-
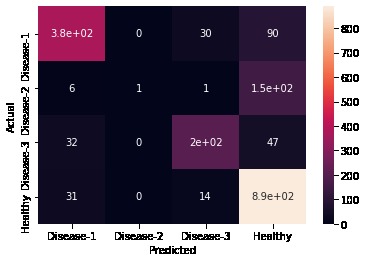
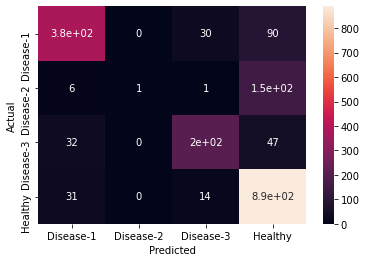
Confusion matrix' heatmap
Performance
- F1 Score - Micro: 0.780331373597007
- F1 Score - Macro: 0.5981815091402464
- F1 Score - Weighted: 0.7443181899051569
- Cohen’s kappa score: 0.6355790715803891
Inspiration
Alexis Nolin-Lapalme's intro to Machine Learning
One of the biggest problems in machine learning is overfitting, but most of the time this won’t happen thanks to the random forest classifier. If there are enough trees in the forest, the classifier won’t overfit the model.
Source: https://builtin.com/data-science/random-forest-algorithm
[...] the Random Forest (RF) algorithm showed superior accuracy comparatively. Of the 17 studies where it was applied, RF showed the highest accuracy in 9 of them, i.e., 53%.
Source: https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-019-1004-8
What it does
Classify different diseases using a multi-label classification model based on the microorganisms in the gut microbiome.
How we built it
- Python
scikit-learn- Machine Learningseaborn- Heatmapspandas- Data Analysis
Challenges we ran into
- Separating 'Disease-2' from 'Healthy' samples
Accomplishments that we're proud of
- Built a functional classifier with minimal code, minimal complexity, minimal performance cost
What we learned
- Random Forest Classifier
- Using
scikit-learnfor Machine Learning
What's next?
- Use
sklearn-onnxto export our model in a standard format - Include potential future q-values -> FDR
- Tuning to separate disease-2 from our healthy samples
Built with
- Python
scikit-learn- Machine Learningseaborn- Heatmapspandas- Data Analysis
Built With
- pandas
- python
- scikit-learn
- seaborn

Log in or sign up for Devpost to join the conversation.