-
-
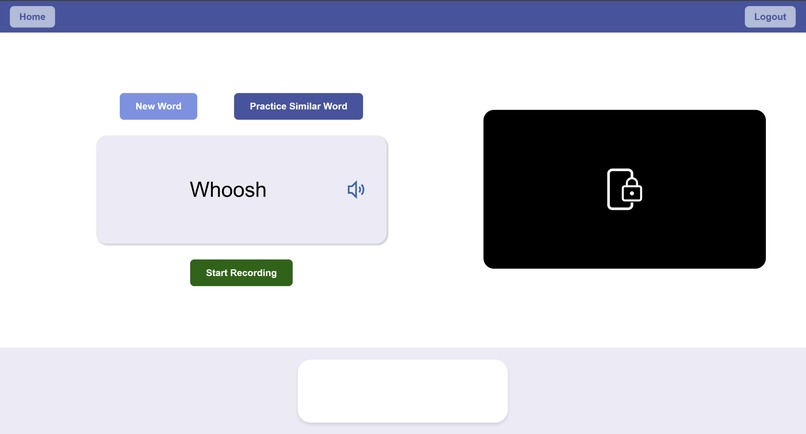
Speech Practice Dashboard
-


Inspiration
Worldwide, approximately one in four individuals over the age of 25 will experience a stroke in their lifetime, with an estimated 12.2 million people affected annually. Stroke remains a leading cause of disability across the globe, and this issue hits closer to home than we might realize. In fact, recently, a mentor and friend of mine suffered a stroke, resulting in Broca’s aphasia, a form of language impairment where speech production is severely impaired, while comprehension remains largely intact, due to damage in the brain. Broca’s aphasia heavily affects both stroke patients and the elderly in general, as cognitive decline progresses, presenting as an extremely difficult situation to navigate for both the patient and their loved ones.
As a result, many patients that experience aphasia undergo speech therapy in order to regain their cognitive abilities and improve the situation, but several issues manifest. Firstly, speech therapy is costly, with different providers and forms of therapy averaging at almost $200 per session, and this cost is exacerbated by the need for ongoing treatment. Additionally, accessibility may be hindered by the difficulty or inability to see a therapist on a daily basis.
Inspired by the personal and statistical impacts of Broca's aphasia, we thought about what we could do to resolve these issues, with a goal to prioritize the user’s experience in terms of accessibility, effectiveness, and personalization. Our solution is an AI-powered speech therapy web app designed to meet all of the goals mentioned above. It serves both healthcare and educational purposes, targeting stroke patients, the elderly, individuals with language difficulties, and students learning English as a second language.
Our solution
Phonix, our speech therapy web-app, generates personalized practice using generative AI, gives appropriate feedback using computer vision, and incorporates natural language processing through automatic speech recognition, allowing the user to practice and improve their condition from the comfort of their own homes. We created an easy-to-navigate UI with a personalized stats tracker of the pronunciations that the user excels at and those that the user needs more practice on. Additionally, Phonix effectively identifies the user’s weak points (e.g. words or specific phonemes that require more practice for better precision), and analyzes both the user’s speech (via audio recording) and facial movements (via landmark detection on user's live camera feed) in order to provide personalized feedback according to the audio and lip analyses. In addition to feedback, our speech therapy web-app also generates personalized practice according to the user’s weak points, accurately imitating a real-life speech therapist, but with more efficiency and accessibility, with goals of reaching a wider audience. In order to make our web-app more engaging, holistic, and as realistic as possible, we also incorporated varying difficulties of practice terms for the user’s therapy experience, including a vast selection of both words and sentences.
How we built it
The integration of OpenCV, Dlib, OpenAI's WhisperAI and GPT-4o-mini API, and ElevenLabs API forms a crucial foundation for our project. We utilize SQLite to store initial word and sentence data generated by RandomWordAPI Vercel and OpenAI’s API, respectively. This data is then displayed on our user interface, and the user’s pronunciation of the text is recorded. WhisperAI is employed to transcribe the audio into text, which is then compared to the expected text from the database. To enhance accuracy, we employ the english_to_ipa module to convert both the spoken and expected English text into the International Phonetic Alphabet (IPA). This enables us to precisely isolate each syllable and assess discrepancies between the expected phonetic transcription and the user’s pronunciation.
