Inspiration
- Screenwriters struggle to hear scripts before production; table reads are expensive and scheduling cast is painful.
- We wanted a 24/7 “audio rehearsal room” where writers can upload a PDF and instantly hear an expressive performance.
What it does
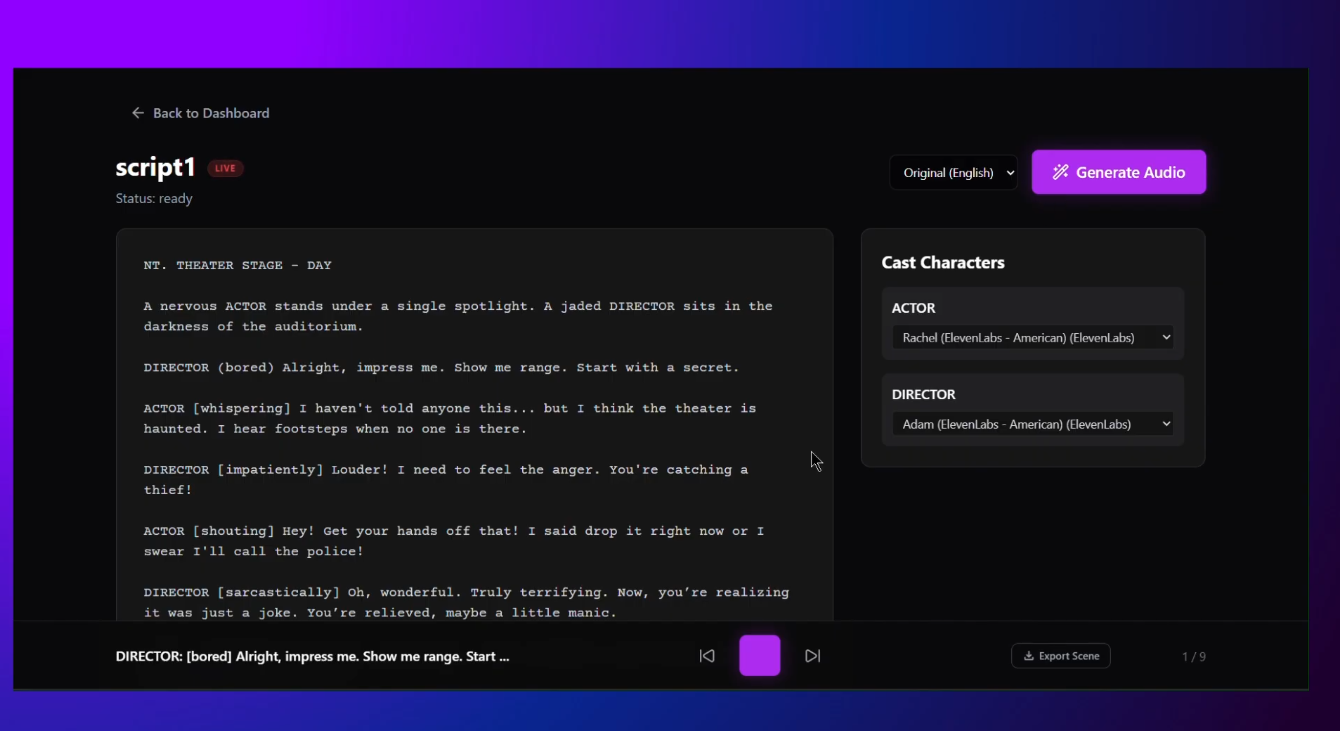
- Parses uploaded screenplays with the AI/ML API, extracting scenes, characters, and dialogue.
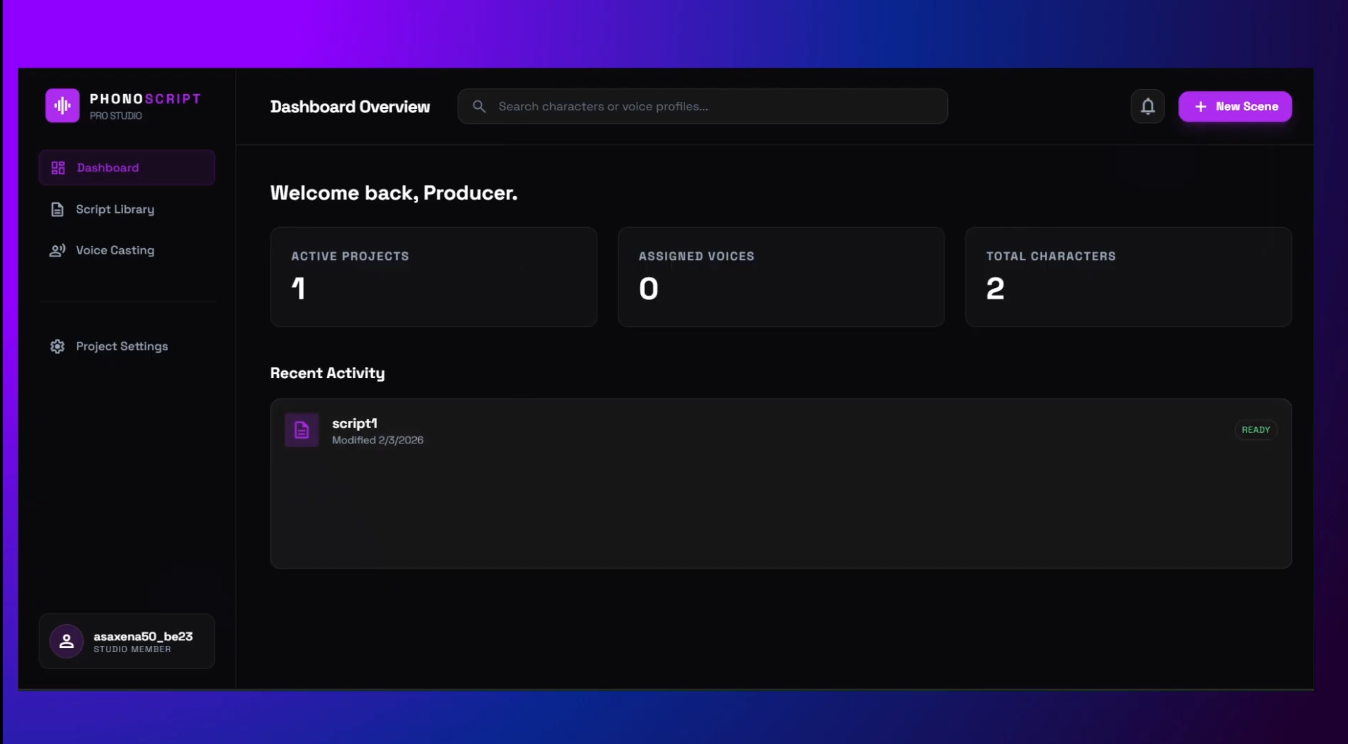
- Lets users cast ElevenLabs voices, generate scene audio, and trigger instant table reads in the dashboard.
