-
-
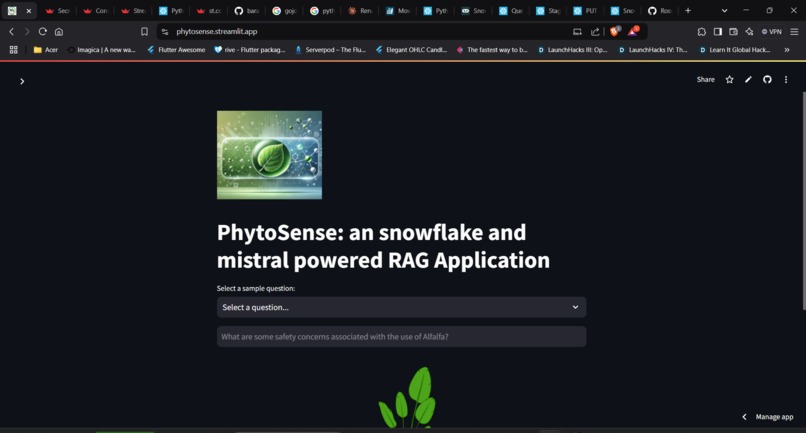
Landing Page
-
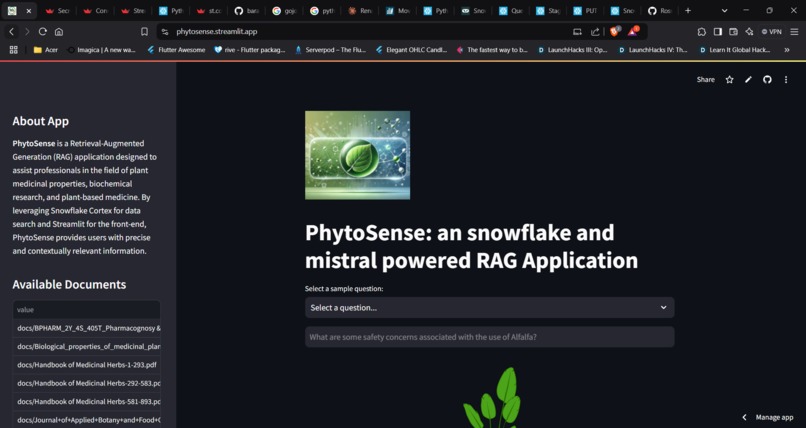
sidebar to select context checkbox
-
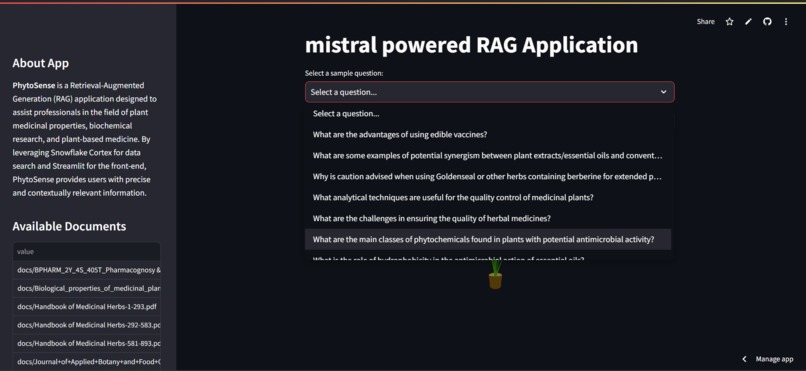
select sample question or give your own
-

get the chunks and result




Inspiration
PhytoSense was inspired by the need to bridge the gap between vast amounts of plant-based research data and the professionals who can leverage this information for medicinal and biochemical advancements. The potential of plants in medicine is immense, yet accessing and processing this information efficiently remains a challenge. Our application aims to simplify this process, empowering researchers and professionals in the field.
What it does
PhytoSense is a robust Retrieval-Augmented Generation (RAG) application that provides precise and contextually relevant information to users in the domain of plant medicinal properties and biochemical research. By leveraging Snowflake Cortex for data search and Streamlit for an interactive front-end, PhytoSense delivers an intuitive experience for querying and exploring plant-based data.
How we built it
The application is built on top of Snowflake Cortex, which serves as the backbone for our data search capabilities. We use Streamlit to create a user-friendly interface that allows professionals to input queries and receive detailed responses based on the context of the data. This combination of technologies ensures that users have access to accurate information.
Challenges we ran into
One of the main challenges was ensuring that the data retrieval process was both fast and accurate, given the vast amount of information available. Additionally, designing an interface that is both intuitive and informative required careful consideration of user experience principles.
Accomplishments that we're proud of
We are particularly proud of our application's ability to provide concise and relevant answers to complex queries. The integration of Snowflake Cortex and Streamlit has resulted in a seamless user experience that meets the specific needs of professionals in the plant research domain. Additionally, we successfully deployed the application outside the Snowflake environment using Streamlit Community Cloud. By leveraging APIs, we can connect and execute Snowflake queries efficiently, making the application accessible and functional in a broader context.
What we learned
Throughout the development of PhytoSense, we learned the importance of combining powerful backend technologies with a user-centric design approach. The project reinforced our understanding of the challenges faced by researchers in accessing and utilizing large datasets effectively. Additionally, we discovered that Snowflake's built-in methods significantly simplify the process by handling embedding, indexing, and reranking automatically. This feature allowed us to focus more on the application's functionality and user experience, rather than the complexities of data processing.
What's next for PhytoSense
Looking ahead, we plan to expand PhytoSense's capabilities by incorporating more data sources and enhancing the application's natural language processing features. We aim to make PhytoSense an indispensable tool for researchers and professionals in the field of plant-based medicine and biochemistry. Furthermore, we are planning to evolve PhytoSense into an agentic RAG application capable of performing cross-analysis and reasoning. This will enable the generation of insightful leads and deeper understanding for researchers, further enhancing the value PhytoSense provides to the scientific community.
Built With
- ai
- langchain
- llm
- mistral-large2
- python
- snowflake
- snowparkapi
- streamlit

Log in or sign up for Devpost to join the conversation.