Upon identifying the mispronunciation, the particular word and syllable are passed to the OpenAI's GPT-4o-mini API call, which generates a phonetically similar word specifically tailored to the user’s particular mispronunciation. Concurrently, WhisperAI processes the user's audio file through the Open Source Allosaurus function to generate a series of timestamps corresponding to the pronounced phonemes. By identifying the mispronounced phoneme and its timestamp, we match this with the corresponding frame in the OpenCV feed, capturing the precise moment the phoneme was articulated.
Using Dlib’s facial landmark detection capabilities, we extract the user’s mouth positioning and compare it to a pre-labeled database of accurate mouth positions for each IPA phoneme. The system computes differences in the relative dimensional ratios to assess pronunciation accuracy, and personalized feedback is then provided based on these findings. This feedback is then coupled with ElevenLabs API’s text-to-speech functionality, allowing the user to hear the correct pronunciation, which is essential for improving performance. Furthermore, OpenAI’s API is invoked to provide a comprehensive response based on the user’s audio input as an additional layer of specific feedback that would be helpful to the user.
Challenges we ran into
The execution of this project proved to be a challenge, especially with regards to the integration and alignment of audio and visual components. Specifically, we realized that aligning the timestamps of the audio file to the specific phoneme, which also had to be matched to the correct corresponding frame of the video, was a critical issue. As a result, we learned varying methods to combine both components, using language-dependent models of phoneme identification through an encoder and an allophone layer via Allosaurus, to align audio and video.
Additionally, coming up with personalized feedback according to the user’s lip positioning was another challenge because it was difficult to determine what information we could extract from still frames. Therefore, in order to resolve this issue, we found a library of accurate or expected lip positions, and placed the images into a database labeled in IPA. Then, we used the ratios of lip dimensions using feature landmark detection in order to compare phonemes, and analyzed what each of the potential combinations of ratios implied in order to provide personalized and accurate feedback.
Furthermore, the integration between frontend and backend was a challenge due to our many separate components–audio, visual, API calls, database, and facial analysis, as well as JavaScript UI. Therefore, we used React and Flask to facilitate the interconnection between each component in order to put together a pipeline for efficient data exchange and program composition.
Accomplishments that we're proud of TreeHacks 2025 was the first time participating in a hackathon for each of us, so we ultimately felt as though we learned a lot through hands-on experience and turned out to be an enriching and positive learning experience. In addition to learning computer programming-based skills, we also honed our collaboration and refined our ideation-execution abilities, all while having fun. We are delighted that we successfully completed this project within a limited amount of time, and ultimately were able to integrate all components even though we each focused on separate parts.
What we learned
The process of developing Phonix was a valuable learning experience for all of us, from expanding our technical expertise to growing together as a team.
To build the frontend of Phonix, we learned to use Javascript, React, and CSS. We developed our backend using Python, through which we learned to research and adopt modules such as allosaurus and english_to_ipa and the power of open-source. We also learned to integrate Python functions with Javascript server using Flask, make and manage API calls including GPT 4o-mini and WhisperAI, construct databases using SQLite, and detect facial landmarks using computer vision with OpenCV and dlib. We also learned how to build our own dataset for use in computer vision and image analysis.
This project was also a meaningful opportunity in immersing ourselves in the holistic engineering process from start to finish. From ideating to researching to designing to programming to assembling Phonix, we learned the importance of flexibility, communication, and persistence in building a product from scratch in such a short time period. We found that frequent check-ins and updates are crucial in maintaining transparency on our project progress, especially because we chose to delegate the various components (frontend, audio processing, visual processing, etc.) to our team members. We also discovered that integrating these separate components can prove challenging, so communication and thorough planning is extremely important.
Lastly, we learned that a hackathon is a great deal of fun and learning and greatly appreciated this opportunity!
What's next for Phonix
Our hope for Phonix is to achieve widespread implementation, which can be achieved through collaboration with speech therapy programs, healthcare providers, and educational institutions as an accessible form of treatment or learning resource. By reaching a global audience, we will be able to drive meaningful impact via enhanced rehabilitation outcomes. The creation and implementation of Phonix will improve the recovery journey for millions of stroke patients per year, while facilitating more accessibility and personalization for a holistic experience; the product may also be applied for educational purposes and aid in the language-learning process. Our wish is for our product to live up to its name, using phonetics to assist users in regaining their speech skills, much like the rebirth of a phoenix.

Log in or sign up for Devpost to join the conversation.