-
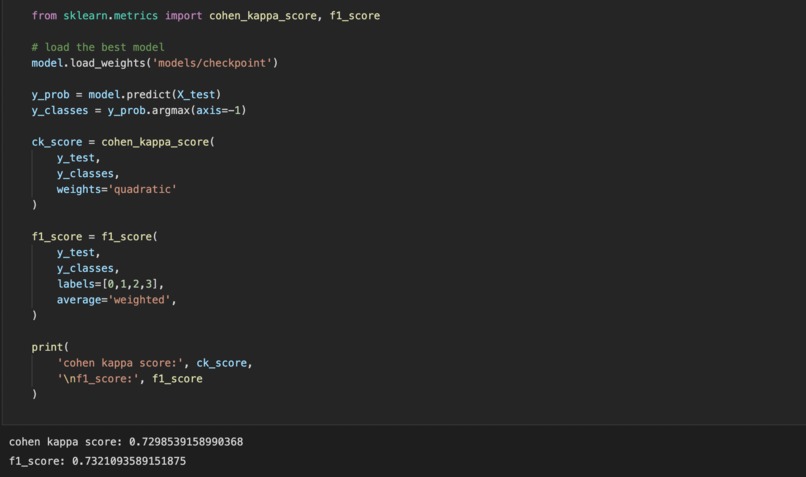
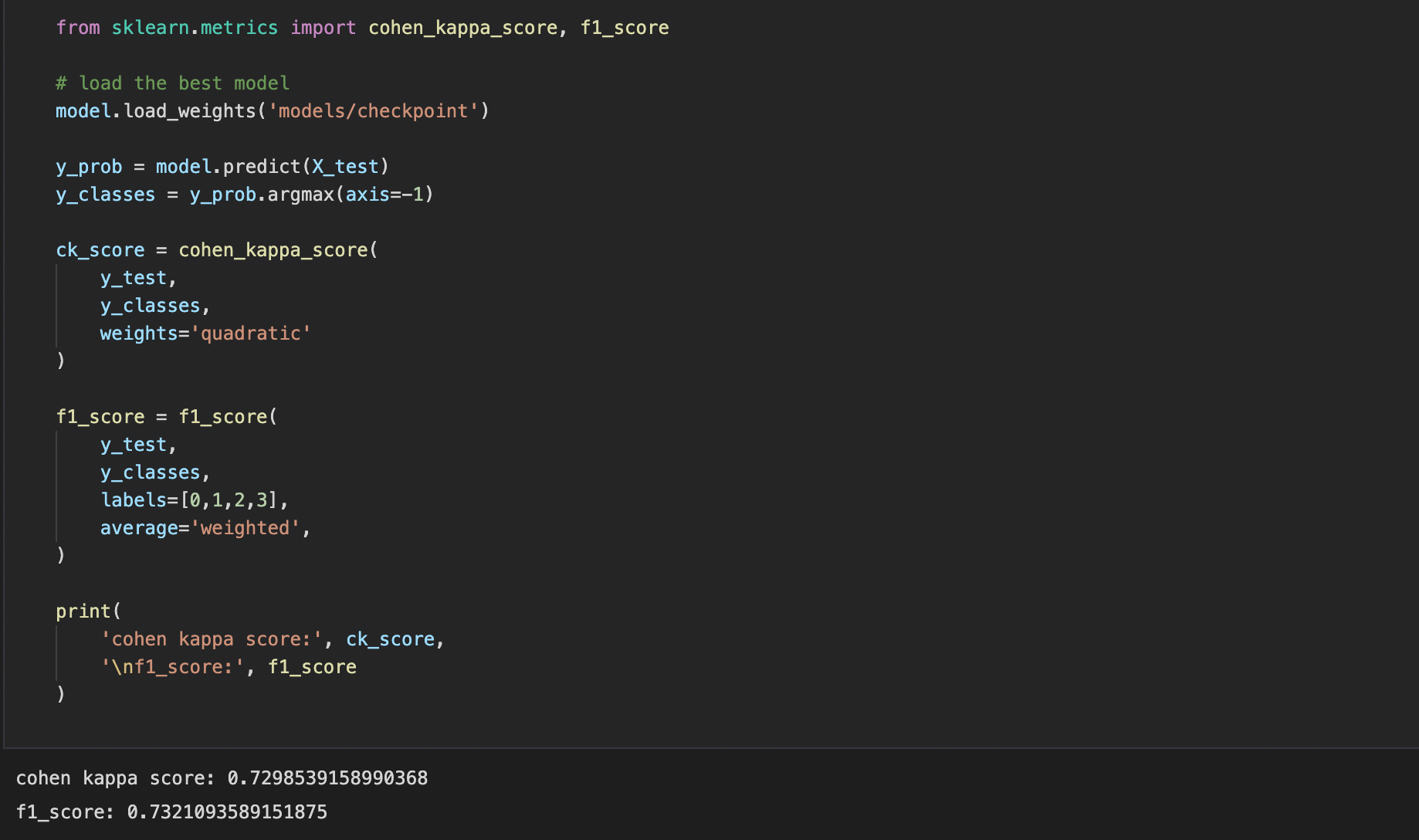
Cohen Kappa Score & F1 Score
-
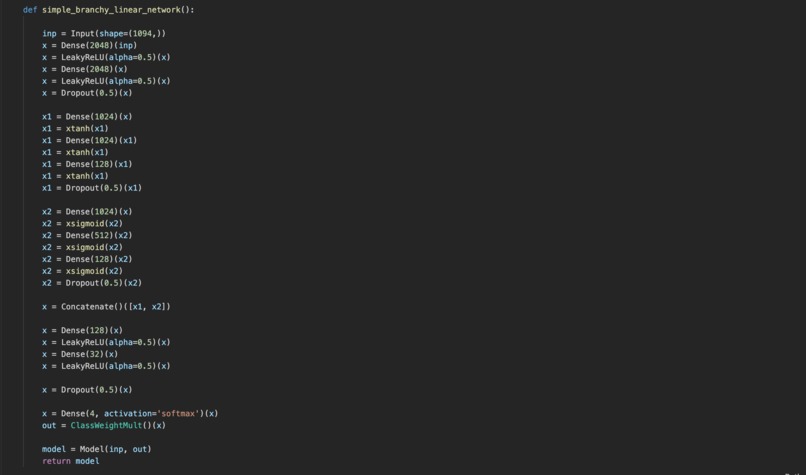
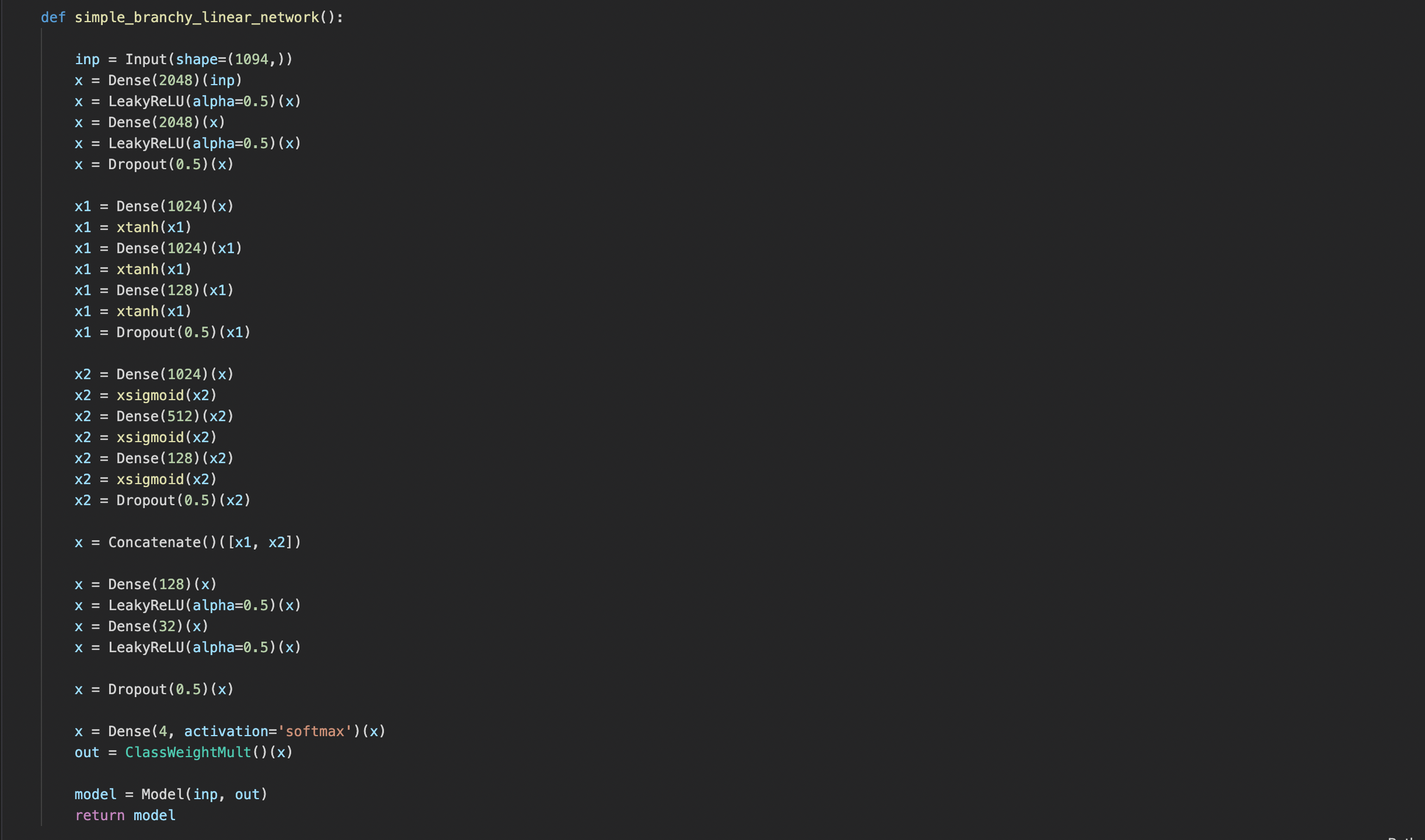
The best working model
-
Running the code (main.py)
Inspiration
Every human gut has a microbiome which contains trillions of microorganisms. This microbiome can influence physical health, but also mental health. To prevent the development of these diseases building up in the future, and to help researchers accurately identify whether a patient is healthy or not in a short amount of time is very important. Using a neural network based classification system, we are able determine whether an individual has diseases like inflammatory bowel disease, depression, colorectal cancer, and Parkinson’s disease within seconds given the bacteria count.
We want to make people's gut health a priority and reduce the spread of these diseases!
What it does
We take in the bacteria count for about 1094 different bacteria. Based on this information, we pass it through our advanced and complex neural networks to come up with a prediction about what type of disease is within this persons gut OR if the individual is healthy. Currently we have the model prepared with Cohen Kappa scores and F1 scores of greater than 0.7 and accuracies of more than 80%. Which is a massive improvement from the previous 25% accuracy.