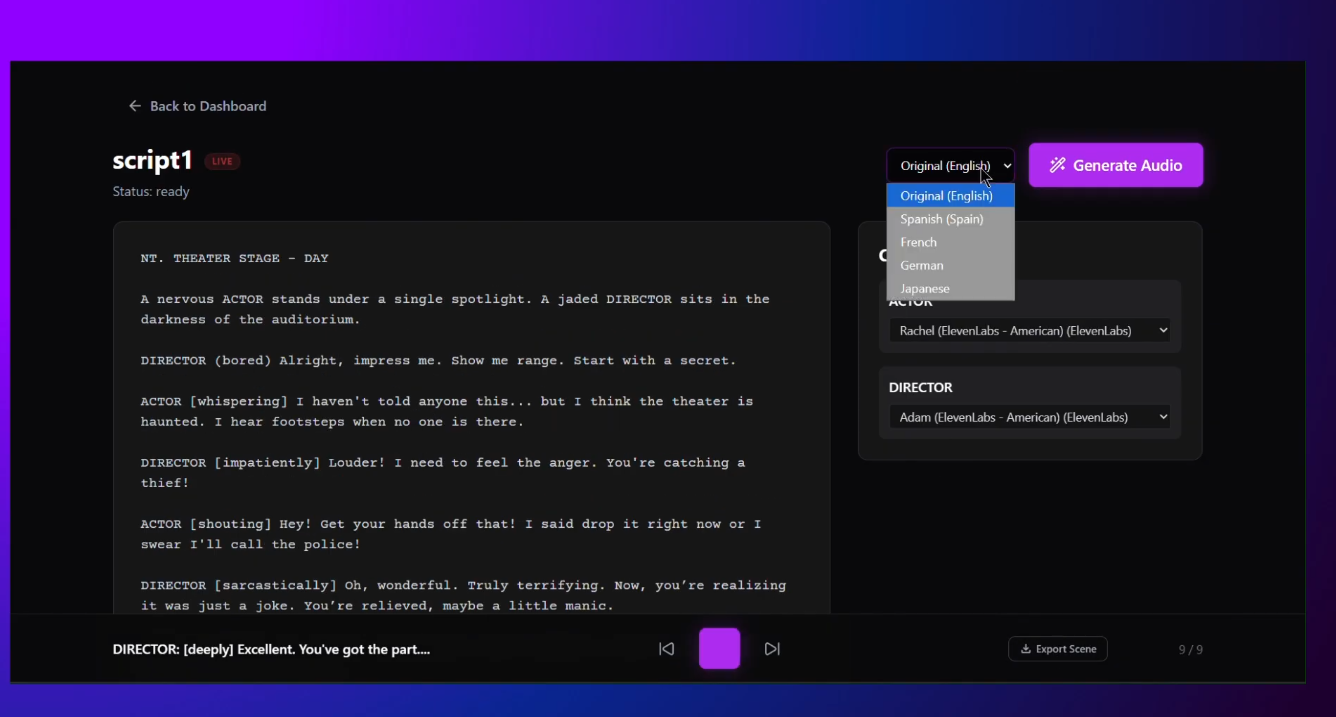
- Supports multilingual dubbing, audio export, and Supabase-backed persistence for collaborative teams.
How we built it
- React + Vite frontend with Tailwind glassmorphism UI and Supabase auth/state.
- Hono edge backend on Vercel that calls the AI/ML API for script parsing and ElevenLabs for TTS via fetch-compatible handlers.
- Supabase Postgres + storage for script assets, characters, and metadata.
Challenges we ran into
- Making ElevenLabs calls Edge-compatible (axios was unsupported; we rewrote with native fetch + Uint8Array handling).
- Keeping large text parsing fast while staying within AI/ML API context limits.
Accomplishments that we're proud of
- Fully automated, voice-casted table reads that sound production ready.
- Clean separation between parsing, storage, and playback that scales for multiple users.
- Polished landing/dashboard experience that demos the product without manual setup.
What we learned
- Edge runtimes demand fetch-native integrations; legacy Node clients often fail.
- Prompt engineering for screenplay structure requires tight JSON schemas and defensive parsing.
- Supabase storage + database combo is a strong fit for media-heavy Next/Vite apps.
What's next
- Add real-time co-writing with synchronized playback and commenting.
- Introduce emotion-aware fine-tuning for ElevenLabs voices per character arcs.
- Roll out pricing tiers with usage analytics and self-serve billing.
Log in or sign up for Devpost to join the conversation.