically underestimated the DevOps part of the project -- organizing how all of the different services' endpoints and requests would interact with each other was a huge headache, and cost us a lot of debugging time in the last stretch of the event.
Overall, though, we're very excited to present our MVP of picaisso. We all learned a lot -- this is our first time using the Google Cloud Platform, as well as web scraping with Selenium, as well as building a fullstack MERN app -- and we're very happy with what we were able to come up with in such a short amount of time. We hope that you enjoy picaisso as much as we did making it!
Overall



Log in or sign up for Devpost to join the conversation.