How we built it
Using Tensorflow, Keras API, Scikit-learn, pandas, and numpy, we were able to create a library of different multi class classification networks. By first processing the data with pandas, we were able to normalize the data by subtracting the mean and dividing by the standard deviation. After each column was individually normalized, we adjusted for the outliers (values < -5 or > 5). Using scikit-learn's train_test_split, we were able to separate the predictors and the labels and begin developing a model. Going through many different types of neural network models, branching networking models, support vector machines, k-nearest-neighbors algorithm, and decision trees, we were finally left with the best model. The simple branching network model. Over many trail and errors processes, we were finally able to build a model with a high degree of accuracy.
Challenges we ran into
There were many challenges:
- Normalizing the data and removing the outliers.
- What type of model to use to produce the best Cohen kappa score and F1 score.
- Optimizing the neural network for the best Cohen kappa score and F1 score.
- Dealing with imbalanced dataset
Accomplishments that we are proud of
We are very proud that we were able to develop a model with an accuracy of over 80% and producing a Cohen Kappa Score and F1 Score of over 0.7. Especially considering the fact that we created the model from scratch, and optimized the model to produce the best possible accuracy.
What we learned
We learned so much throughout this process. Most specially dealing with imbalanced datasets. We were able to create a custom layer at the very end that applies the class weights specially onto the the end of the neural network. This drastically improved the accuracy of my network and taught me so much. We learned a lot about how useful and powerful scikit-learn truly is with all of their models, such as Decision trees, KNN, and Support Vector Machines
What's next for Phyla Multiclass Classification - Rayaq Siddiqui
Moving forward, we would like to build a website with this machine learning model. We would build a Django backend in the native language of Tensorflow, Python. And then build out a frontend architecture, either in Flutter or the MERN stack. We would combine the backend and frontend using the Django Rest API and allow users to type in the quantity of certain amount of bacteria in their gut and we would make a prediction to what type of disease they have or if they are healthy.
Built With
- keras
- matplotlib
- numpy
- pandas
- python
- scikit-learn
- tensorflow


Log in or sign up for Devpost to join the conversation.